「教学」异步 SRAM 时序¶
背景¶
在一些场合里,我们会使用异步的(即没有时钟信号的)外部 SRAM 来存储数据,而我们经常使用的很多外部接口都是同步接口(即有时钟信号的接口),比如 SPI 和 I2C 等等,UART 虽然是异步,但是它速度很低,不怎么需要考虑时序的问题。所以在 FPGA 上编写一个正确的异步 SRAM 控制器是具有一定的挑战的。
寄存器时序¶
考虑到读者可能已经不记得寄存器的时序了,这里首先来复习一下 setup 和 hold 的概念。如果你已经比较熟悉了,可以直接阅读下一节。
寄存器在时钟的上升沿(下图的 a)进行采样,为了保证采样的稳定性,输入引脚 D 需要在时钟上升沿之前 \(t_{su}\) 的时刻(下图的 b)到时钟上升沿之后 \(t_h\) 的时刻(下图的 c)保持稳定,输出引脚 Q 会在时钟上升沿之后 \(t_{cko}\) 的时刻(下图的 d)变化:
接口¶
首先我们来看看异步 SRAM 的接口。下文中,采用 IS61WV102416BLL-10TLI 和 AS7C34098A-10TCN 作为例子:

可以看到,它有 20 位的地址,16 位的数据,若干个控制信号,同时只能进行读或者写(简称 1RW)。它没有时钟信号,所以是异步 SRAM。
时序¶
对于一个同步接口,我们通常只需要给一个满足时钟周期的时钟,然后通过约束文件保证 setup 和 hold 条件满足即可。但是对于异步接口,由于输出的时候没有时钟,我们需要更小心地完成这件事情。
读时序¶
首先来看一下比较简单的读时序:
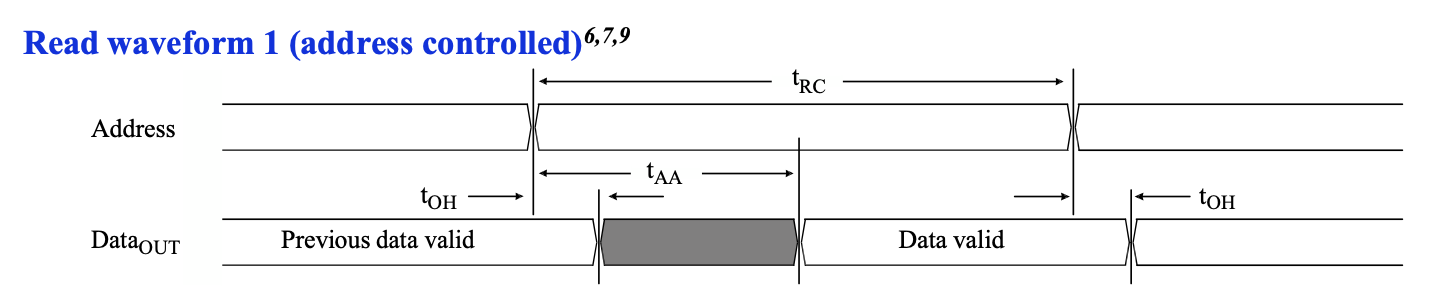
可以看到地址和数据的关系:首先是地址需要稳定 \(t_{RC}\) 的时间,那么数据合法的范围是地址稳定的初始时刻加上 \(t_{AA}\),到地址稳定的结束时刻加上 \(t_{OH}\)。我们再来看一下这几个时间的范围:
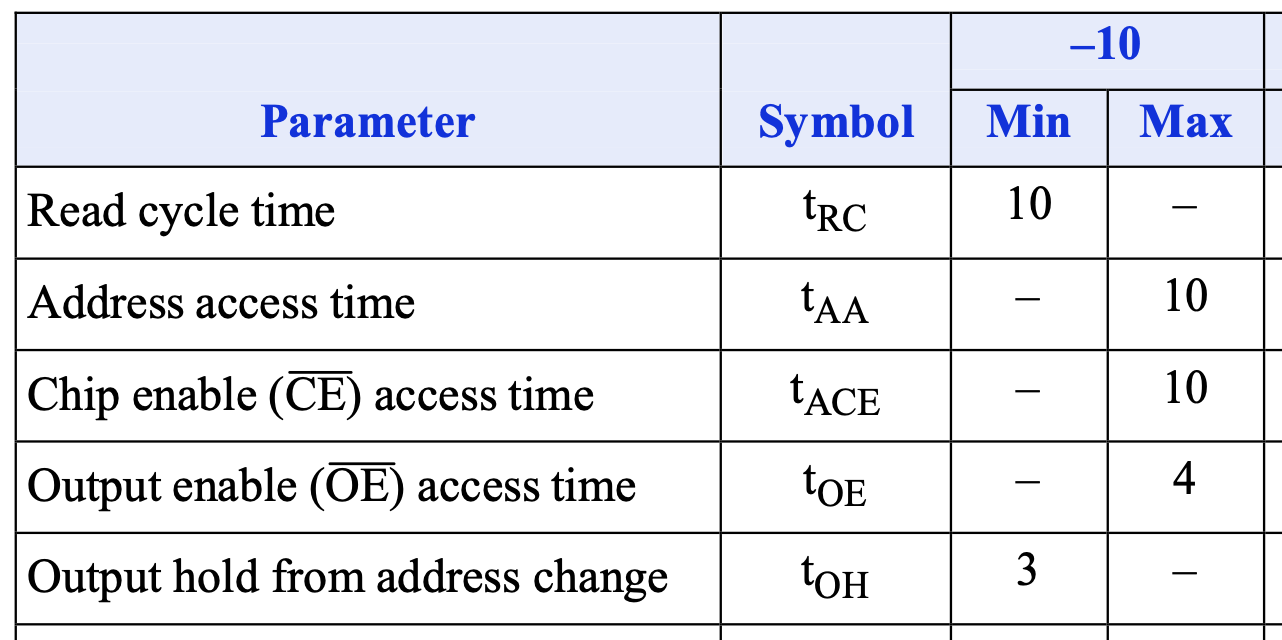
首先可以看到读周期时间 \(t_{RC}\) 至少是 10ns,这对应了型号中最后的数字,这表示了这个 SRAM 最快的读写速度。比较有意思的是 \(t_{AA}\) 最多是 10ns,刚好和 \(t_{RC}\) 的最小值相等。
接下来我们考虑一下如何为 SRAM 控制器时序读取的功能。看到上面的波形图,大概可以想到几条设计思路:
- 首先输出要读取的地址,为了让它稳定(\(t_{RC}\) 的时间内不能变化),要直接从 FPGA 内部寄存器的输出端口输出
- 等待若干个周期,确保数据已经稳定,在满足 FPGA 内部寄存器的 setup 和 hold 约束的情况下,把结果保存在内部寄存器中。
简单起见,先设置一个非常快的 SRAM 控制器频率:500MHz,每个周期 2ns,假如在 a 时刻地址寄存器输出了当前要读取的地址,那么数据会在一段时间后变为合法。这里 a->b 是读取周期时间 \(t_{RC}\),a->c 是地址到数据的延迟 \(t_{AA}\),b->d 是地址改变后数据的保持时间 \(t_{OH}\)。
那么根据这个图,很自然的想法是,我先给出地址,然后数周期,数了五个周期后,此时 \(t_{RC}=10\mathrm{ns}\),然后我就在 e 的上升沿上把输入数据锁存到寄存器中,例如下面的波形:
这个时候 data_reg 的 setup 时间是 c->e,hold 时间是 e->d。从图中看起来还有很多的余量,但如果考虑最坏情况,\(t_{AA}=10\mathrm{ns}\),就会变成下面的波形:
这个时候在 e 时刻不再满足 setup 约束。这个问题在仿真中,可能会“极限操作”表现为没有问题,但实际上,地址从 FPGA 到 SRAM 的延迟有:
- 地址寄存器从时钟上升沿到输出变化的延迟:\(T_{CKO}=0.40\mathrm{ns}\)
- 寄存器输出到 FPGA 输出引脚的延迟:\(T_{IOOP} \in (2.56, 3.80)\mathrm{ns}\)
- FPGA 输出的地址信号通过信号线到 SRAM 的延迟:\(T_{PD}\)
数据从 SRAM 到 FPGA 的延迟有:
- SRAM 数据信号通过信号线到 FPGA 的延迟:\(T_{PD}\)
- FPGA 的输入引脚到内部寄存器输入端的延迟:\(T_{IOPI}=1.26ns\)
- FPGA 内部寄存器的 setup 时间:\(T_{AS}=0.07\mathrm{ns}\)
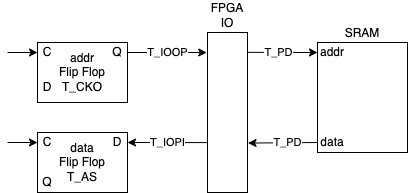
上面的一些数据可以从 Artix-7 FPGA Datasheet 里查到,取的是速度等级 -3 的数据,IO 标准是 LVCMOS33。其中寄存器到 FPGA 输入输出引脚的延迟,实际上由两部分组成:从寄存器到 IOB(IO Block)的延迟,以及 IOB 到 FPGA 输入输出引脚的延迟。我们把地址寄存器的输出作为地址输出,这样 Vivado 就会把寄存器放到 IOB,于是可以忽略寄存器到 IOB 的延迟,详情可以阅读文档 Successfully packing a register into an IOB with Vivado。
把上面一串加起来,已经有大概 4 到 5ns 了。考虑了延迟以后,上面的图可能实际上是这个样子:
考虑了这么多实际的延迟因素以后,会发现这个事情并不简单,需要预先估计出数据在大概什么时候稳定,这时候才能保证数据寄存器上保存的数据是正确的。
转念一想,我们的 SRAM Controller 肯定不会跑在 500MHz 这么高的频率下。假如采用 100MHz,可以每两个周期进行一次读操作:
此时在 b 时钟上边沿对 data_fpga 采样就可以保证满足时序的要求。注意这里第二个周期(上图的 a)不能给出第二次读取的地址,否则稳定时间太短,不满足 hold 约束。
如果频率继续降低,使得一个时钟周期大于 \(t_{AA}\) 加上各种延迟和 setup 时间,那就可以每个周期进行一次读操作:
此时在 a 时钟上升沿上,对 data_fpga 进行采样,并且输出下一次读请求的地址。
写时序¶
接下来再看看写时序。写时序涉及的信号更多,更加复杂一些,但好处是信号都是从 FPGA 到 SRAM,因此考虑延迟的时候会比较简单,比如上面读时序中需要考虑从 FPGA 到 SRAM 的地址,再从 SRAM 到 FPGA 的数据的路径。时序图如下:
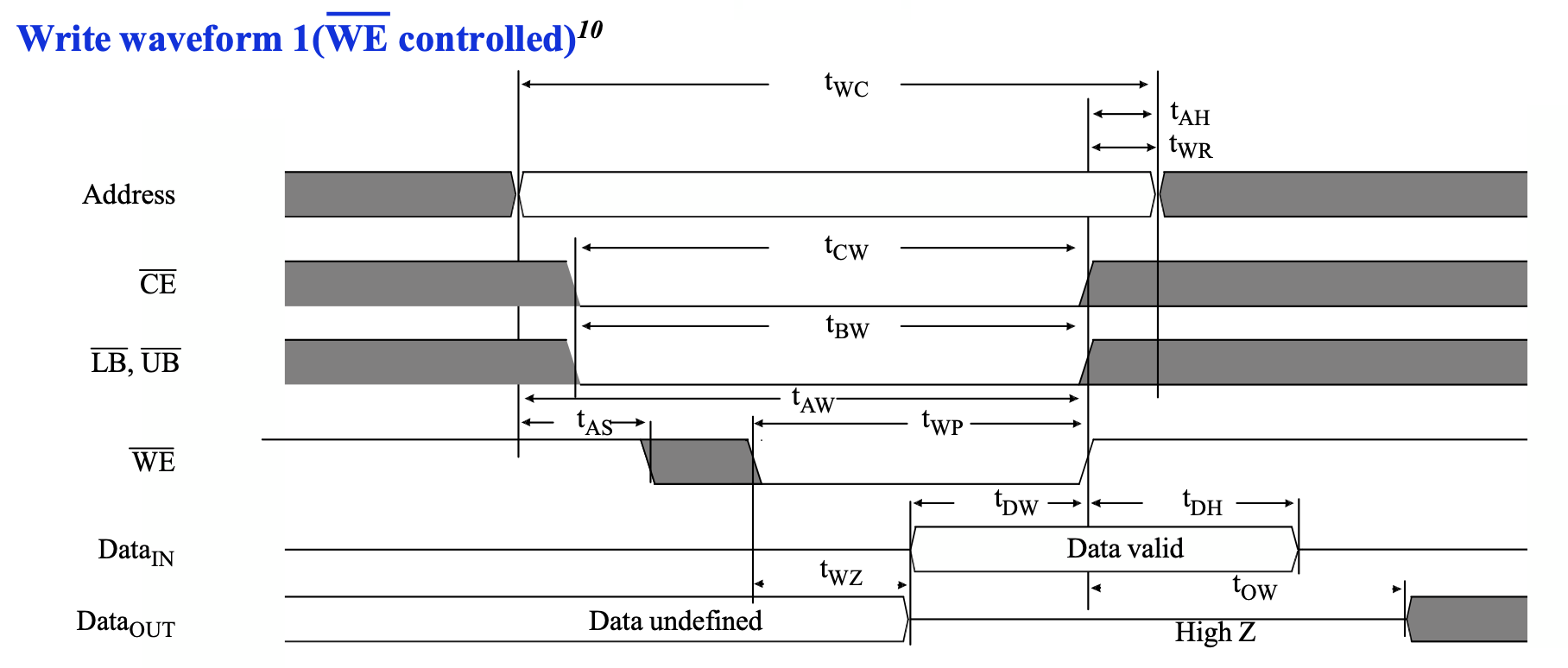
这个写的时序图,从时间顺序来看有这么几件事情按顺序发生:
- 地址保持稳定
- 经过 \(t_{AS}\) 时间后,写使能信号 \(\overline{WE}\) 变为低电平,表示“开始写入操作”,此时地址是稳定的
- 经过 \(t_{WP}\) 时间后,写使能信号\(\overline{WE}\) 变为高电平,表示“结束写入操作”,此时地址和数据都是稳定的,并且数据满足 setup(\(t_{DW}\))和 hold(\(t_{DH}\))约束
- 继续保持地址稳定,直到已经稳定了 \(t_{WC}\) 时间
这些数据的范围如下:
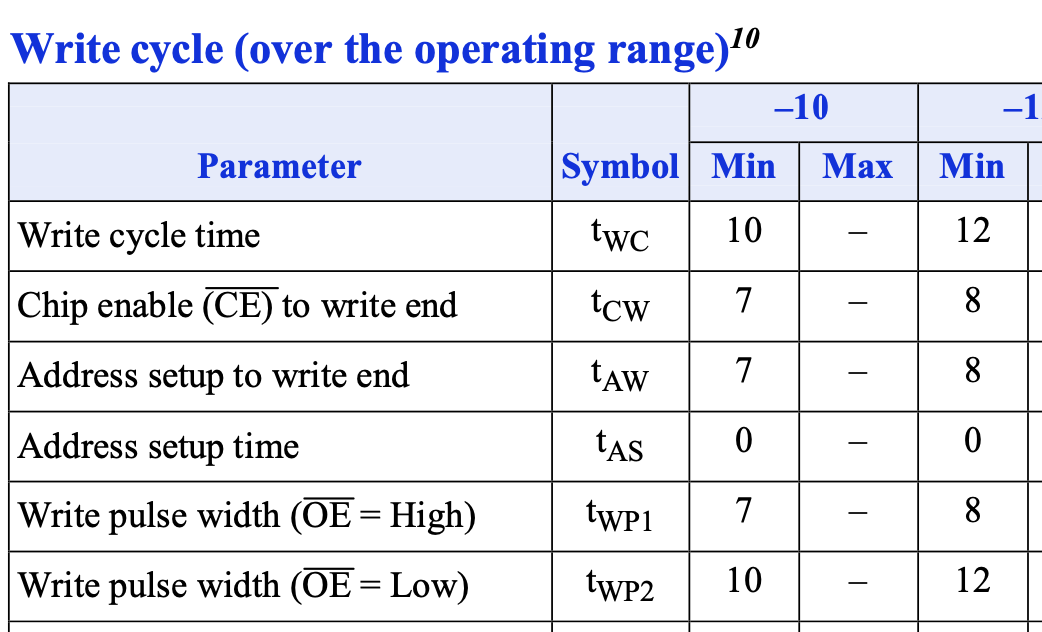
根据上面的分析,还是先考虑一个 500MHz 的 SRAM 控制器。控制器要写入的话,可以按照如下的顺序操作:
- 第一个周期(下图的
a)先输出要写入的地址和数据,并且设置好ce_n,oe_n,we_n,ub_n和lb_n。 - 第二个周期(下图的
c)设置 \(\overline{WE}\) 为低电平,这是为了满足 \(t_{AS}\) (下图的a -> c)的条件 - 等待若干个周期(下图的
c -> d),直到 \(t_{WP}\) (下图的c -> d)和 \(t_{AW}\) (下图的a -> d)时间满足条件 - 设置 \(\overline{WE}\) 为高电平(下图的
d),等待若干个周期(下图的d -> b),直到满足图中的 \(t_{WC}\) (下图的a -> b)时间满足条件
这时候你可能有点疑惑,之前分析读时序的时候,考虑了那么多延迟,为什么写的时候不考虑了?这是因为,写的时候所有的信号都是从 FPGA 输出到 SRAM 的,只要这些信号都是从寄存器直接输出,它们的延迟基本是一样的,所以在 FPGA 侧是什么波形,在 SRAM 侧也是什么波形(准确来说,数据信号因为输出是三态门,所以延迟会稍微高一点,但是由于数据信号的时序余量很大,这个额外的延迟可以忽略不计)。
这时候你可能又有一个疑惑了,在阅读 Datasheet 后发现,\(t_{AS}\) 最小是 0ns,那能不能在上图的 a 时刻就输出 we_n=0?答案是不行,虽然从波形上来看,是在同一个时钟上升沿更新,但实际上会有一微小的延迟差距,可能导致 we_n 在 addr 之前变化,这时候就可能导致 SRAM 观察到的地址是不稳定的。
再考虑一个比较实际的 100MHz 主频 SRAM 控制器,按照如下的波形,则是每三个周期进行一次写操作:
如果觉得这样做太过保守,想要提升性能,有如下几个可能的思路:
- 让
we_n=0在时钟下降沿输出,但是编写的时候需要比较谨慎,比如先设置一个上升沿触发的寄存器,然后用另一个寄存器在下降沿对这个寄存器进行采样,再输出。 - 用一个更高频率的时钟驱动
we_n的寄存器。 - 用 FPGA 提供的
ODELAY自定义输出延迟原语,设置一个固定的输出延迟,比如 1ns。 - 用
ODDR原语,人为地添加一个大约 0.50ns 的延迟。 - 对
we_n设置一个最小的输出延迟(设置了一个很大的 hold),并且不允许输出we_n的寄存器放在 IOB 中(否则无法人为增加信号传播的路径长度)。约束:set_output_delay -clock [get_clocks sram_clk] -min -5.00 [get_ports sram_we_n]和set_property IOB FALSE [get_cells top/sram_controller/we_n_reg]。这里的信号和寄存器名称需要按照实际情况修改,第二个不允许放置在 IOB 的约束也可以在 Verilog 代码中用(* IOB = "FALSE" *)来实现。
按照上面的思路实现,下面是可能达到的效果:
单周期:
双周期:
PL241 SRAM 控制器¶
刚刚我们已经设计好了我们的 SRAM 控制器,再让我们来看看 ARM 提供的 SRAM 控制器时序是怎么样的:ARM 文档提供了 PrimeCell AHB SRAM/NOR Memory Controller (PL241) 的时序图。
读时序:

它第一个周期设置了 ce_n=0 和 addr,等待一个周期后,设置 oe_n=0,再等待两个周期,得到数据。
写时序:

它第一个周期设置了 ce_n=0 addr 和 data,等待一个周期后,设置 we_n=0,等待两个周期,再设置 we_n=1,这样就完成了写入。这和我们的实现是类似的:等待一个额外的周期,保证满足 we_n 下降时地址已经是稳定的。ARM 的文档里也写了如下的备注:
The timing parameter tWC is controlling the deassertion of smc_we_n_0. You can
use it to vary the hold time of smc_cs_n_0[3:0], smc_add_0[31:0] and
smc_data_out_0[31:0]. This differs from the read case where the timing
parameter tCEOE controls the delay in the assertion of smc_oe_n_0.
Additionally, smc_we_n_0 is always asserted one cycle after smc_cs_n_0[3:0] to
ensure the address bus is valid.
参考文档¶
- 1M x 16 HIGH-SPEED ASYNCHRONOUS CMOS STATIC RAM WITH 3.3V SUPPLY
- Artix-7 FPGAs Data Sheet: DC and AC Switching Characteristics
- Timing constraints for an Asynchronous SRAM interface
- Successfully packing a register into an IOB with Vivado
- How to verify whether an I/O register is packed into IOB
- PrimeCell AHB SRAM/NOR Memory Controller (PL241) - Memory interface operation