2022¶
InfiniBand 学习笔记
本文的内容已经整合到知识库中。
概览
InfiniBand 的网络分为两层,第一层是由 End Node 和 Switch 组成的 Subnet,第二层是由 Router 连接起来的若干个 Subnet。有点类似以太网以及 IP 的关系,同一个二层内通过 MAC 地址转发,三层间通过 IP 地址转发。
在 IB 网络中,End Node 一般是插在结点上的 IB 卡(Host Channel Adapter,HCA)或者是存储结点上的 Target Channel Adapter。End Node 之间通过 Switch 连接成一个 Subnet,由 Subnet Manager 给每个 Node 和 Switch 分配 Local ID,同一个 Subnet 中通过 LID(Local ID)来路由。但是 LID 位数有限,为了进一步扩展,可以用 Router 连接多个 Subnet,此时要通过 GID(Global ID)来路由。
升级 Mellanox 网卡固件
背景
最近发现有一台机器,插上 ConnectX-4 IB 网卡后,内核模块可以识别到设备,但是无法使用,现象是 ibstat 等命令都看不到设备。降级 OFED 从 5.8 到 5.4 以后问题消失,所以认为可能是新的 OFED 与比较旧的固件版本有兼容性问题,所以尝试升级网卡固件。升级以后,问题就消失了。
安装 MFT
首先,在 https://network.nvidia.com/products/adapter-software/firmware-tools/ 下载 MFT,按照指示解压,安装后,启动 mst 服务,就可以使用 mlxfwmanager 得到网卡的型号以及固件版本:
Device Type: ConnectX4
Description: Mellanox ConnectX-4 Single Port EDR PCIE Adapter LP
PSID: DEL2180110032
Versions: Current
FW 12.20.1820
升级固件
从 PSID 可以看到,这是 DELL OEM 版本的网卡,可以在 https://network.nvidia.com/support/firmware/dell/ 处寻找最新固件,注意需要保证 PSID 一致,可以找到这个 PSID 的 DELL 固件地址:https://www.mellanox.com/downloads/firmware/fw-ConnectX4-rel-12_28_4512-06W1HY_0JJN39_Ax-FlexBoot-3.6.203.bin.zip。
下载以后,解压,然后就可以升级固件:
升级以后重启就工作了。
考虑到类似的情况之后还可能发生,顺便还升级了其他几台机器的网卡,下面是一个例子:
Device Type: ConnectX4
Description: ConnectX-4 VPI adapter card; FDR IB (56Gb/s) and 40GbE; dual-port QSFP28; PCIe3.0 x8; ROHS R6
PSID: MT_2170110021
Versions: Current
FW 12.25.1020
注意这里的 PSID 是 MT_ 开头,说明是官方版本。这个型号可以在 https://network.nvidia.com/support/firmware/connectx4ib/ 找到最新的固件,注意 PSID 要正确,可以找到固件下载地址 https://www.mellanox.com/downloads/firmware/fw-ConnectX4-rel-12_28_2006-MCX454A-FCA_Ax-UEFI-14.21.17-FlexBoot-3.6.102.bin.zip。用同样的方法更新即可。
还有一个 ConnectX-3 的例子:
Device Type: ConnectX3
Description: ConnectX-3 VPI adapter card; single-port QSFP; FDR IB (56Gb/s) and 40GigE; PCIe3.0 x8 8GT/s; RoHS R6
PSID: MT_1100120019
Versions: Current
FW 2.36.5150
ConnectX-3 系列的网卡固件可以在 https://network.nvidia.com/support/firmware/connectx3ib/ 找,根据 PSID,可以找到固件下载地址是 http://www.mellanox.com/downloads/firmware/fw-ConnectX3-rel-2_42_5000-MCX353A-FCB_A2-A5-FlexBoot-3.4.752.bin.zip。
小结
如果遇到 Mellanox 网卡能识别 PCIe,但是不能使用,可以考虑降级 OFED 或者升级网卡固件。
可以用 mlxfwmanager 查看 PSID 和更新固件。根据 PSID,判断是 OEM(DELL)版本还是官方版本。如果是 OEM 版本,要到对应 OEM 的固件下载地址找,例如 https://network.nvidia.com/support/firmware/dell/;如果是官方版,在 https://network.nvidia.com/support/firmware/firmware-downloads/ 找。
PCIe 学习笔记
本文的内容已经整合到知识库中。
背景
最近在知乎上看到 LogicJitterGibbs 的 资料整理:可以学习 1W 小时的 PCIe,我跟着资料学习了一下,然后在这里记录一些我学习 PCIe 的笔记。
在 GNURadio Companion 中收听 FM 广播
背景
以前买过 RTL-SDR,用 Gqrx 做过收音机,当时还给 Homebrew 尝试提交过几个 sdr 相关的 pr,但是限于知识的缺乏,后来就没有再继续尝试了。
前两天,@OceanS2000 讲了一次 Tunight: 高级收音机使用入门,又勾起了我的兴趣,所以我来尝试一下在 GNURadio Companion 中收听 FM 广播电台。
我没有上过无线电相关课程,所以下面有一些内容可能不正确或者不准确。
ESXi 配置 LACP 链路聚合
背景
给 ESXi 接了两路 10Gbps 的以太网,需要用 LACP 来聚合。ESXi 自己不能配置 LACP,需要配合 vCenter Server 的 Distributed Switch 来配置。
Buildroot 2020.08 的 Fakeroot 版本过旧导致的兼容性问题
背景
最近在给之前的 Buildroot 2020.09 增加新的软件包,结果编译的时候报错:
还有一个背景是前段时间把系统升级到了 Ubuntu 22.04 LTS。
用 Nix 编译 Rust 项目
背景
Rust 项目一般是用 Cargo 管理,但是它的缺点是每个项目都要重新编译一次所有依赖,硬盘空间占用较大,不能跨项目共享编译缓存。调研了一下,有若干基于 Nix 的 Rust 构建工具:
- cargo2nix: https://github.com/cargo2nix/cargo2nix
- carnix: 不再更新
- crane: https://github.com/ipetkov/crane
- crate2nix: https://github.com/kolloch/crate2nix
- naersk: https://github.com/nix-community/naersk
- nocargo: https://github.com/oxalica/nocargo
下面我分别来尝试一下这几个工具的使用。
invalid date 报错与时区的关系
背景
最近在验题的时候,@HarryChen 发现了一个现象:
$ date -d "1919-04-13"
date: invalid date ‘1919-04-13’
$ TZ=UTC date -d "1919-04-13"
Sun Apr 13 00:00:00 UTC 1919
也就是说,这个现象与时区有关,那么为啥 1919-04-13 是一个不合法的日期呢?
时区
实际上,对于某一个时区来说,有的时间是不存在的,最常见的就是夏令时。在 Timezone DB 里可以看到,恰好在 1919 年 4 月 13 日发生了一次 UTC+8 到 UTC+9 的变化,因此零点变成了一点,就变成了不合法的日期。
这个数据,实际上保存在 tzdata 中,可以用 zdump 工具查看:
$ tzdata -v Asia/Shanghai
Asia/Shanghai Fri Dec 13 20:45:52 1901 UTC = Sat Dec 14 04:45:52 1901 CST isdst=0
Asia/Shanghai Sat Dec 14 20:45:52 1901 UTC = Sun Dec 15 04:45:52 1901 CST isdst=0
Asia/Shanghai Sat Apr 12 15:59:59 1919 UTC = Sat Apr 12 23:59:59 1919 CST isdst=0
Asia/Shanghai Sat Apr 12 16:00:00 1919 UTC = Sun Apr 13 01:00:00 1919 CDT isdst=1
Asia/Shanghai Tue Sep 30 14:59:59 1919 UTC = Tue Sep 30 23:59:59 1919 CDT isdst=1
Asia/Shanghai Tue Sep 30 15:00:00 1919 UTC = Tue Sep 30 23:00:00 1919 CST isdst=0
Asia/Shanghai Fri May 31 15:59:59 1940 UTC = Fri May 31 23:59:59 1940 CST isdst=0
Asia/Shanghai Fri May 31 16:00:00 1940 UTC = Sat Jun 1 01:00:00 1940 CDT isdst=1
Asia/Shanghai Sat Oct 12 14:59:59 1940 UTC = Sat Oct 12 23:59:59 1940 CDT isdst=1
Asia/Shanghai Sat Oct 12 15:00:00 1940 UTC = Sat Oct 12 23:00:00 1940 CST isdst=0
Asia/Shanghai Fri Mar 14 15:59:59 1941 UTC = Fri Mar 14 23:59:59 1941 CST isdst=0
Asia/Shanghai Fri Mar 14 16:00:00 1941 UTC = Sat Mar 15 01:00:00 1941 CDT isdst=1
Asia/Shanghai Sat Nov 1 14:59:59 1941 UTC = Sat Nov 1 23:59:59 1941 CDT isdst=1
Asia/Shanghai Sat Nov 1 15:00:00 1941 UTC = Sat Nov 1 23:00:00 1941 CST isdst=0
Asia/Shanghai Fri Jan 30 15:59:59 1942 UTC = Fri Jan 30 23:59:59 1942 CST isdst=0
Asia/Shanghai Fri Jan 30 16:00:00 1942 UTC = Sat Jan 31 01:00:00 1942 CDT isdst=1
Asia/Shanghai Sat Sep 1 14:59:59 1945 UTC = Sat Sep 1 23:59:59 1945 CDT isdst=1
Asia/Shanghai Sat Sep 1 15:00:00 1945 UTC = Sat Sep 1 23:00:00 1945 CST isdst=0
Asia/Shanghai Tue May 14 15:59:59 1946 UTC = Tue May 14 23:59:59 1946 CST isdst=0
Asia/Shanghai Tue May 14 16:00:00 1946 UTC = Wed May 15 01:00:00 1946 CDT isdst=1
Asia/Shanghai Mon Sep 30 14:59:59 1946 UTC = Mon Sep 30 23:59:59 1946 CDT isdst=1
Asia/Shanghai Mon Sep 30 15:00:00 1946 UTC = Mon Sep 30 23:00:00 1946 CST isdst=0
Asia/Shanghai Mon Apr 14 15:59:59 1947 UTC = Mon Apr 14 23:59:59 1947 CST isdst=0
Asia/Shanghai Mon Apr 14 16:00:00 1947 UTC = Tue Apr 15 01:00:00 1947 CDT isdst=1
Asia/Shanghai Fri Oct 31 14:59:59 1947 UTC = Fri Oct 31 23:59:59 1947 CDT isdst=1
Asia/Shanghai Fri Oct 31 15:00:00 1947 UTC = Fri Oct 31 23:00:00 1947 CST isdst=0
Asia/Shanghai Fri Apr 30 15:59:59 1948 UTC = Fri Apr 30 23:59:59 1948 CST isdst=0
Asia/Shanghai Fri Apr 30 16:00:00 1948 UTC = Sat May 1 01:00:00 1948 CDT isdst=1
Asia/Shanghai Thu Sep 30 14:59:59 1948 UTC = Thu Sep 30 23:59:59 1948 CDT isdst=1
Asia/Shanghai Thu Sep 30 15:00:00 1948 UTC = Thu Sep 30 23:00:00 1948 CST isdst=0
Asia/Shanghai Sat Apr 30 15:59:59 1949 UTC = Sat Apr 30 23:59:59 1949 CST isdst=0
Asia/Shanghai Sat Apr 30 16:00:00 1949 UTC = Sun May 1 01:00:00 1949 CDT isdst=1
Asia/Shanghai Fri May 27 14:59:59 1949 UTC = Fri May 27 23:59:59 1949 CDT isdst=1
Asia/Shanghai Fri May 27 15:00:00 1949 UTC = Fri May 27 23:00:00 1949 CST isdst=0
Asia/Shanghai Sat May 3 17:59:59 1986 UTC = Sun May 4 01:59:59 1986 CST isdst=0
Asia/Shanghai Sat May 3 18:00:00 1986 UTC = Sun May 4 03:00:00 1986 CDT isdst=1
Asia/Shanghai Sat Sep 13 16:59:59 1986 UTC = Sun Sep 14 01:59:59 1986 CDT isdst=1
Asia/Shanghai Sat Sep 13 17:00:00 1986 UTC = Sun Sep 14 01:00:00 1986 CST isdst=0
Asia/Shanghai Sat Apr 11 17:59:59 1987 UTC = Sun Apr 12 01:59:59 1987 CST isdst=0
Asia/Shanghai Sat Apr 11 18:00:00 1987 UTC = Sun Apr 12 03:00:00 1987 CDT isdst=1
Asia/Shanghai Sat Sep 12 16:59:59 1987 UTC = Sun Sep 13 01:59:59 1987 CDT isdst=1
Asia/Shanghai Sat Sep 12 17:00:00 1987 UTC = Sun Sep 13 01:00:00 1987 CST isdst=0
Asia/Shanghai Sat Apr 16 17:59:59 1988 UTC = Sun Apr 17 01:59:59 1988 CST isdst=0
Asia/Shanghai Sat Apr 16 18:00:00 1988 UTC = Sun Apr 17 03:00:00 1988 CDT isdst=1
Asia/Shanghai Sat Sep 10 16:59:59 1988 UTC = Sun Sep 11 01:59:59 1988 CDT isdst=1
Asia/Shanghai Sat Sep 10 17:00:00 1988 UTC = Sun Sep 11 01:00:00 1988 CST isdst=0
Asia/Shanghai Sat Apr 15 17:59:59 1989 UTC = Sun Apr 16 01:59:59 1989 CST isdst=0
Asia/Shanghai Sat Apr 15 18:00:00 1989 UTC = Sun Apr 16 03:00:00 1989 CDT isdst=1
Asia/Shanghai Sat Sep 16 16:59:59 1989 UTC = Sun Sep 17 01:59:59 1989 CDT isdst=1
Asia/Shanghai Sat Sep 16 17:00:00 1989 UTC = Sun Sep 17 01:00:00 1989 CST isdst=0
Asia/Shanghai Sat Apr 14 17:59:59 1990 UTC = Sun Apr 15 01:59:59 1990 CST isdst=0
Asia/Shanghai Sat Apr 14 18:00:00 1990 UTC = Sun Apr 15 03:00:00 1990 CDT isdst=1
Asia/Shanghai Sat Sep 15 16:59:59 1990 UTC = Sun Sep 16 01:59:59 1990 CDT isdst=1
Asia/Shanghai Sat Sep 15 17:00:00 1990 UTC = Sun Sep 16 01:00:00 1990 CST isdst=0
Asia/Shanghai Sat Apr 13 17:59:59 1991 UTC = Sun Apr 14 01:59:59 1991 CST isdst=0
Asia/Shanghai Sat Apr 13 18:00:00 1991 UTC = Sun Apr 14 03:00:00 1991 CDT isdst=1
Asia/Shanghai Sat Sep 14 16:59:59 1991 UTC = Sun Sep 15 01:59:59 1991 CDT isdst=1
Asia/Shanghai Sat Sep 14 17:00:00 1991 UTC = Sun Sep 15 01:00:00 1991 CST isdst=0
Asia/Shanghai Mon Jan 18 03:14:07 2038 UTC = Mon Jan 18 11:14:07 2038 CST isdst=0
Asia/Shanghai Tue Jan 19 03:14:07 2038 UTC = Tue Jan 19 11:14:07 2038 CST isdst=0
可以看到,它列出来了历史上 Asia/Shanghai 时区的变化历史。具体的历史,可以查看 中国时区。
此外,历史上,从儒略历到格里高利历的演变过程,也出现了一段“不存在”的日期,如 Setting October 14 ,1582 fails in java.sql.Date。
Ceph Cookbook
概念
- OSD:负责操作硬盘的程序,一个硬盘一个 OSD
- MON:管理集群状态,比较重要,可以在多个节点上各跑一个
- MGR:监测集群状态
- RGW(optional):提供对象存储 API
- MDS(optional):提供 CephFS
使用 Ceph 做存储的方式:
- librados: 库
- radosgw: 对象存储 HTTP API
- rbd: 块存储
- cephfs: 文件系统
认证
Ceph 客户端认证需要用户名 + 密钥。默认情况下,用户名是 client.admin,密钥路径是 /etc/ceph/ceph.用户名.keyring。ceph --user abc 表示以用户 client.abc 的身份访问集群。
用户的权限是按照服务类型决定的。可以用 ceph auth ls 显示所有的用户以及权限:
$ ceph auth ls
osd.0
key: REDACTED
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: REDACTED
caps: [mds] allow *
caps: [mgr] allow *
caps: [mon] allow *
caps: [osd] allow *
可以看到,osd.0 对 OSD 有所有权限,对 mgr 和 mon 都只有 osd 相关功能的权限;client.admin 有所有权限。profile 可以认为是预定义的一些权限集合。
新建用户并赋予权限:
修改权限:
获取权限:
删除用户:
OSD
管理 OSD 实际上就是管理存储数据的硬盘。
查看状态:
显示有多少个在线和离线的 OSD。
显示了存储的层级,其中 ID 非负数是实际的 OSD,负数是其他层级,例如存储池,机柜,主机等等。
CRUSH
CRUSH 是一个算法,指定了如何给 PG 分配 OSD,到什么类型的设备,确定它的 failure domain 等等。例如,如果指定 failure domain 为 host,那么它就会分配到不同 host 上的 osd,这样一个 host 挂了不至于全军覆没。类似地,还可以设定更多级别的 failure domain,例如 row,rack,chassis 等等。
OSD 可以设置它的 CRUSH Location,在 ceph.conf 中定义。
为了配置数据置放的规则,需要设置 CRUSH Rule。
列举 CRUSH Rule:
查看 CRUSH 层级:
在里面可能会看到 default~ssd,它指的意思就是只保留 default 下面的 ssd 设备。
文本形式导出 CRUSH 配置:
可以看到 Rule 的定义,如:
# simple replicated
rule replicated_rule {
id 0
# a replicated rule
type replicated
# iterate all devices of "default"
step take default
# select n osd with failure domain "osd"
# firstn: continuous
step chooseleaf firstn 0 type osd
step emit
}
# erasure on hdd
rule erasure-hdd {
id 4
# an erasure rule
type erasure
# try more times to find a good mapping
step set_chooseleaf_tries 5
step set_choose_tries 100
# iterate hdd devices of "default", i.e. "default~hdd"
step take default class hdd
# select n osd with failure domain "osd"
# indep: replace failed osd with another
step choose indep 0 type osd
step emit
}
# replicated on hdd
rule replicated-hdd-osd {
id 5
# a replicated rule
type replicated
# iterate hdd devices of "default", i.e. "default~hdd"
step take default class hdd
# select n osd with failure domain "osd"
# firstn: continuous
step choose firstn 0 type osd
step emit
}
# replicated on different hosts
rule replicated-host {
id 6
# a replicated rule
type replicated
# iterate all devices of "default"
step take default
# select n osd with failure domain "host"
# firstn: continuous
step chooseleaf firstn 0 type host
step emit
}
# replicate one on ssd, two on hdd
rule replicated-ssd-primary {
id 7
# a replicated rule
type replicated
# iterate ssd devices of "default"
step take default class ssd
step chooseleaf firstn 1 type host
step emit
# iterate hdd devices of "default"
step take default class hdd
step chooseleaf firstn 2 type host
step emit
}
choose 和 chooseleaf 的区别是,前者可以 choose 到中间层级,例如先选择 host,再在 host 里面选 osd;而 chooseleaf 是直接找到 osd。所以 choose type osd 和 chooseleaf type osd 是等价的。
如果这个搜索条件比较复杂,例如找到了某一个 host,里面的 osd 个数不够,就需要重新搜。
新建一个 Replicated CRUSH Rule:
# root=default, failure domain=osd
ceph osd crush rule create-replicated xxx default osd
# root=default, failure domain=host, class=ssd
ceph osd crush rule create-replicated yyy default host ssd
如果指定了 device class,它只会在对应类型的设备上存储。
Pool
Pool 是存储池,后续的 RBD/CephFS 功能都需要指定存储池来工作。
创建存储池:
为了性能考虑,可以设置 PG(Placement Group)数量。默认情况下,会创建 replicated 类型的存储池,也就是会存多份,类似 RAID1。也可以设置成 erasure 类型的存储池,类似 RAID5。
每个 Placement Group 里的数据会保存在同一组 OSD 中。数据通过 hash,会分布在不同的 PG 里。
列举所有的存储池:
查看存储池的使用量:
存储池的 IO 状态:
对存储池做快照:
删除 Pool:
PG
PG 是数据存放的组,每个对象都会放到一个 PG 里面,而 PG 会决定它保存到哪些 OSD 上(具体哪些 OSD 是由 CRUSH 决定的)。PG 数量只有一个的话,那么一个 pool 的所有数据都会存放在某几个 OSD 中,一旦这几个 OSD 都不工作了,那么整个 pool 的数据都不能访问了。PG 增多了以后,就会分布到不同的 OSD 上,并且各个 OSD 的占用也会比较均匀。
查看 PG 状态:
Auto Scale
PG 数量可以让集群自动调整:
设置 autoscale 目标为每个 OSD 平均 100 个 PG:
全局 autoscale 开关:
# Enable
ceph osd pool unset noautoscale
# Disable
ceph osd pool set unautoscale
# Read
ceph osd pool get noautoscale
查看 autoscale 状态:
如果没有显示,说明 autoscale 没有工作,可能的原因是,部分 pool 采用了指定 osd class 的 crush rule,例如指定了 hdd 盘,但是也有部分 pool 没有指定盘的类型,例如默认的 replicated_rule。这时候,把这些盘也设置成一个指定 osd class 的 crush rule 即可。
RBD
RBD 把 Ceph 暴露为块设备。
创建
初始化 Pool 用于 RBD:
为了安全性考虑,一般会为 RBD 用户创建单独的用户:
ceph auth get-or-create client.abc mon 'profile rbd' osd 'profile rbd pool=xxx' mgr 'profile rbd pool=xxx'
创建 RBD 镜像:
表示在 Pool xxx 上面创建了一个名字为 yyy 大小为 1024MB 的镜像。
状态
列举 Pool 里的镜像:
默认的 Pool 名字是 rbd。
查看镜像信息:
扩容
修改镜像的容量:
挂载
在其他机器挂载 RBD 的时候,首先要修改 /etc/ceph 下配置,确认有用户,密钥和 MON 的地址。
然后,用 rbd 挂载设备:
以用户 abc 的身份挂载 Pool xxx 下面的 yyy 镜像。
这时候就可以在 /dev/rbd* 或者 /dev/rbd/ 下面看到设备文件了。
显示已经挂载的设备:
CephFS
创建
如果配置了编排器(Orchestrator),可以直接用命令:
创建一个名为xxx 的 CephFS。
也可以手动创建:
ceph osd pool create xxx_data0
ceph osd pool create xxx_metadata
ceph fs new xxx xxx_metadata xxx_data0
这样就创建了两个 pool,分别用于存储元数据和文件数据。一个 CephFS 需要一个 pool 保存元数据,若干个 pool 保存文件数据。
创建了 CephFS 以后,相应的 MDS 也会启动。
状态
查看 MDS 状态:
客户端配置
在挂载 CephFS 之前,首先要配置客户端。
在集群里运行 ceph config generate-minimal-conf,它会生成一个配置文件:
$ ceph config generate-minimal-conf
# minimal ceph.conf for <fsid>
[global]
fsid = <fsid>
mon_host = [v2:x.x.x.x:3300/0,v1:x.x.x.x:6789/0]
把内容复制到客户端的 /etc/ceph/ceph.conf。这样客户端就能找到集群的 MON 地址和 FSID。
接着,我们在集群上给客户端创建一个用户:
创建一个用户 abc,对 CephFS xxx 有读写的权限。把输出保存到客户端的 /etc/ceph/ceph.client.abc.keyring 即可。
挂载
挂载:
mount -t ceph abc@.xxx=/ MOUNTPOINT
# or
mount -t ceph abc@<fsid>.xxx=/ MOUNTPOINT
# or
mount -t ceph abc@<fsid>.xxx=/ -o mon_addr=x.x.x.x:6789,secret=REDACTED MOUNTPOINT
#or
mount -t ceph abc@.xxx=/ -o mon_addr=x.x.x.x:6789/y.y.y.y:6789,secretfile=/etc/ceph/xxx.secret MOUNTPOINT
# or
mount -t ceph -o name=abc,secret=REDACTED,mds_namespace=xxx MON_IP:/ MOUNTPOINT
以用户 client.abc 的身份登录,挂载 CepFS xxx 下面的 / 目录到 MOUNTPOINT。它会读取 /etc/ceph 下面的配置,如果已经 ceph.conf 写了,命令行里就可以不写。
fsid 指的不是 CephFS 的 ID,实际上是集群的 ID:ceph fsid。
限额
CephFS 可以对目录进行限额:
setfattr -n ceph.quota.max_bytes -v LIMIT PATH
setfattr -n ceph.quota.max_files -v LIMIT PATH
getfattr -n ceph.quota.max_bytes PATH
getfattr -n ceph.quota.max_files PATH
限制目录大小和文件数量。LIMIT 是 0 的时候表示没有限制。
NFS
可以把 CephFS 或者 RGW 通过 NFS 的方式共享出去。
启动 NFS 服务:
在主机上运行 NFS 服务器,NFS 集群的名字叫做 xxx。
查看 NFS 集群信息:
列举所有 NFS 集群:
NFS 导出 CephFS:
ceph nfs export create cephfs --cluster-id xxx --pseudo-path /a/b/c --fsname some-cephfs-name [--path=/d/e/f] [--client_addr y.y.y.y]
这样就导出了 CephFS 内的一个目录,客户端可以通过 NFS 挂载 /a/b/c 路径(pseudo path)来访问。可以设置客户端的 IP 访问权限。
这样在客户端就可以 mount:
列出所有 CephFS
获取 CephFS Volume 信息
RadosGW
RGW 提供了 S3 或者 OpenStack Swift 兼容的对象存储 API。
列出所有 Bucket:
获取所有 Bucket 的统计信息:
编排器
由于 Ceph 需要运行多个 daemon,并且都在不同的容器中运行,所以一般会跑一个系统级的编排器,用于新增和管理这些容器。
查看当前编排器:
比较常见的就是 cephadm,安装的时候如果用了 cephadm,那么编排器也是它。
被编排的服务:
被编排的容器:
被编排的主机:
添加新机器
首先,复制 /etc/ceph/ceph.pub 到新机器的 /root/.ssh/authorized_keys 中
接着,添加机器到编排器中:
导出编排器配置:
如果想让一些 daemon 只运行在部分主机上,可以修改:
然后应用:
配置监控
添加监控相关的服务:
ceph orch apply node-exporter
ceph orch apply alertmanager
ceph orch apply prometheus
ceph orch apply grafana
ceph orch ps
然后就可以访问 Grafana 看到集群的状态。
单机集群
在集群只有单机的时候,由于默认 MGR 每个 host 只能有一个,所以会导致无法升级。
一种方法是在创建 cluster 的时候,传入 --single-host-defaults 参数,详见 Single host deployment
另一种方法是,动态修改 MGR 的 mgr_standby_modules 选项为 false:
- 运行
ceph config set mgr mgr_standby_modules false -
创建一个
mgr.yaml文件:```yaml service_type: mgr service_name: mgr placement: hosts: - YOUR_HOSTNAME_HERE count_per_host: 2 ``` -
告诉 cephadm,让它在
YOUR_HOSTNAME_HERE机器上部署两个 MGR:ceph orch apply -i mgr.yaml - 这样就成功了,可以用
ceph orch ps确认有两个 MGR,这样就可以升级 ceph 了
更新
使用容器编排器来升级:
ceph orch upgrade start --ceph-version x.x.x
ceph orch upgrade start --image quay.io/ceph/ceph:vx.x.x
如果 docker hub 上找不到 image,就从 quay.io 拉取。
查看升级状态:
查看 cephadm 日志:
参考文档
编程作业中的学术诚信
本文是我自己对 Academic Integrity at MIT: Writing Code 的非官方中文翻译。本文已经得到了官方的邮件授权。
编写代码 Writing Code
与学术写作类似,当你在做课程项目的时候,如果使用了或者改编了其他人开发的代码,你必须要引用代码的来源。你可以在代码注释中引用代码来源。这些注释不仅保护了他人的劳动成果,也会帮助你理解代码和调试。
Writing code is similar to academic writing in that when you use or
adapt code developed by someone else as part of your project, you must
cite your source. However, instead of quoting or paraphrasing a source,
you include an inline comment in the code. These comments not only
ensure you are giving proper credit, but help with code understanding
and debugging.
什么时候应该在代码中引用来源?When should I cite a source in my code?
-
当你从外部来源复制了代码。无论你是复制了代码片段,还是一整个模块,你都需要引用来源。
When you copy code from an external source. Whether you are copying a snippet of code or an entire module, you should credit the source. -
当你复制了代码并做了改动,你依然要引用来源。你并不是代码的原作者。
When you copy the code and adapt it, you should still credit the source. You were not the original developer of the code.
我应该如何引用代码?How should I cite the code?
-
通常来说,代码的网址和下载时间就足够了。如果可以让读者更加清晰地了解到代码来源,可以增加更多的细节。
Generally, the URL and the date of retrieval are sufficient. Add more details if it will help the reader get a clearer understanding of the source. -
如果你修改了代码,你需要注明:“Adapted from:”(修改自)或者“Based on”(基于)。这样读者就知道你修改了代码。
If you adapted the code, you should indicate “Adapted from:” or “Based on” so it is understood that you modified the code. -
你的老师可能会对你如何引用代码有具体的要求。如果你不能确认什么是可行的,请询问你的老师。
Your instructor may have specific instructions on how you should or should not cite your sources. If you are not clear on what is acceptable, ask your instructor.
开源软件的使用 Use of Open Source Software
当你使用开源软件项目的代码的时候,你不仅要注明代码的来源,还需要遵循代码的开源软件许可证。请记住:
When you use code from an open source project, you need both to
attribute the source and follow the terms of any open source license
that applies to the code you are using. Keep in mind:
-
当你下载源码的时候,它的开源软件许可证通常也在源码中。
When you download the source, the license is typically part of the download. -
同时,代码里也通常会包括它的版权和使用条款。
Also, the source code itself will typically contain the copyright and terms of use. -
当你引入了开源代码,并且它附带了开源软件许可证,你应该把它的版权声明复制到你的代码中,和/或把许可证复制到代码目录中的文件。
When you incorporate open-source-licensed code into a program, it is good practice to duplicate the copyright in your code, and/or store the license in a file with the code. -
如果在下载的文件里没有找到开源软件许可证,你可以在开源项目的网站上找到全文,如 Apache HTTP Server 网站 或者 Open Source Initiative (OSI) 网站。
If you don’t obtain the license with the download, you should be able to find it on the site of the open source project, such as Apache HTTP Server site, or on the Open Source Initiative (OSI) site.
老师决定具体的代码复用程度 Instructors determine the specific expectations around re-use of code in each class.
通常,老师会确定课程的协作规则。如果这个规则没有明确地给出来,或者你不确认什么是可行的,请询问你的老师。
Often, the requirements are described in the collaboration policy for
the class. If policy is not clearly described in the course materials
and you are not sure what is acceptable, ask your instructor.
例子
下面给出一个例子,是课程(Spring 2012 6.005 Elements of Software Construction)的协作规则:
Collaboration policy from Spring 2012 6.005 Elements of Software
Construction: (used with the permission of Professor Rob Miller, Dept of
Electrical Engineering & Computer Science)
我们鼓励同学们互相帮助,但是为了保证每个人都有良好的独立学习体验,我们对你们做了如下的限制:
We encourage you to help each other with work in this class, but there
are limits to what you can do, to ensure that everybody has a good
individual learning experience.
单人作业 Individual work
课程里的习题都要单人完成。我们鼓励同学们讨论实现方法,但是你的代码和报告都需要自己完成。
Problem sets in this class are intended to be primarily individual
efforts. You are encouraged to discuss approaches with other students
but your code and your write-up must be your own.
你不能使用其他同学编写的资料,无论是这个学期还是以往学期的同学。你也不可以把你的成果提供给其他同学。
You may not use materials produced as course work by other students,
whether in this term or previous terms, nor may you provide work for
other students to use.
帮助其他同学是应该的。但要保证一个原则,当你在帮助其他同学的时候,你自己的答案或代码不应该可以看到,无论是自己还是其他同学。可以养成一个习惯,帮助他人的时候把笔记本电脑合上。
It’s good to help other students. But as a general rule, during the time
that you are helping another student, your own solution should not be
visible, either to you or to them. Make a habit of closing your laptop
while you’re helping.
在帮助其他同学,阅读同学的代码的时候,你会看到同学的解答。你可以从同学的方法里获得灵感,但是不能复制他们的成果。
During code review, you will see classmates’ solutions to a problem set.
While it is fine to take inspiration from their approach, do not copy
their work.
你可以用外部网站上的资料,比如 StackOverflow,但前提是加上引用,并且作业要求里允许这么做。特别地,如果作业要求里写了“实现 X 功能”,那么你必须自己实现 X 功能,而不能复用外部的代码。
It’s fine to use material from external sources like StackOverflow, but
only with proper attribution, and only if the assignment allows it. In
particular, if the assignment says “implement X,” then you must create
your own X, not reuse one from an external source.
你也可以用课程组提供的代码,不需要引用。老师提供的代码在未经允许的情况下,不能公开分享,我们后面会讨论这个问题。
It’s also fine to use any code provided by this semester’s 6.031 staff
(in class, readings, or problem sets), without need for attribution.
Staff-provided code may not be publicly shared without permission,
however, as discussed later in this document.
例子一 Example 1:
-
A 和 B 做作业的时候坐在一起。他们简略地讨论实现的不同方法。他们在白板上画流程图。当 A 发现 Java 标准库中一个有用的类,她把这个发现告诉了 B。当 B 发现了 StackOverflow 上的一个回答,他给 A 发送了 URL。可以。
Alyssa and Ben sit next to each other with their laptops while working on a problem set. They talk in general terms about different approaches to doing the problem set. They draw diagrams on the whiteboard. When Alyssa discovers a useful class in the Java library, she mentions it to Ben. When Ben finds a StackOverflow answer that helps, he sends the URL to Alyssa. OK. -
在他们编写代码的时候,他们把代码大声念出来,好让双方都可以编写正确的代码。错误!
As they type lines of code, they speak the code aloud to the other person, to make sure both people have the right code. INAPPROPRIATE. -
在作业最困难的部分,A 和 B 互相看电脑屏幕,并对比代码,确认他们代码实现都是正确的。错误!
In a tricky part of the problem set, Alyssa and Ben look at each other’s screens and compare them so that they can get their code right. INAPPROPRIATE.
例子二 Example 2:
-
J 已经完成了作业,但是他的朋友 B 正在努力解决一个 bug。J 坐在 B 旁边,看他的代码,帮他调试出了问题。可以。
Jerry already finished the problem set, but his friend Ben is now struggling with a nasty bug. Jerry sits next to Ben, looks at his code, and helps him debug. OK. -
J 打开了自己的笔记本,找到自己的答案,然后指着自己的代码给 B 纠正错误。错误!
Jerry opens his own laptop, finds his solution to the problem set, and refers to it while he’s helping Ben correct his code. INAPPROPRIATE.
例子三 Example 3:
-
L 这周有很多作业,但是因为时间和身体原因来不及做。他已经错过截止时间两天了,但基本没有什么进度。B 觉得 L 可怜,想要帮助 L。在 L 写作业的时候,B 告诉 L 他是怎么做作业的。B 已经提交了自己的答案,并且在帮助 L 的时候,不打开自己的笔记本电脑。可以。
Louis had three problem sets and two quizzes this week, was away from campus for several days for a track meet, and then got sick. He’s already taken two slack days on the deadline and has made almost no progress on the problem set. Ben feels sorry for Louis and wants to help, so he sits down with Louis and talks with him about how to do the problem set while Louis is working on it. Ben already handed in his own solution, but he doesn’t open his own laptop to look at it while he’s helping Louis. OK. -
B 打开了自己的笔记本电脑,并且在帮助 L 的时候阅读自己的代码。错误!
Ben opens his laptop and reads his own code while he’s helping Louis. INAPPROPRIATE. -
B 花了几个小时帮助 L,但是 L 还是没有完成。但是 B 需要去做自己的事情了。在 L 承诺只有在必要的时候才会看 B 的代码之后,B 把自己的代码上传到 Dropbox 并且分享给了 L。错误!
Ben has by now spent a couple hours with Louis, and Louis still needs help, but Ben really needs to get back to his own work. He puts his code in a Dropbox and shares it with Louis, after Louis promises only to look at it when he really has to. INAPPROPRIATE.
例子四 Example 4:
- J 和 E 独立完成作业。他们交换了自己的测例来检查作业。错误!测例是题目的一部分,也是学习体验的一部分。如果你使用了其他人的测例,就是在抄袭,即使只是临时的。
John and Ellen both worked on their problem sets separately. They exchange their test cases with each other to check their work. INAPPROPRIATE. Test cases are part of the material for the problem set, and part of the learning experience of the course. You are copying if you use somebody else’s test cases, even if temporarily.
注意,在上面的例子中,双方都负有学术不端的责任。抄袭作业,或者把自己的作业提供给他人,是一个很严重的事情,可能导致分数扣减,课程不及格甚至处分。抄袭作业,或者帮助他人抄袭,可能会给你的成绩单上添加一个不能消除的 F。
Note that in the examples marked inappropriate above, both people are
held responsible for the violation in academic honesty. Copying work, or
knowingly making work available for copying, in contravention of this
policy is a serious offense that may incur reduced grades, failing the
course, and disciplinary action. Copying, or helping somebody copy, may
result in an F on your transcript that you will not be able to drop.
上述的要求对课程所有的单人作业都使用。
This policy applies to all coursework that is handed in by an
individual: problem sets, reading exercises, nanoquiz makeups, etc.
组队作业 Group work
你应该和你的队友合作完成组队作业,并且每个人都应该有接近的任务量。
You should collaborate with your partners on all aspects of group
project work and in-class collaborative exercises, and each of you is
expected to contribute a roughly equal share to design and
implementation.
你可以复用自己在学期内早些时候编写的代码等(包括之前自己和其他队友完成的)。你也可以用课程提供的任何代码。
You may reuse designs, ideas and code from your own work earlier in the
semester (even if it was done with a different partner). You may also
use any code provided by this semester’s 6.031 staff.
你可以使用外部代码,只要:
- 所有同学都可以访问这个资料
- 进行了合理的引用
- 作业允许你这么做
特别地,如果作业要求你“实现 X 功能”,你就必须自己实现 X 功能,不能复用他人的。
你们组不能复用其他组的代码和思路,无论是其他组是当前学期还是以往学期的同学。
You may also use material from external sources, so long as: (1) the
material is available to all students in the class; (2) you give proper
attribution; and (3) the assignment itself allows it. In particular, if
the assignment says “implement X,” then you must create your own X, not
reuse someone else’s. Finally, your group may not reuse designs, ideas,
or code created by another group, in this semester or previous
semesters.
即使修改网络上的代码很常见 Although it is common practice to adapt code examples found on the web,
-
你不能抄袭其他同学的代码。你的同学不是一个合法的代码来源。
You should never copy code from other students. Your peers are not considered an authorized source. -
你不能简单地复用网上的代码。就像学术写作,你可以采用别人的思路,但是你也要把自己的理解加进去。
You should not simply re-use code as the solution to an assignment. Like academic writing, your code can incorporate the ideas of others but should reflect your original approach to the problem.
引用代码的例子 Examples of citing code sources
例子一 Example 1:
在 Apache 项目的源码的 PluginProxyUtil 类中,开发者引用了论坛的 URL,作者和时间:
In describing the class PluginProxyUtil in the Apache Project source
code, the developer cites the source as a post in a forum and includes
the URL, author and date:
/**
* A utility class that gives applets the ability to detect proxy host settings.
* This was adapted from a post from Chris Forster on 20030227 to a Sun Java
* forum here:
* http://forum.java.sun.com/thread.jspa?threadID=364342&tstart=120
[…]
*/
(来源:Apache Project 源代码 http://svn.apache.org 于 2019 年 7 月获取)
(Source: Apache Project source code http://svn.apache.org retrieved in
July 2019.)
例子二 Example 2:
在 Google Chrome stack_trace_win 的 OutputTraceToStream 函数中,开发者引用了 Microsoft Developer Network 并且附带了 URL:
In the function OutputTraceToStream in the Google Chrome stack_trace_win
source code, the developer cites the source code as the Microsoft
Developer Network and includes a URL:
(来源:https://github.com/adobe/chromium/blob/master/base/debug/stack_trace_win.cc 于 2019 年 7 月获取)
(Source:
https://github.com/adobe/chromium/blob/master/base/debug/stack_trace_win.cc
retrieved in July 2019.)
引用附有开源许可证的代码的例子 Example of open-source-licensed code:
在 Google Chrome stack_trace_win 代码的开头,可以看到版权声明和开源许可证的引用:
At the top of the Google Chrome stack_trace_win source file, note the
copyright and reference to the open source license:
// Copyright (c) 2011 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
如果你把这个代码加入到你的程序中,你需要遵守 Chromium 作者的开源许可证协议中的条款。虽然这个开源许可证只要求你在重分发的时候复制一份版权声明和许可证,一个好习惯是无论是否要求,你都要复制它的版权声明到代码中,和/或把它的许可证放到代码目录的文件中。这样的话,如果你在将来想要重分发你的代码,就很容易检查知识产权相关的问题。
If you incorporate this code into a program, you should follow the terms
outlined in The Chromium Authors' open source license file, which is
shown below. While this license only requires that you duplicate the
copyright and license if you are redistributing the code, it is good
practice to always duplicate the copyright in your code, and/or store
the license in a file with the code. This way, if you want to
redistribute the code later, intellectual property reviewing becomes
much easier.
// Copyright (c) 2014 The Chromium Authors. All rights reserved.
//
// Redistribution and use in source and binary forms, with or without
// modification, are permitted provided that the following conditions are
// met:
//
//* Redistributions of source code must retain the above copyright
// notice, this list of conditions and the following disclaimer.
//* Redistributions in binary form must reproduce the above
// copyright notice, this list of conditions and the following disclaimer
// in the documentation and/or other materials provided with the
// distribution.
//* Neither the name of Google Inc. nor the names of its
// contributors may be used to endorse or promote products derived from
// this software without specific prior written permission.
//
// THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
// "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
// LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
// A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
// OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
// SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
// LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
// DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
// THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
// (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
// OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
//
(来源:The Chromium Authors license file https://src.chromium.org/viewvc/chrome/trunk/src/LICENSE 于 2019 年 7 月获取)
(Source: The Chromium Authors license file
https://src.chromium.org/viewvc/chrome/trunk/src/LICENSE retrieved in
July 2019.)
Archive 中 COMMON 符号的链接问题
背景
最近看到一个 issue: irssi 1.4.1 fails to build on darwin arm64,它的现象是,链接的时候会报错:
Undefined symbols for architecture arm64:
"_current_theme", referenced from:
_format_get_text_theme in libfe_common_core.a(formats.c.o)
_format_get_text in libfe_common_core.a(formats.c.o)
_strip_codes in libfe_common_core.a(formats.c.o)
_format_send_as_gui_flags in libfe_common_core.a(formats.c.o)
_window_print_daychange in libfe_common_core.a(fe-windows.c.o)
_printformat_module_dest_charargs in libfe_common_core.a(printtext.c.o)
_printformat_module_gui_args in libfe_common_core.a(printtext.c.o)
...
"_default_formats", referenced from:
_format_find_tag in libfe_common_core.a(formats.c.o)
_format_get_text_theme_args in libfe_common_core.a(formats.c.o)
_printformat_module_dest_args in libfe_common_core.a(printtext.c.o)
_printformat_module_gui_args in libfe_common_core.a(printtext.c.o)
ld: symbol(s) not found for architecture arm64
代码 themes.c 定义了这两个全局变量:
并且 themes.c 编译出来的 themes.c.o 也在 archive 文件中:
并且 themes.c.o 也定义了这两个符号:
$ objdump -t src/fe-common/core/libfe_common_core.a.p/themes.c.o | grep COM
0000000000000008 01 COM 00 0300 _current_theme
0000000000000008 01 COM 00 0300 _default_formats
0000000000000008 01 COM 00 0300 _themes
那么,问题在哪呢?看起来,链接的时候提供了 libfe_common_core.a 的参数,并且 .a 里面也有 themes.c.o,我们要找的符号也有定义,那么为什么会出现 Undefined symbols 的问题呢?
答案出在 COMMON 符号上。
COMMON 符号
COMMON 符号的原因和原理,详细可以见 MaskRay 的博客 All about COMMON symbols,里面从链接器的角度很详细地讲述了这个问题。
简单来说,COMMON 符号的引入是为了和 Fortran 进行互操作。它在 C 中对应了没有初始化语句的全局变量。实际上到最后,还是会保存到 .bss 段中,默认清零。所以:
两个语句最终结果是类似的,只不过第一个是 COMMON Symbol,第二个就是普通的 GLOBAL Symbol。
这看起来和 Undefined symbols 错误还是没有关系。问题在哪?
Archive
静态库通常是以 Archive 的方式给出,后缀是 .a。它实际上是一堆 .o 打包的集合,外加一个索引,即单独保存一个表,保存了每个 .o 定义了哪些符号。这样的好处是找符号的时候,不用遍历 .o,而是直接在索引里面找相关的符号。
为了创建一个 Archive,Linux 上可以用 ar 命令:
其中 c 表示 create,r 表示插入(和覆盖)。
macOS 上要用 libtool -static 来创建 Archive:
否则链接的时候会报错:
ld: warning: ignoring file libxxx.a, building for macOS-arm64 but attempting to link with file built for unknown-unsupported file format
然后用 ar t 命令就可以看 Archive 有哪些内容:
可以用 nm --print-armap 命令查看 Archive 的索引:
$ nm --print-armap libxxx.a
Archive index:
symbol1 in a.o
symbol2 in b.o
symbol3 in c.o
a.o:
0000000000000000 T symbol1
所以我们已经了解了 Archive 的情况:它是多个 .o 文件的集合,并且实现了索引。链接的时候,会通过索引来找 .o,而不是遍历所有的 .o 文件。
链接问题
那么,回到一开始的链接问题,既然我们已经确认了,.o 文件中定义了符号,并且这个 .o 也确实在 .a 文件中,那就只剩下最后一个可能了:索引里面没有这个符号。
用 nm --print-armap 命令尝试,发现上面的 _default_formats 和 _current_theme 只在对应的 .o 中有定义,在 Archive index 部分是没有的。
网友 @ailin-nemui 指出了这个问题,并且提供了一个链接:OS X linker unable to find symbols from a C file which only contains variables。它讲了很重要的一点,是 macOS 的 ar/ranlib/libtool 版本默认情况下不会为 COMMON 符号创建索引。所以,解决方案也很明确了:
- 第一种 不要创建 COMMON 符号:添加编译选项
-fno-common,这个选项在比较新的编译器里都是默认了 - 第二种 为 COMMON 符号创建索引:用
libtool -static -c命令,其中-c选项就是打开为 COMMON 符号创建索引 - 第三种 修改代码:给全局变量设置一个初始化值
这样,这个问题就得到了妥善的解决。
附录
下面是 macOS libtool manpage 中写的相关文档:
-c Include common symbols as definitions with respect to the table of contents. This is seldom the intended behavior for linking from
a library, as it forces the linking of a library member just because it uses an uninitialized global that is undefined at that point
in the linking. This option is included only because this was the original behavior of ranlib. This option is not the default.
NVIDIA 驱动和 CUDA 安装速查
背景
最近在 Ubuntu 上配置 NVIDIA 驱动和 CUDA 环境的次数比较多,在此总结一下整个流程,作为教程供大家学习。
配置 NVIDIA APT 源
Ubuntu 源有自带的 NVIDIA 驱动版本,但这里我们要使用 NVIDIA 的 APT 源。首先,我们要访问 https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=20.04&target_type=deb_network,在网页中选择我们的系统,例如:
- Operating System: Linux
- Architecture: x86_64
- Distribution: Ubuntu
- Version: 20.04
- Installer Type: deb (network)
此时,下面就会显示一些命令,复制下来执行:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
最后一步的 sudo apt-get -y install cuda 可以不着急安装,我们在后面再来讨论 CUDA 版本的问题。
NVIDIA 驱动
配置好源以后,接下来,我们就要安装 NVIDIA 驱动了。首先,我们要选取一个 NVIDIA 版本,选择的标准如下:
- 驱动版本需要支持所使用的显卡
- 驱动版本需要支持所使用的 CUDA 版本
这些信息在网络上都可以查到,也可以参考 NVIDIA 驱动和 CUDA 版本信息速查。
假如我们已经选择了要安装 470.129.06 版本,那么,我们接下来要确认一下 NVIDIA 的 APT 源的版本名称:
在输出的结果中搜索 470.129.06,找到 Version: 470.129.06-0ubuntu1,下面写了 APT-Sources: https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64 Packages,这就说明这个版本是从 NVIDIA 的 APT 源来的。
所以,我们要用 470.129.06-0ubuntu1,而不是 470.129.06-0ubuntu0.20.04.1,后者是 Ubuntu 源自带的,我们要用前者。
接下来,指定版本安装驱动:
如果系统里已经安装了其他版本的 nvidia 驱动,可能会出现冲突。这时候,只需要把冲突的包也写在要安装的包里即可,例如:
sudo apt install nvidia-utils-470=470.129.06-0ubuntu1 cuda-drivers=470.129.06-1 cuda-drivers-470=470.129.06-1 nvidia-driver-470=470.129.06-0ubuntu1 libnvidia-gl-470=470.129.06-0ubuntu1 libnvidia-compute-470=470.129.06-0ubuntu1 libnvidia-decode-470=470.129.06-0ubuntu1 libnvidia-encode-470=470.129.06-0ubuntu1 libnvidia-ifr1-470=470.129.06-0ubuntu1 libnvidia-fbc1-470=470.129.06-0ubuntu1 libnvidia-common-470=470.129.06-0ubuntu1 nvidia-kernel-source-470=470.129.06-0ubuntu1 nvidia-dkms-470=470.129.06-0ubuntu1 nvidia-kernel-common-470=470.129.06-0ubuntu1 libnvidia-extra-470=470.129.06-0ubuntu1 nvidia-compute-utils-470=470.129.06-0ubuntu1 xserver-xorg-video-nvidia-470=470.129.06-0ubuntu1 libnvidia-cfg1-470=470.129.06-0ubuntu1 nvidia-settings=470.129.06-0ubuntu1 libxnvctrl0=470.129.06-0ubuntu1 nvidia-modprobe=470.129.06-0ubuntu1
最终,我们要保证,系统里面所有 nvidia 驱动相关的包都是同一个版本:
$ sudo apt list --installed | grep nvidia
libnvidia-cfg1-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed,automatic]
libnvidia-common-470/unknown,now 470.129.06-0ubuntu1 all [installed,automatic]
libnvidia-compute-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
libnvidia-decode-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
libnvidia-encode-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
libnvidia-extra-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed,automatic]
libnvidia-fbc1-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
libnvidia-gl-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
libnvidia-ifr1-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
nvidia-compute-utils-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed,automatic]
nvidia-dkms-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
nvidia-driver-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed]
nvidia-fabricmanager-470/unknown,now 470.129.06-1 amd64 [installed,automatic]
nvidia-kernel-common-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed,automatic]
nvidia-kernel-source-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed,automatic]
nvidia-modprobe/unknown,now 470.129.06-0ubuntu1 amd64 [installed,upgradable to: 515.48.07-0ubuntu1]
nvidia-settings/unknown,now 470.129.06-0ubuntu1 amd64 [installed,upgradable to: 515.48.07-0ubuntu1]
nvidia-utils-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed,automatic]
xserver-xorg-video-nvidia-470/unknown,now 470.129.06-0ubuntu1 amd64 [installed,automatic]
接下来,为了防止 apt 升级的时候顺手破坏了一致的版本,我们要把包固定在一个版本里:
如果有其他 nvidia 包说要自动升级,也可以类似地固定住。
CUDA
CUDA 实际上是绿色软件,把整个目录放在任意一个目录,都可以使用。
安装 CUDA 的方式有很多,我们可以用 APT 安装全局的,也可以用 Spack 或者 Anaconda 安装到本地目录。实际上这些安装过程都是把同样的文件复制到不同的地方而已。
如果要安装全局的话,还是推荐用 NVIDIA 的 APT 源,以安装 CUDA 11.1 为例:
那么 CUDA 就会安装到 /usr/local/cuda-11.1 目录下。如果想要用 nvcc,我们可以手动把它加到 PATH 环境变量中。
CUDA 是可以多版本共存的,比如你可以把 CUDA 11.1 到 CUDA 11.7 一口气都装了。不过注意,CUDA 对 NVIDIA 驱动有版本要求,所以有一些可能会不满足 APT 的版本要求;同时,CUDA 对编译器版本有要求,所以如果系统还是 Ubuntu 16.04 或者 18.04,赶紧升级吧。
NVIDIA Container Toolkit
命令:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \
&& \
sudo apt-get update
切换 ConnectX-4 为以太网模式
背景
最近在给机房配置网络,遇到一个需求,就是想要把 ConnectX-4 当成以太网卡用,它既支持 Infiniband,又支持 Ethernet,只不过默认是 Infiniband 模式,所以需要用 mlxconfig 工具来做这个切换。
切换方法
在 Using mlxconfig 文档中,写了如何切换网卡为 Infiniband 模式:
$ mlxconfig -d /dev/mst/mt4103_pci_cr0 set LINK_TYPE_P1=1 LINK_TYPE_P2=1
Device #1:
----------
Device type: ConnectX3Pro
PCI device: /dev/mst/mt4103_pci_cr0
Configurations: Next Boot New
LINK_TYPE_P1 ETH(2) IB(1)
LINK_TYPE_P2 ETH(2) IB(1)
Apply new Configuration? ? (y/n) [n] : y
Applying... Done!
-I- Please reboot machine to load new configurations.
那么,我们只需要反其道而行之,设置模式为 ETH(2) 即可。
MST 安装
要使用 mlxconfig,就需要安装 MFT(Mellanox Firmware Tools)。我们用的是 Debian bookworm,于是要下载 DEB:
wget https://www.mellanox.com/downloads/MFT/mft-4.20.1-14-x86_64-deb.tgz
unar mft-4.20.1-14-x86_64-deb.tgz
cd mft-4.20.1-14-x86_64-deb
UPDATE 2022-10-28: 现在最新版本 mft-4.21.0-99 已经修复了下面出现的编译问题。
wget https://www.mellanox.com/downloads/MFT/mft-4.21.0-99-x86_64-deb.tgz
unar mft-4.21.0-99-x86_64-deb.tgz
cd mft-4.21.0-99-x86_64-deb
尝试用 sudo ./install.sh 安装,发现 dkms 报错。查看日志,发现是因为内核过高(5.18),有函数修改了用法,即要把 pci_unmap_single 的调用改为 dma_unmap_single,并且修改第一个参数,如 linux commit a2e759612e5ff3858856fe97be5245eecb84e29b 指出的那样:
- pci_unmap_single(dev->pci_dev, dev->dma_props[i].dma_map, DMA_MBOX_SIZE, DMA_BIDIRECTIONAL);
+ dma_unmap_single(&dev->pci_dev->dev, dev->dma_props[i].dma_map, DMA_MBOX_SIZE, DMA_BIDIRECTIONAL);
修改完以后,手动 sudo dkms install kernel-mft-dkms/4.20.1,发现就编译成功了。再手动安装一下 mft 并启动服务:
$ sudo dpkg -i DEBS/mft_4.20.1-14_amd64.deb
$ sudo mst start
Starting MST (Mellanox Software Tools) driver set
Loading MST PCI module - Success
[warn] mst_pciconf is already loaded, skipping
Create devices
Unloading MST PCI module (unused) - Success
$ sudo mst status
MST modules:
------------
MST PCI module is not loaded
MST PCI configuration module loaded
MST devices:
------------
/dev/mst/mtxxxx_pciconf0 - PCI configuration cycles access.
domain:bus:dev.fn=0000:xx:xx.0 addr.reg=yy data.reg=zz cr_bar.gw_offset=-1
Chip revision is: 00
既然已经安装好了,最后执行 mlxconfig 即可切换为以太网:
$ sudo mlxconfig -d /dev/mst/mtxxxx_pciconf0 set LINK_TYPE_P1=2 LINK_TYPE_P2=2
Device #1:
----------
Device type: ConnectX4
Name: REDACTED
Description: ConnectX-4 VPI adapter card; FDR IB (56Gb/s) and 40GbE; dual-port QSFP28; PCIe3.0 x8; ROHS R6
Device: /dev/mst/mtxxxx_pciconf0
Configurations: Next Boot New
LINK_TYPE_P1 IB(1) ETH(2)
LINK_TYPE_P2 IB(1) ETH(2)
Apply new Configuration? (y/n) [n] : y
Applying... Done!
-I- Please reboot machine to load new configurations.
显示各个配置可能的选项和内容:sudo mlxconfig -d /dev/mst/mtxxxx_pciconf0 show_confs
整个安装流程在仓库 https://github.com/jiegec/mft-debian-bookworm 中用脚本实现。
UPDATE: 太新的 MFT 版本不支持比较旧的网卡,例如 4.22.1-LTS 支持 ConnectX-3,但 4.26.1-LTS 就不支持了。
VMware ESXi
如果要在 ESXi 上把网卡改成以太网模式,可以参考下面的文档:
- https://docs.nvidia.com/networking/pages/releaseview.action?pageId=15049813
- https://docs.nvidia.com/networking/plugins/servlet/mobile?contentId=15051769#content/view/15051769
命令(ESXi 7.0U3):
scp *.vib root@esxi:/some/path
esxcli software vib install -v /some/path/MEL_bootbank_mft_4.21.0.703-0.vib
esxcli software vib install -v /some/path/MEL_bootbank_nmst_4.21.0.703-1OEM.703.0.0.18434556.vib
reboot
/opt/mellanox/bin/mst start
/opt/mellanox/bin/mst status -vv
/opt/mellanox/bin/mlxfwmanager --query
/opt/mellanox/bin/mlxconfig -d mt4115_pciconf0 set LINK_TYPE_P1=2 LINK_TYPE_P2=2
reboot
然后就可以看到网卡了。
rsyslog 收集远程日志
背景
最近在运维的时候发现网络设备(如交换机)有一个远程发送日志的功能,即可以通过 syslog udp 协议发送日志到指定的服务器。为此,可以在服务器上运行 rsyslog 并收集日志。
rsyslog 配置
默认的 rsyslog 配置是收集系统本地的配置,因此我们需要编写一个 rsyslog 配置,用于收集远程的日志。
首先复制 /etc/rsyslog.conf 到 /etc/rsyslog-remote.conf,然后修改:
- 注释掉
imuxsock和imklog相关的 module 加载 - 去掉
imudp和imtcp相关的注释,这样就会监听在相应的端口上 - 修改
$WorkDirectory,例如$WorkDirectory /var/spool/rsyslog-remote,防止与已有的 rsyslog 冲突 - 注释
$IncludeConfig,防止引入了不必要的配置 - 注释所有已有的
RULES下面的配置 - 添加如下配置:
这样,就会按照来源的 IP 地址进行分类,然后都写入到 /var/log/rsyslog-remote/x.x.x.x.log 文件里。最后的 /etc/rsyslog-remote.conf 内容如下:
module(load="imudp")
input(type="imudp" port="514" address="1.2.3.4")
module(load="imtcp")
input(type="imtcp" port="514" address="1.2.3.4")
$FileOwner root
$FileGroup adm
$FileCreateMode 0640
$DirCreateMode 0755
$Umask 0022
$WorkDirectory /var/spool/rsyslog-remote
$template FromIp,"/var/log/rsyslog-remote/%FROMHOST-IP%.log"
*.* ?FromIp
此外,还需要手动创建 /var/spool/rsyslog-remote 和 /var/log/rsyslog-remote 目录。
systemd service
最后,写一个 systemd service /etc/systemd/system/rsyslog-remote.service 让它自动启动:
[Unit]
ConditionPathExists=/etc/rsyslog-remote.conf
Description=Remote Syslog Service
[Service]
Type=simple
PIDFile=/var/run/rsyslogd-remote.pid
ExecStart=/usr/sbin/rsyslogd -n -f /etc/rsyslog-remote.conf -i /var/run/rsyslogd-remote.pid
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
立即启动并设置开机启动:
这样就实现了远程日志的收集。
logrotate 设置
为了防止日志太多,还需要配置 logrotate。
复制 /etc/logrotate.d/rsyslog 到 /etc/logrotate.d/rsyslog-remote,然后修改开头为 /var/log/rsyslog-remote/*.log 即可,路径和上面对应:
/var/log/rsyslog-remote/*.log
{
rotate 4
weekly
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
/usr/lib/rsyslog/rsyslog-remote-rotate
endscript
}
注意脚本 /usr/lib/rsyslog/rsyslog-remote 也需要复制一份到 /usr/lib/rsyslog/rsyslog-remote-rotate,然后修改一下 systemd service 名字:
一键脚本
完成以上所有事情的一键脚本:
# assuming bash
# please change ip address below
cat > /etc/rsyslog-remote.conf << 'EOL'
module(load="imudp")
input(type="imudp" port="514" address="1.2.3.4")
module(load="imtcp")
input(type="imtcp" port="514" address="1.2.3.4")
$FileOwner root
$FileGroup adm
$FileCreateMode 0640
$DirCreateMode 0755
$Umask 0022
$WorkDirectory /var/spool/rsyslog-remote
$template FromIp,"/var/log/rsyslog-remote/%FROMHOST-IP%.log"
*.* ?FromIp
EOL
mkdir -p /var/spool/rsyslog-remote
mkdir -p /var/log/rsyslog-remote
cat > /etc/systemd/system/rsyslog-remote.service << 'EOL'
[Unit]
ConditionPathExists=/etc/rsyslog-remote.conf
Description=Remote Syslog Service
[Service]
Type=simple
PIDFile=/var/run/rsyslogd-remote.pid
ExecStart=/usr/sbin/rsyslogd -n -f /etc/rsyslog-remote.conf -i /var/run/rsyslogd-remote.pid
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
EOL
systemctl daemon-reload
systemctl enable --now rsyslog-remote
cat > /etc/logrotate.d/rsyslog-remote << 'EOL'
/var/log/rsyslog-remote/*.log
{
rotate 4
weekly
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
/usr/lib/rsyslog/rsyslog-remote-rotate
endscript
}
EOL
cat > /usr/lib/rsyslog/rsyslog-remote-rotate << 'EOL'
#!/bin/sh
if [ -d /run/systemd/system ]; then
systemctl kill -s HUP rsyslog-remote.service
fi
EOL
chmod +x /usr/lib/rsyslog/rsyslog-remote-rotate
syslog 客户端配置
配好服务端以后,很多服务都支持远程 syslog 功能:
- iBMC: 维护诊断->告警上报->Syslog 报文通知
- Supermicro BMC: Configuration->Syslog
- 交换机:见 常用交换机命令
-
ESXi: 见 Configuring syslog on ESXi:
参考文档
「教学」Wishbone 总线协议
本文的内容已经整合到知识库中。
背景
最近在研究如何把 Wishbone 总线协议引入计算机组成原理课程,因此趁此机会学习了一下 Wishbone 的协议。
总线
总线是什么?总线通常用于连接 CPU 和外设,为了更好的兼容性和可复用性,会想到能否设计一个统一的协议,其中 CPU 实现的是发起请求的一方(又称为 master),外设实现的是接收请求的一方(又称为 slave),那么如果要添加外设、或者替换 CPU 实现,都会变得比较简单,减少了许多适配的工作量。
那么,我们来思考一下,一个总线协议需要包括哪些内容?对于 CPU 来说,程序会读写内存,读写内存就需要以下几个信号传输到内存:
- 地址(
addr):例如 32 位处理器就是 32 位地址,或者按照内存的大小计算地址线的宽度 - 数据(
w_data和r_data):分别是写数据和读数据,宽度通常为 32 位 或 64 位,也就是一个时钟周期可以传输的数据量 - 读还是写(
we):高表示写,低表示读 - 字节有效(
be):例如为了实现单字节写,虽然w_data可能是 32 位宽,但是实际写入的是其中的一个字节
除了请求的内容以外,为了表示 CPU 想要发送请求,还需要添加 valid 信号:高表示发送请求,低表示不发送请求。很多时候,外设的速度比较慢,可能无法保证每个周期都可以处理请求,因此外设可以提供一个 ready 信号:当 valid=1 && ready=1 的时候,发送并处理请求;当 valid=1 && ready=0 的时候,表示外设还没有准备好,此时 CPU 需要一直保持 valid=1 不变,等到外设准备好后,valid=1 && ready=1 请求生效。
简单总结一下上面的需求,可以得到 master 和 slave 端分别的信号列表。这次,我们在命名的时候用 _o 表示输出、_i 表示输入,可以得到 master 端(CPU 端)的信号:
clock_i:时钟输入valid_o:高表示 master 想要发送请求ready_i:高表示 slave 准备好处理请求addr_o:master 想要读写的地址we_o:master 想要读还是写data_o:master 想要写入的数据be_o:master 读写的字节使能,用于实现单字节写等data_i:slave 提供给 master 的读取的数据
除了时钟都是输入以外,把上面其余的信号输入、输出对称一下,就可以得到 slave 端(外设端)的信号:
clock_i:时钟输入valid_i:高表示 master 想要发送请求ready_o:高表示 slave 准备好处理请求addr_i:master 想要读写的地址we_i:master 想要读还是写data_i:master 想要写入的数据be_i:master 读写的字节使能,用于实现单字节写等data_o:slave 提供给 master 的读取的数据
根据我们上面设计的自研总线,可以绘制出下面的波形图(以 master 的信号为例):
a周期:此时valid_o=1 && ready_i=1说明有请求发生,此时we_o=1说明是一个写操作,并且写入地址是addr_o=0x01,写入的数据是data_o=0x12b周期:此时valid_o=0 && ready_i=0说明无事发生c周期:此时valid_o=1 && ready_i=0说明 master 想要从地址 0x02(addr_o=0x02)读取数据(we_o=0),但是 slave 没有接受(ready_i=0)d周期:此时valid_o=1 && ready_i=1说明有请求发生,master 从地址 0x02(addr_o=0x02)读取数据(we_o=0),读取的数据为 0x34(data_i=0x34)e周期:此时valid_o=0 && ready_i=0说明无事发生f周期:此时valid_o=1 && ready_i=1说明有请求发生,master 向地址 0x03(addr_o=0x03)写入数据(we_o=1),写入的数据为 0x56(data_i=0x56)g周期:此时valid_o=1 && ready_i=1说明有请求发生,master 从地址 0x01(addr_o=0x01)读取数据(we_o=0),读取的数据为 0x12(data_i=0x12)h周期:此时valid_o=1 && ready_i=1说明有请求发生,master 向地址 0x02(addr_o=0x02)写入数据(we_o=1),写入的数据为 0x9a(data_i=0x9a)
从上面的波形中,可以有几点观察:
- master 想要发起请求的时候,就设置
valid_o=1;当 slave 可以接受请求的时候,就设置ready_i=1;在valid_o=1 && ready_i=1时视为一次请求 - 如果 master 发起请求,同时 slave 不能接收请求,即
valid_o=1 && ready_i=0,此时 master 要保持addr_owe_odata_o和be_o不变,直到请求结束 - 当 master 不发起请求的时候,即
valid_o=0,此时总线上的信号都视为无效数据,不应该进行处理;对于读操作,只有在valid_o=1 && ready_i=1时data_i上的数据是有效的 - 可以连续多个周期发生请求,即
valid_o=1 && ready_i=1连续多个周期等于一,此时是理想情况,可以达到总线最高的传输速度
Wishbone Classic Standard
首先我们来看最简单的 Wishbone 版本 Wishbone Classic Standard。其设计思路和上面的自研总线非常相似,让我们来看看它的信号,例如 master 端(CPU 端)的信号:
CLK_I: 时钟输入,即自研总线中的clock_iSTB_O:高表示 master 要发送请求,即自研总线中的valid_oACK_I:高表示 slave 处理请求,即自研总线中的ready_iADR_O:master 想要读写的地址,即自研总线中的addr_oWE_O:master 想要读还是写,即自研总线中的we_oDAT_O:master 想要写入的数据,即自研总线中的data_oSEL_O:master 读写的字节使能,即自研总线中的be_oDAT_I:master 从 slave 读取的数据,即自研总线中的data_iCYC_O:总线的使能信号,无对应的自研总线信号
还有一些可选信号,这里就不赘述了。可以看到,除了最后一个 CYC_O,其他的信号其实就是我们刚刚设计的自研总线。CYC_O 的可以认为是 master 想要占用 slave 的总线接口,在常见的使用场景下,直接认为 CYC_O=STB_O。它的用途是:
- 占用 slave 的总线接口,不允许其他 master 访问
- 简化 interconnect 的实现
把上面自研总线的波形图改成 Wishbone Classic Standard,就可以得到:
Wishbone Classic Pipelined
上面的 Wishbone Classic Standard 协议非常简单,但是会遇到一个问题:假设实现的是一个 SRAM 控制器,它的读操作有一个周期的延迟,也就是说,在这个周期给出地址,需要在下一个周期才可以得到结果。在 Wishbone Classic Standard 中,就会出现下面的波形:
a周期:master 给出读地址 0x01,此时 SRAM 控制器开始读取,但是此时数据还没有读取回来,所以ACK_I=0b周期:此时 SRAM 完成了读取,把读取的数据 0x12 放在DAT_I并设置ACK_I=1c周期:master 给出下一个读地址 0x02,SRAM 要重新开始读取d周期:此时 SRAM 完成了第二次读取,把读取的数据 0x34 放在DAT_I并设置ACK_I=1
从波形来看,功能没有问题,但是每两个周期才能进行一次读操作,发挥不了最高的性能。那么怎么解决这个问题呢?我们在 a 周期给出第一个地址,在 b 周期得到第一个数据,那么如果能在 b 周期的时候给出第二个地址,就可以在 c 周期得到第二个数据。这样,就可以实现流水线式的每个周期进行一次读操作。但是,Wishbone Classic Standard 要求 b 周期时第一次请求还没有结束,因此我们需要修改协议,来实现流水线式的请求。
实现思路也很简单:既然 Wishbone Classic Standard 认为 b 周期时,第一次请求还没有结束,那就让第一次请求提前在 a 周期完成,只不过它的数据要等到 b 周期才能给出。实际上,这个时候的一次读操作,可以认为分成了两部分:首先是 master 向 slave 发送读请求,这个请求在 a 周期完成;然后是 slave 向 master 发送读的结果,这个结果在 b 周期完成。为了实现这个功能,我们进行如下修改:
- 添加
STALL_I信号:CYC_O=1 && STB_O=1 && STALL_I=0表示进行一次读请求 - 修改
ACK_I信号含义:CYC_O=1 && STB_O=1 && ACK_I=1表示一次读响应
进行如上修改以后,我们就得到了 Wishbone Classic Pipelined 总线协议。上面的两次连续读操作波形如下:
a周期:master 请求读地址 0x01,slave 接收读请求(STALL_O=0)b周期:slave 返回读请求结果 0x12,并设置ACK_I=1;同时 master 请求读地址 0x02,slave 接收读请求(STALL_O=0)c周期:slave 返回读请求结果 0x34,并设置ACK_I=1;master 不再发起请求,设置STB_O=0d周期:所有请求完成,master 设置CYC_O=0
这样我们就实现了一个每周期进行一次读操作的 slave。
参考文档
Nix Cookbook
背景
最近在尝试 NixOS 和在 macOS 上跑 Nix,下面记录一些我在使用过程中遇到的一些小问题和解决思路。
NixOS
全局配置
NixOS 的全局配置路径:/etc/nixos/configuration.nix 和 /etc/nixos/hardware-configuration.nix
应用更新后的全局配置:
应用 Flakes 配置文件并显示变化:
#!/usr/bin/env python3
import os
user = os.getenv("USER")
home = f"/nix/var/nix/profiles/"
old = home + os.readlink(f"{home}system")
os.system("sudo nixos-rebuild switch --flake .")
new = home + os.readlink(f"{home}system")
os.system(f"nix store diff-closures {old} {new}")
更新大版本
如果要更新 NixOS 21.11 到 22.05:
nix-channel --list
nix-channel --add https://nixos.org/channels/nixos-22.05 nixos
nixos-rebuild switch --upgrade
可以考虑改或者不改 /etc/nixos/configuration.nix 中的 system.stateVersion。
常用配置
常用的 NixOS 配置:
# Enable XFCE
services.xserver.enable = true;
services.xserver.desktopManager.xfce.enable = true;
# System wide packages
environment.systemPackages = with pkgs; [
xxx
];
# Fish shell
programs.fish.enable = true;
users.users.xxx = {
shell = pkgs.fish;
}
# Command not found
programs.command-not-found.enable = true;
# Steam gaming
nixpkgs.config.allowUnfree = true;
programs.steam.enable = true;
# NOPASSWD for sudo
security.sudo.wheelNeedsPassword = false;
# QEMU guest
services.qemuGuest.enable = true;
services.spice-vdagentd.enable = true;
# XRDP
services.xrdp.enable = true;
services.xrdp.defaultWindowManager = "xfce4-session";
services.xrdp.openFirewall = true;
# OpenSSH server
services.openssh.enable = true;
# Udev rules for Altera USB Blaster
services.udev.packages = with pkgs; [
usb-blaster-udev-rules
];
VSCode Remote
VSCode Remote 会在远程的机器上运行一个预编译的 nodejs,运行的时候会因为路径问题无法执行。
解决方法在 NixOS Wiki 上有,具体来说,首先,需要安装 nodejs:
然后,用软链接来覆盖 nodejs:
这样就可以正常使用 VSCode Remote 了。
Home Manager
Home Manager 描述用户默认看到的程序,而 NixOS 的配置是所有用户的。
配置文件
配置文件:~/.config/nixpkgs/home.nix
应用配置文件:
应用 Flakes 配置文件并显示变化:
#!/usr/bin/env python3
import os
user = os.getenv("USER")
home = f"/nix/var/nix/profiles/per-user/{user}/"
old = home + os.readlink(f"{home}profile")
os.system("home-manager switch --flake .")
new = home + os.readlink(f"{home}profile")
os.system(f"nix store diff-closures {old} {new}")
常用配置
常用的 Home Manager 配置:
# Allow unfree
nixpkgs.config.allowUnfree = true;
nixpkgs.config.allowUnfreePredicate = (pkg: true);
# User wide packages
home.packages = with pkgs; [
xxx
];
生成 Nix 配置 ~/.config/nix/nix.conf:
# Enable flakes & setup TUNA mirror
nix.package = pkgs.nix;
nix.settings = {
experimental-features = [ "nix-command" "flakes" ];
substituters = [ "https://mirrors.tuna.tsinghua.edu.cn/nix-channels/store" "https://cache.nixos.org/"];
};
Shell 环境变量和 PATH:
离线 Home Manager 文档(用 home-manager-help 命令打开):
覆盖依赖版本
设置 JVM 程序依赖的 JDK 版本:
# Maven with java 11
home.packages = with pkgs; [
(maven.override { jdk = jdk11; })
];
# Many packages with the same JDK
home.packages =
let java = pkgs.jdk11; in
with pkgs; [
(maven.override { jdk = java; })
(sbt.override { jre = java; })
];
具体的参数命名要看 nixpkgs 上对应的包的开头。
配置 direnv
direnv 是一个 shell 插件,它的用途是进入目录的时候,会根据 .envrc 来执行命令,比如自动进入 nix-shell 等。配置:
然后在工程路径下,编写 .envrc:
那么,在 shell 进入目录的时候,就会自动获得 nix-shell 的环境变量。
配置 fish
可以在 home manager 配置中编写 fish 配置,这样它会自动生成 ~/.config/fish/config.fish 文件:
programs.fish.enable = true;
programs.fish.shellAliases = {
a = "b";
};
programs.fish.shellInit = ''
# Rust
set -x PATH ~/.cargo/bin $PATH
'';
配置 git
同理,也可以在 home manager 中配置 git:
programs.git.enable = true;
programs.git.lfs.enable = true;
programs.git.userName = "Someone";
programs.git.userEmail = "mail@example.com";
programs.git.extraConfig = {
core = {
quotepath = false;
};
pull = {
rebase = false;
};
};
programs.git.ignores = [
".DS_Store"
];
生成的 git 配置在 ~/.config/git/config 和 ~/.config/git/ignore。
Flakes
Flakes 可以用来把多个系统的 nix 配置写在一个项目中。例如:
{
description = "Nix configuration";
inputs = {
home-manager.url = "github:nix-community/home-manager/release-22.05";
nixpkgs.url = "github:nixos/nixpkgs/nixos-22.05";
};
outputs = { self, nixpkgs, home-manager }:
{
nixosConfigurations.xxxx = nixpkgs.lib.nixosSystem {
system = "x86_64-linux";
modules = [
./nixos/xxxx/configuration.nix
home-manager.nixosModules.home-manager
./nixos/xxxx/home.nix
];
};
homeConfigurations.yyyy = home-manager.lib.homeManagerConfiguration {
configuration = import ./home-manager/yyyy/home.nix;
system = "aarch64-darwin";
homeDirectory = "/Users/yyyy";
username = "yyyy";
stateVersion = "22.05";
};
};
}
然后,要应用上面的配置,运行:
这样就可以把若干个系统上的 nix 配置管理在一个仓库中了。
实用工具
nixpkgs-fmt
nixpkgs-fmt 用来格式化 Nix 代码。
search.nixos.org
search.nixos.org 可以搜索 nixpkgs 上的各种包,也可以看到不同平台支持情况。缺点是看不出是否 unfree 和 broken,并且一些 darwin os-specific 的包不会显示。
nix-tree
显示各个 nix derivation 的硬盘占用和依赖关系。
打包
可以很容易地编写 default.nix 来给自己的项目打包。
CMake
对于一个简单的 cmake 程序,可以按照如下的格式编写 default.nix:
with import <nixpkgs> {};
stdenv.mkDerivation {
name = "xyz";
version = "1.0";
src = ./.;
nativeBuildInputs = [
cmake
];
buildInputs = [
xxx
yyy
];
}
可以用 nix-build 命令来构建,生成结果会在当前目录下创建一个 result 的软链接,里面就是安装目录。
由于 nix-build 的时候也会创建 build 目录,为了防止冲突,建议开发的时候用其他的名字。
Qt
对于 Qt 项目来说,由于有不同的 Qt 大版本,所以实现的时候稍微复杂一些,要拆成两个文件,首先是 default.nix:
这里就表示用 qt5 来编译,那么编写 xxx.nix 的时候,传入的 qtbase 等库就是 qt5 的版本:
{ stdenv, qtbase, wrapQtAppsHook, cmake }:
stdenv.mkDerivation {
name = "xxx";
version = "1.0";
src = ./.;
nativeBuildInputs = [
cmake
wrapQtAppsHook # must-have for qt apps
];
buildInputs = [
qtbase
];
}
实际测试中发现,运行的程序可能会报告 Could not initialize GLX 的错误,这个方法可以通过 wrapProgram 添加环境变量解决:
# https://github.com/NixOS/nixpkgs/issues/66755#issuecomment-657305962
# Fix "Could not initialize GLX" error
postInstall = ''
wrapProgram "$out/bin/xxx" --set QT_XCB_GL_INTEGRATION none
'';
开发环境
除了打包以外,通常还会在 shell.nix 中定义开发环境需要的包:
然后可以用 nix-shell 来进入开发环境。如果不希望外面的环境变量传递进去,可以用 nix-shell --pure。
搜索
按名字搜索一个包:
Nixpkgs
可以从 TUNA 镜像上先 clone 一份到本地,然后再添加 github 上游作为 remote。
从本地 nixpkgs 安装:
从本地 nixpkgs 编译:
从本地 nixpkgs 开一个 shell:
Nixpkgs 的分支
Nixpkgs 开发分支主要有三个:
- master
- staging-next
- staging
发 PR 的时候,如果需要重新编译的包比较多,就要往 staging 提交;比较少,就往 staging-next 提交。
CI 会自动把 master 合并到 staging-next,也会把 staging-next 合并到 staging。这样 master 上的改动也会同步到 staging 上。
维护者会定义把 staging 手动合并到 staging-next,然后手动合并 staging-next 到 staging。这个的周期一般是一周多,可以在 pr 里搜索 staging-next。
Hydra 会编译 master 分支和 staging-next 分支上的包,不会编译 staging 分支上的包。同理,binary cache 上前两个分支上有的,而 staging 上没有的。
参考:https://nixos.org/manual/nixpkgs/stable/#submitting-changes-commit-policy
提交贡献
注意事项:
- 升级一些比较老的写法,例如 mkDerivation -> stdenv.mkDerivation,Qt 的 hook
- 引入 patch 的时候,建议先向上游提 PR,如果合并了,就直接用上游的 commit;如果没有合并,退而求其次可以用 pr 的 patch;如果没有提 PR 的渠道,或者上游的 commit 无法应用到当前的版本,或者这个 patch 没有普适性,再写本地的 patch;注释里要写打 patch 的原因和相关的 issue 链接,什么时候不再需要这个 patch,并且起个名字
- 不知道 SHA256 的时候,可以注释掉或者随便写一个,这样 nix build 的时候会重新下载,然后把正确的显示出来
- 对于有命令的包,可以添加 testVersion 测试
- 长时间没有 review 的 pr,可以在 discourse 上回复帖子。
- 更新之前,可以搜索一下,有没有相关的 issue 或者 pr;如果有 issue,新建 pr 的时候要提一下
一些常见的问题:
- 编译器打开
-fno-common后,可能会导致一些链接问题 - Darwin 上的 clang 没有打开 LTO,也没有打开 Universal 支持
- AArch64 Darwin 上的 gfortran 的 stack protector 不工作,需要把 hardening 关掉
- 当编译报错是
-Werror导致的时候,按照 warning 类型在 NIX_CFLAGS_COMPILE 中添加-Wno-error=warning-type - configure 版本较老,需要引入 autoreconfHook
阅读文档:https://github.com/NixOS/nixpkgs/blob/master/doc/contributing/quick-start.chapter.md 和 https://github.com/NixOS/nixpkgs/blob/master/doc/contributing/coding-conventions.chapter.md
VSCode
可以安装 https://github.com/nix-community/vscode-nix-ide/ 插件,配合 rnix-lsp 来使用。
杂项
可以用 nix copy 命令在不同机器的 store 之间复制文件,见 nix copy - copy paths between Nix stores。
在 libvirt 中运行 RISC-V 虚拟机
背景
我在 libvirt 中跑了几个 KVM 加速的虚拟机,然后突发奇想,既然 libvirt 背后是 qemu,然后 qemu 是支持跨指令集的,那是否可以让 libvirt 来运行 RISC-V 架构的虚拟机?经过一番搜索,发现可以跑 ARM:How To: Running Fedora-ARM under QEMU,既然如此,我们也可以试试用 libvirt 来运行 RV64 虚拟机。
准备 rootfs
第一步是根据 Debian 的文档 Creating a riscv64 chroot 来创建 rootfs,然后再用 virt-make-fs 来打包。
首先是用 mmdebstrap 来生成一个 chroot:
$ sudo mkdir -p /tmp/riscv64-chroot
$ sudo apt install mmdebstrap qemu-user-static binfmt-support debian-ports-archive-keyring
$ sudo mmdebstrap --architectures=riscv64 --include="debian-ports-archive-keyring" sid /tmp/riscv64-chroot "deb http://deb.debian.org/debian-ports sid main" "deb http://deb.debian.org/debian-ports unreleased main"
进入 chroot 以后,进行一些配置:
$ sudo chroot /tmp/riscv64-chroot
$ apt update
$ apt install linux-image-riscv64 u-boot-menu vim
# set root password
$ passwd
然后修改 /etc/default/u-boot 文件,添加如下的配置:
# change ro to rw, set root device
U_BOOT_PARAMETERS="rw noquiet root=/dev/vda1"
# fdt is provided by qemu
U_BOOT_FDT_DIR="noexist"
然后运行 u-boot-update 生成配置文件 /boot/extlinux/extlinux.conf。
到这里,rootfs 已经准备完毕。
尝试在 QEMU 中启动
接下来,可以参考 Setting up a riscv64 virtual machine 先启动一个 qemu 来测试一下是否可以正常工作:
首先制作一个 qcow2 格式的镜像:
$ sudo virt-make-fs --partition=gpt --type=ext4 --size=+10G --format=qcow2 /tmp/riscv64-chroot rootfs.qcow2
$ qemu-img info rootfs.qcow2
image: rootfs.qcow2
file format: qcow2
virtual size: 11.4 GiB (12231971328 bytes)
disk size: 1.33 GiB
cluster_size: 65536
Format specific information:
compat: 1.1
compression type: zlib
lazy refcounts: false
refcount bits: 16
corrupt: false
extended l2: false
然后启动 qemu,配置好 OpenSBI 和 U-Boot 的路径:
$ sudo apt install qemu-system-misc opensbi u-boot-qemu
$ sudo qemu-system-riscv64 -nographic -machine virt -m 8G \
-bios /usr/lib/riscv64-linux-gnu/opensbi/generic/fw_jump.elf \
-kernel /usr/lib/u-boot/qemu-riscv64_smode/uboot.elf \
-object rng-random,filename=/dev/urandom,id=rng0 -device virtio-rng-device,rng=rng0 \
-append "console=ttyS0 rw root=/dev/vda1" \
-device virtio-blk-device,drive=hd0 -drive file=rootfs.qcow2,format=qcow2,id=hd0 \
-device virtio-net-device,netdev=usernet -netdev user,id=usernet,hostfwd=tcp::22222-:22
如果系统可以正常工作,看到下面的输出,下一步就可以配置 libvirt 了。
[ 6.285024] Run /init as init process
Loading, please wait...
Starting version 251.1-1
[ 7.743714] virtio_ring: module verification failed: signature and/or required key missing - tainting kernel
[ 8.071762] virtio_blk virtio1: [vda] 23838189 512-byte logical blocks (12.2 GB/11.4 GiB)
[ 8.181210] vda: vda1
Begin: Loading essential drivers ... done.
Begin: Running /scripts/init-premount ... done.
Begin: Mounting root file system ... Begin: Running /scripts/local-top ... done.
Begin: Running /scripts/local-premount ... done.
Warning: fsck not present, so skipping root file system
[ 9.003143] EXT4-fs (vda1): mounted filesystem with ordered data mode. Quota mode: none.
done.
Begin: Running /scripts/local-bottom ... done.
Begin: Running /scripts/init-bottom ... done.
[ 9.754151] Not activating Mandatory Access Control as /sbin/tomoyo-init does not exist.
[ 9.808860] random: fast init done
[ 10.651361] systemd[1]: Inserted module 'autofs4'
[ 10.735574] systemd[1]: systemd 251.1-1 running in system mode (+PAM +AUDIT +SELINUX +APPARMOR +IMA +SMACK +SECCOMP +GCRYPT -GNUTLS +OPENSSL +ACL +BLKID +CURL +ELFUTILS +FIDO2 +IDN2 -IDN +IPTC +KMOD +LIBCRYPTSETUP +LIBFDISK +PCRE2 -PWQUALITY -P11KIT -QRENCODE +TPM2 +BZIP2 +LZ4 +XZ +ZLIB +ZSTD -BPF_FRAMEWORK -XKBCOMMON +UTMP +SYSVINIT default-hierarchy=unified)
[ 10.736902] systemd[1]: Detected architecture riscv64.
Welcome to Debian GNU/Linux bookworm/sid!
配置 libvirt
首先,打开 virt-manager,在向导中,可以在下拉菜单选择自定义的架构,选择 riscv64 和 virt,然后选择 Import existing disk image,找到刚刚创建的 qcow2 文件。
创建好以后,我们还不能直接启动,因为此时还没有配置 OpenSBI 和 U-Boot。由于 virt-aa-helper 会检查 OpenSBI 和 U-Boot 的路径,要求它们不能在 /usr/lib 路径下:
/*
* Don't allow access to special files or restricted paths such as /bin, /sbin,
* /usr/bin, /usr/sbin and /etc. This is in an effort to prevent read/write
* access to system files which could be used to elevate privileges. This is a
* safety measure in case libvirtd is under a restrictive profile and is
* subverted and trying to escape confinement.
*
* Note that we cannot exclude block devices because they are valid devices.
* The TEMPLATE file can be adjusted to explicitly disallow these if needed.
*
* RETURN: -1 on error, 0 if ok, 1 if blocked
*/
const char * const restricted[] = {
"/bin/",
"/etc/",
"/lib",
"/lost+found/",
"/proc/",
"/sbin/",
"/selinux/",
"/sys/",
"/usr/bin/",
"/usr/lib",
"/usr/sbin/",
"/usr/share/",
"/usr/local/bin/",
"/usr/local/etc/",
"/usr/local/lib",
"/usr/local/sbin/"
};
所以,我手动把 U-Boot 和 OpenSBI 复制一份到 /var/lib 下:
$ sudo mkdir -p /var/lib/custom
$ cd /var/lib/custom
$ sudo cp -r /usr/lib/u-boot/qemu-riscv64_smode .
$ sudo cp -r /usr/lib/riscv64-linux-gnu .
此时,再去配置 libvirt 的 XML 配置文件:
<os>
<type arch='riscv64' machine='virt'>hvm</type>
<loader type='rom'>/var/lib/custom/riscv64-linux-gnu/opensbi/generic/fw_jump.elf</loader>
<kernel>/var/lib/custom/qemu-riscv64_smode/uboot.elf</kernel>
<boot dev='hd'/>
</os>
其余部分不用修改。在下面可以看到 virt-manager 已经设置好了 qemu-system-riscv64:
<devices>
<emulator>/usr/bin/qemu-system-riscv64</emulator>
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/path/to/rootfs.qcow2'/>
<target dev='vda' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/>
</disk>
保存以后直接启动,就完成了在 libvirt 中运行 Debian RV64 虚拟机的目的。
「教学」异步 SRAM 时序
背景
在一些场合里,我们会使用异步的(即没有时钟信号的)外部 SRAM 来存储数据,而我们经常使用的很多外部接口都是同步接口(即有时钟信号的接口),比如 SPI 和 I2C 等等,UART 虽然是异步,但是它速度很低,不怎么需要考虑时序的问题。所以在 FPGA 上编写一个正确的异步 SRAM 控制器是具有一定的挑战的。
寄存器时序
考虑到读者可能已经不记得寄存器的时序了,这里首先来复习一下 setup 和 hold 的概念。如果你已经比较熟悉了,可以直接阅读下一节。
寄存器在时钟的上升沿(下图的 a)进行采样,为了保证采样的稳定性,输入引脚 D 需要在时钟上升沿之前 \(t_{su}\) 的时刻(下图的 b)到时钟上升沿之后 \(t_h\) 的时刻(下图的 c)保持稳定,输出引脚 Q 会在时钟上升沿之后 \(t_{cko}\) 的时刻(下图的 d)变化:
接口
首先我们来看看异步 SRAM 的接口。下文中,采用 IS61WV102416BLL-10TLI 和 AS7C34098A-10TCN 作为例子:

可以看到,它有 20 位的地址,16 位的数据,若干个控制信号,同时只能进行读或者写(简称 1RW)。它没有时钟信号,所以是异步 SRAM。
时序
对于一个同步接口,我们通常只需要给一个满足时钟周期的时钟,然后通过约束文件保证 setup 和 hold 条件满足即可。但是对于异步接口,由于输出的时候没有时钟,我们需要更小心地完成这件事情。
读时序
首先来看一下比较简单的读时序:
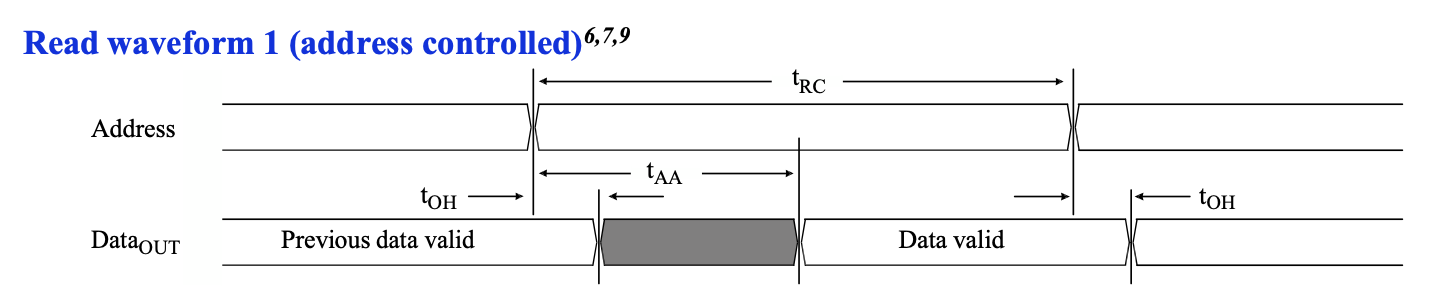
可以看到地址和数据的关系:首先是地址需要稳定 \(t_{RC}\) 的时间,那么数据合法的范围是地址稳定的初始时刻加上 \(t_{AA}\),到地址稳定的结束时刻加上 \(t_{OH}\)。我们再来看一下这几个时间的范围:
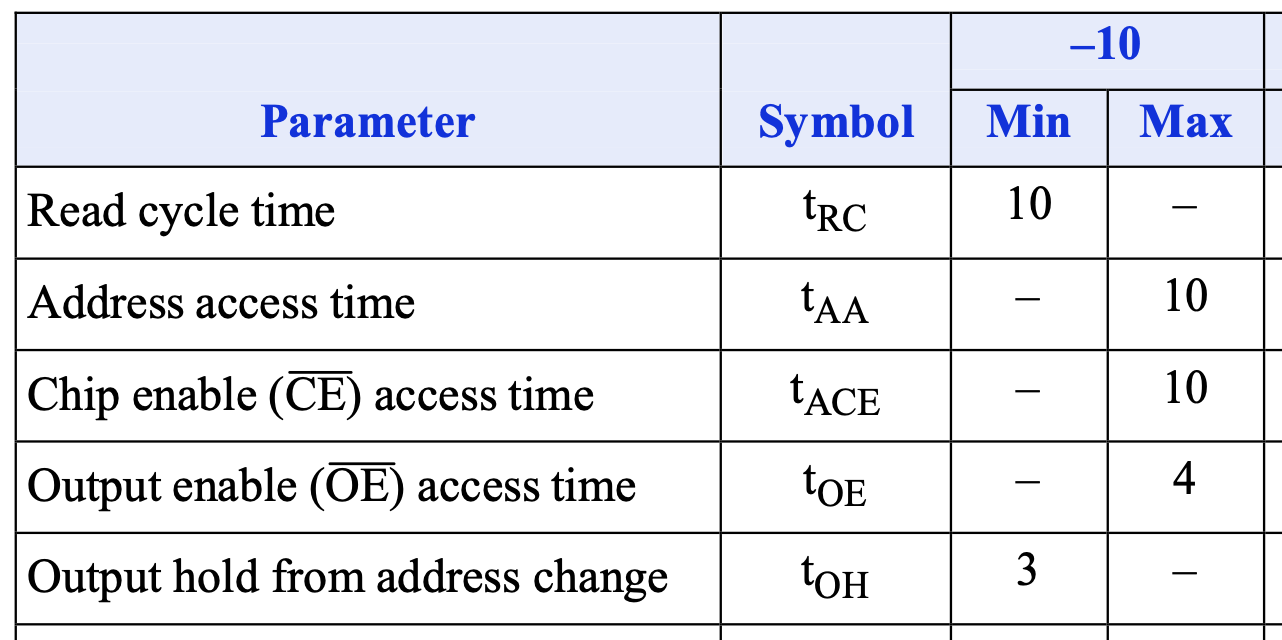
首先可以看到读周期时间 \(t_{RC}\) 至少是 10ns,这对应了型号中最后的数字,这表示了这个 SRAM 最快的读写速度。比较有意思的是 \(t_{AA}\) 最多是 10ns,刚好和 \(t_{RC}\) 的最小值相等。
接下来我们考虑一下如何为 SRAM 控制器时序读取的功能。看到上面的波形图,大概可以想到几条设计思路:
- 首先输出要读取的地址,为了让它稳定(\(t_{RC}\) 的时间内不能变化),要直接从 FPGA 内部寄存器的输出端口输出
- 等待若干个周期,确保数据已经稳定,在满足 FPGA 内部寄存器的 setup 和 hold 约束的情况下,把结果保存在内部寄存器中。
简单起见,先设置一个非常快的 SRAM 控制器频率:500MHz,每个周期 2ns,假如在 a 时刻地址寄存器输出了当前要读取的地址,那么数据会在一段时间后变为合法。这里 a->b 是读取周期时间 \(t_{RC}\),a->c 是地址到数据的延迟 \(t_{AA}\),b->d 是地址改变后数据的保持时间 \(t_{OH}\)。
那么根据这个图,很自然的想法是,我先给出地址,然后数周期,数了五个周期后,此时 \(t_{RC}=10\mathrm{ns}\),然后我就在 e 的上升沿上把输入数据锁存到寄存器中,例如下面的波形:
这个时候 data_reg 的 setup 时间是 c->e,hold 时间是 e->d。从图中看起来还有很多的余量,但如果考虑最坏情况,\(t_{AA}=10\mathrm{ns}\),就会变成下面的波形:
这个时候在 e 时刻不再满足 setup 约束。这个问题在仿真中,可能会“极限操作”表现为没有问题,但实际上,地址从 FPGA 到 SRAM 的延迟有:
- 地址寄存器从时钟上升沿到输出变化的延迟:\(T_{CKO}=0.40\mathrm{ns}\)
- 寄存器输出到 FPGA 输出引脚的延迟:\(T_{IOOP} \in (2.56, 3.80)\mathrm{ns}\)
- FPGA 输出的地址信号通过信号线到 SRAM 的延迟:\(T_{PD}\)
数据从 SRAM 到 FPGA 的延迟有:
- SRAM 数据信号通过信号线到 FPGA 的延迟:\(T_{PD}\)
- FPGA 的输入引脚到内部寄存器输入端的延迟:\(T_{IOPI}=1.26ns\)
- FPGA 内部寄存器的 setup 时间:\(T_{AS}=0.07\mathrm{ns}\)
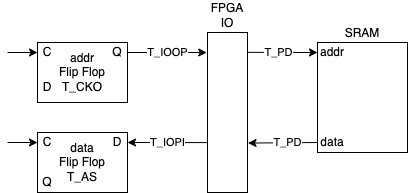
上面的一些数据可以从 Artix-7 FPGA Datasheet 里查到,取的是速度等级 -3 的数据,IO 标准是 LVCMOS33。其中寄存器到 FPGA 输入输出引脚的延迟,实际上由两部分组成:从寄存器到 IOB(IO Block)的延迟,以及 IOB 到 FPGA 输入输出引脚的延迟。我们把地址寄存器的输出作为地址输出,这样 Vivado 就会把寄存器放到 IOB,于是可以忽略寄存器到 IOB 的延迟,详情可以阅读文档 Successfully packing a register into an IOB with Vivado。
把上面一串加起来,已经有大概 4 到 5ns 了。考虑了延迟以后,上面的图可能实际上是这个样子:
考虑了这么多实际的延迟因素以后,会发现这个事情并不简单,需要预先估计出数据在大概什么时候稳定,这时候才能保证数据寄存器上保存的数据是正确的。
转念一想,我们的 SRAM Controller 肯定不会跑在 500MHz 这么高的频率下。假如采用 100MHz,可以每两个周期进行一次读操作:
此时在 b 时钟上边沿对 data_fpga 采样就可以保证满足时序的要求。注意这里第二个周期(上图的 a)不能给出第二次读取的地址,否则稳定时间太短,不满足 hold 约束。
如果频率继续降低,使得一个时钟周期大于 \(t_{AA}\) 加上各种延迟和 setup 时间,那就可以每个周期进行一次读操作:
此时在 a 时钟上升沿上,对 data_fpga 进行采样,并且输出下一次读请求的地址。
写时序
接下来再看看写时序。写时序涉及的信号更多,更加复杂一些,但好处是信号都是从 FPGA 到 SRAM,因此考虑延迟的时候会比较简单,比如上面读时序中需要考虑从 FPGA 到 SRAM 的地址,再从 SRAM 到 FPGA 的数据的路径。时序图如下:
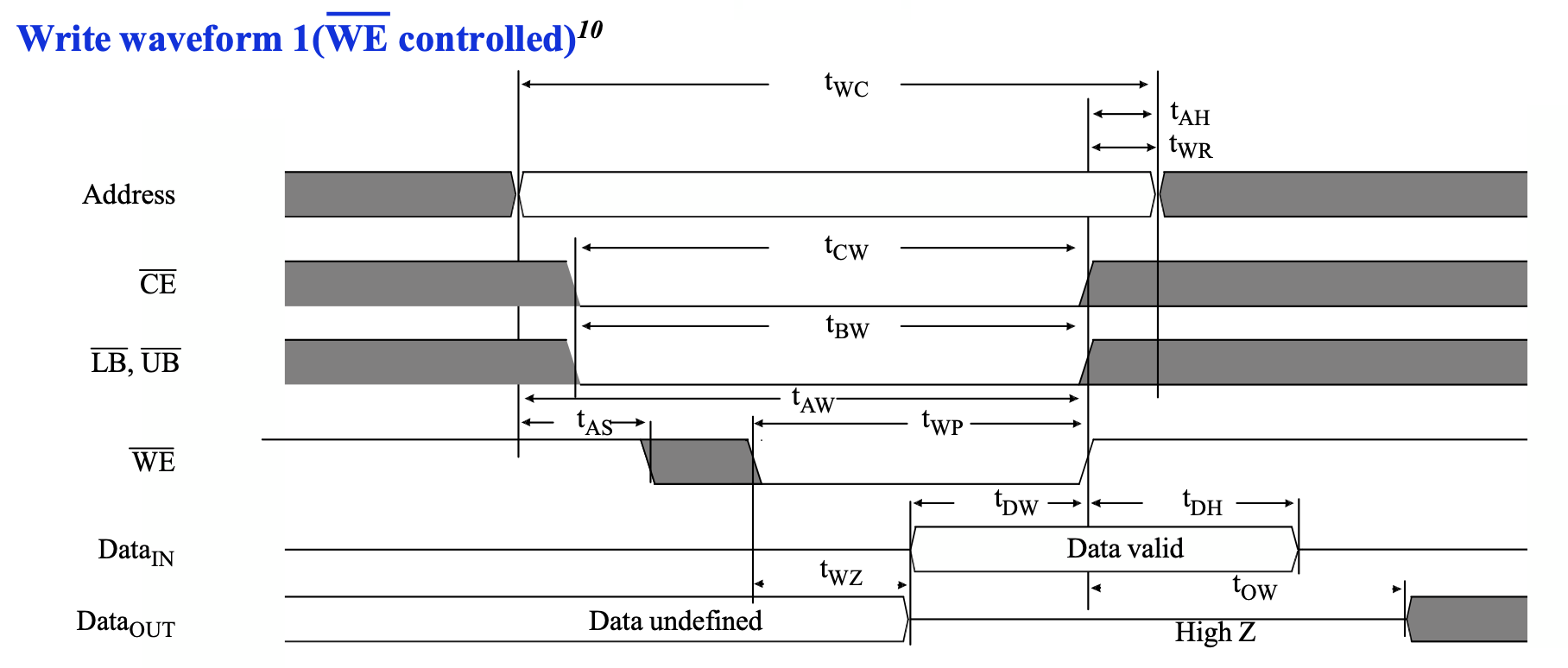
这个写的时序图,从时间顺序来看有这么几件事情按顺序发生:
- 地址保持稳定
- 经过 \(t_{AS}\) 时间后,写使能信号 \(\overline{WE}\) 变为低电平,表示“开始写入操作”,此时地址是稳定的
- 经过 \(t_{WP}\) 时间后,写使能信号\(\overline{WE}\) 变为高电平,表示“结束写入操作”,此时地址和数据都是稳定的,并且数据满足 setup(\(t_{DW}\))和 hold(\(t_{DH}\))约束
- 继续保持地址稳定,直到已经稳定了 \(t_{WC}\) 时间
这些数据的范围如下:
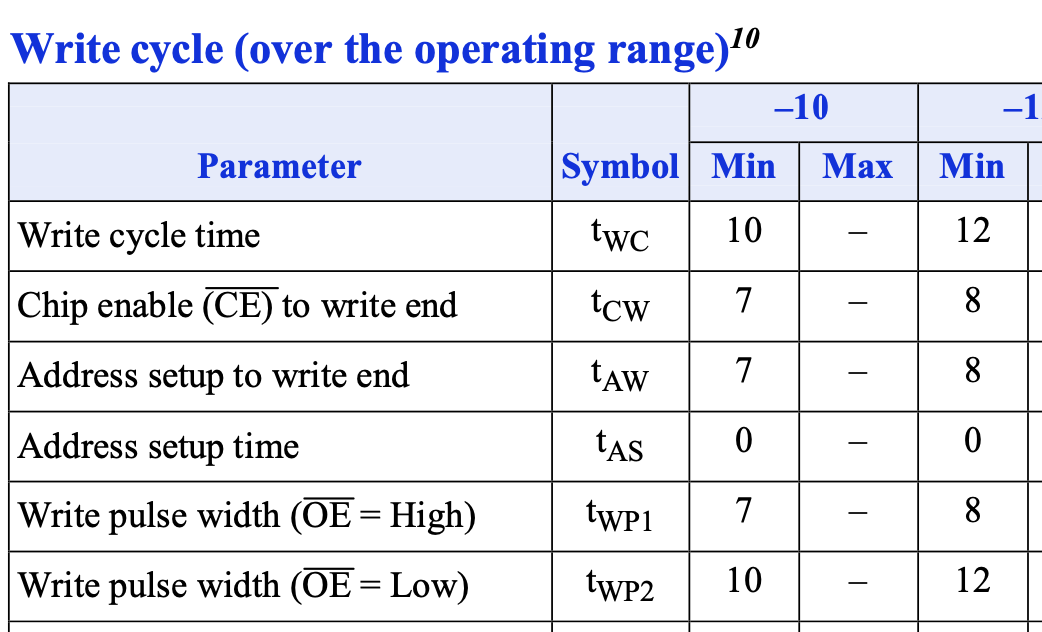
根据上面的分析,还是先考虑一个 500MHz 的 SRAM 控制器。控制器要写入的话,可以按照如下的顺序操作:
- 第一个周期(下图的
a)先输出要写入的地址和数据,并且设置好ce_n,oe_n,we_n,ub_n和lb_n。 - 第二个周期(下图的
c)设置 \(\overline{WE}\) 为低电平,这是为了满足 \(t_{AS}\) (下图的a -> c)的条件 - 等待若干个周期(下图的
c -> d),直到 \(t_{WP}\) (下图的c -> d)和 \(t_{AW}\) (下图的a -> d)时间满足条件 - 设置 \(\overline{WE}\) 为高电平(下图的
d),等待若干个周期(下图的d -> b),直到满足图中的 \(t_{WC}\) (下图的a -> b)时间满足条件
这时候你可能有点疑惑,之前分析读时序的时候,考虑了那么多延迟,为什么写的时候不考虑了?这是因为,写的时候所有的信号都是从 FPGA 输出到 SRAM 的,只要这些信号都是从寄存器直接输出,它们的延迟基本是一样的,所以在 FPGA 侧是什么波形,在 SRAM 侧也是什么波形(准确来说,数据信号因为输出是三态门,所以延迟会稍微高一点,但是由于数据信号的时序余量很大,这个额外的延迟可以忽略不计)。
这时候你可能又有一个疑惑了,在阅读 Datasheet 后发现,\(t_{AS}\) 最小是 0ns,那能不能在上图的 a 时刻就输出 we_n=0?答案是不行,虽然从波形上来看,是在同一个时钟上升沿更新,但实际上会有一微小的延迟差距,可能导致 we_n 在 addr 之前变化,这时候就可能导致 SRAM 观察到的地址是不稳定的。
再考虑一个比较实际的 100MHz 主频 SRAM 控制器,按照如下的波形,则是每三个周期进行一次写操作:
如果觉得这样做太过保守,想要提升性能,有如下几个可能的思路:
- 让
we_n=0在时钟下降沿输出,但是编写的时候需要比较谨慎,比如先设置一个上升沿触发的寄存器,然后用另一个寄存器在下降沿对这个寄存器进行采样,再输出。 - 用一个更高频率的时钟驱动
we_n的寄存器。 - 用 FPGA 提供的
ODELAY自定义输出延迟原语,设置一个固定的输出延迟,比如 1ns。 - 用
ODDR原语,人为地添加一个大约 0.50ns 的延迟。 - 对
we_n设置一个最小的输出延迟(设置了一个很大的 hold),并且不允许输出we_n的寄存器放在 IOB 中(否则无法人为增加信号传播的路径长度)。约束:set_output_delay -clock [get_clocks sram_clk] -min -5.00 [get_ports sram_we_n]和set_property IOB FALSE [get_cells top/sram_controller/we_n_reg]。这里的信号和寄存器名称需要按照实际情况修改,第二个不允许放置在 IOB 的约束也可以在 Verilog 代码中用(* IOB = "FALSE" *)来实现。
按照上面的思路实现,下面是可能达到的效果:
单周期:
双周期:
PL241 SRAM 控制器
刚刚我们已经设计好了我们的 SRAM 控制器,再让我们来看看 ARM 提供的 SRAM 控制器时序是怎么样的:ARM 文档提供了 PrimeCell AHB SRAM/NOR Memory Controller (PL241) 的时序图。
读时序:

它第一个周期设置了 ce_n=0 和 addr,等待一个周期后,设置 oe_n=0,再等待两个周期,得到数据。
写时序:

它第一个周期设置了 ce_n=0 addr 和 data,等待一个周期后,设置 we_n=0,等待两个周期,再设置 we_n=1,这样就完成了写入。这和我们的实现是类似的:等待一个额外的周期,保证满足 we_n 下降时地址已经是稳定的。ARM 的文档里也写了如下的备注:
The timing parameter tWC is controlling the deassertion of smc_we_n_0. You can
use it to vary the hold time of smc_cs_n_0[3:0], smc_add_0[31:0] and
smc_data_out_0[31:0]. This differs from the read case where the timing
parameter tCEOE controls the delay in the assertion of smc_oe_n_0.
Additionally, smc_we_n_0 is always asserted one cycle after smc_cs_n_0[3:0] to
ensure the address bus is valid.
参考文档
- 1M x 16 HIGH-SPEED ASYNCHRONOUS CMOS STATIC RAM WITH 3.3V SUPPLY
- Artix-7 FPGAs Data Sheet: DC and AC Switching Characteristics
- Timing constraints for an Asynchronous SRAM interface
- Successfully packing a register into an IOB with Vivado
- How to verify whether an I/O register is packed into IOB
- PrimeCell AHB SRAM/NOR Memory Controller (PL241) - Memory interface operation
「教学」ACE 缓存一致性协议
本文的内容已经整合到知识库中。
背景
最近几天分析了 TileLink 的缓存一致性协议部分内容,见TileLink 总线协议分析,趁此机会研究一下之前尝试过研究,但是因为缺少一些基础知识而弃坑的 ACE 协议分析。
下面主要参考了 IHI0022E 的版本,也就是 AXI4 对应的 ACE 版本。
回顾
首先回顾一下一个缓存一致性协议需要支持哪些操作。对于较上一级 Cache 来说,它需要这么几件事情:
- 读或写 miss 的时候,需要请求这个缓存行的数据,并且更新自己的状态,比如读取到 Shared,写入到 Modified 等。
- 写入一个 valid && !dirty 的缓存行的时候,需要升级自己的状态,比如从 Shared 到 Modified。
- 需要 evict 一个 valid && dirty 的缓存行的时候,需要把 dirty 数据写回,并且降级自己的状态,比如 Modified -> Shared/Invalid。如果需要 evict 一个 valid && !dirty 的缓存行,可以选择通知,也可以选择不通知下一级。
- 收到 snoop 请求的时候,需要返回当前的缓存数据,并且更新状态。
- 需要一个方法来通知下一级 Cache/Interconnect,告诉它第一和第二步完成了。
如果之前看过我的 TileLink 分析,那么上面的这些操作对应到 TileLink 就是:
- 读或写 miss 的时候,需要请求这个缓存行的数据(发送 AcquireBlock,等待 GrantData),并且更新自己的状态,比如读取到 Shared,写入到 Modified 等。
- 写入一个 valid && !dirty 的缓存行的时候,需要升级自己的状态(发送 AcquirePerm,等待 Grant),比如从 Shared 到 Modified。
- 需要 evict 一个 valid && dirty 的缓存行的时候,需要把 dirty 数据写回(发送 ReleaseData,等待 ReleaseAck),并且降级自己的状态,比如 Modified -> Shared/Invalid。如果需要 evict 一个 valid && !dirty 的缓存行,可以选择通知(发送 Release,等待 ReleaseAck),也可以选择不通知下一级。
- 收到 snoop 请求的时候(收到 Probe),需要返回当前的缓存数据(发送 ProbeAck/ProbeAckData),并且更新状态。
- 需要一个方法(发送 GrantAck)来通知下一级 Cache/Interconnect,告诉它第一和第二步完成了。
秉承着这个思路,再往下看 ACE 的设计,就会觉得很自然了。
Cache state model
首先来看一下 ACE 的缓存状态模型,我在之前的缓存一致性协议分析中也分析过,它有这么五种,就是 MOESI 的不同说法:
- UniqueDirty: Modified
- SharedDirty: Owned
- UniqueClean: Exclusive
- SharedClean: Shared
- Invalid: Invalid
文档中的定义如下:
- Valid, Invalid: When valid, the cache line is present in the cache. When invalid, the cache line is not present in the cache.
- Unique, Shared: When unique, the cache line exists only in one cache. When shared, the cache line might exist in more than one cache, but this is not guaranteed.
- Clean, Dirty: When clean, the cache does not have responsibility for updating main memory. When dirty, the cache line has been modified with respect to main memory, and this cache must ensure that main memory is eventually updated.
大致理解的话,Unique 表示只有一个缓存有这个缓存行,Shared 表示有可能有多个缓存有这个缓存行;Clean 表示它不负责更新内存,Dirty 表示它负责更新内存。下面的很多操作都是围绕这些状态进行的。
文档中也说,它支持 MOESI 的不同子集:MESI, ESI, MEI, MOESI,所以也许在一个简化的系统里,一些状态可以不存在,实现会有所不同。
Channel usage examples
到目前为止,我还没有介绍 ACE 的信号,但是我们可以尝试一下,如果我们是协议的设计者,我们要如何添加信号来完成这个事情。
首先考虑上面提到的第一件事情:读或写 miss 的时候,需要请求这个缓存行的数据,并且更新自己的状态,比如读取到 Shared,写入到 Modified 等。
我们知道,AXI 有 AR 和 R channel 用于读取数据,那么遇到读或者写 miss 的时候,可以在 AR channel 上捎带一些信息,让下一级的 Interconnect 知道自己的意图是读还是写,然后 Interconnect 就在 R channel 上返回数据。
那么,具体要捎带什么信息呢?我们“不妨”用这样一种命名方式:操作 + 目的状态,比如我读 miss 的时候,需要读取数据,进入 Shared 状态,那就叫 ReadShared;我写 miss 的时候,需要读取数据(通常写入缓存的只是一个缓存行的一部分,所以先要把完整的读进来),那就叫 ReadUnique。这个操作可以编码到一个信号中,传递给 Interconnect。
再来考虑上面提到的第二件事情:写入一个 valid && !dirty 的缓存行的时候,需要升级自己的状态,比如从 Shared 到 Modified。
这个操作,需要让 Interconnect 把其他缓存中的这个缓存行数据清空,并且把自己升级到 Unique。根据上面的 操作 + 目的状态 的命名方式,我们可以命名为 CleanUnique,即把其他缓存都 Clean 掉,然后自己变成 Unique。
接下来考虑上面提到的第三件事情:需要 evict 一个 valid && dirty 的缓存行的时候,需要把 dirty 数据写回,并且降级自己的状态,比如 Modified -> Shared/Invalid。
按照前面的 操作 + 目的状态 命名法,可以命名为 WriteBackInvalid。ACE 实际采用的命名是 WriteBack。
终于到了第四件事情:收到 snoop 请求的时候,需要返回当前的缓存数据,并且更新状态。
既然 snoop 是从 Interconnect 发给 Master,在已有的 AR R AW W B channel 里没办法做这个事情,不然会打破已有的逻辑。那不得不添加一对 channel,比如我规定一个 AC channel 发送 snoop 请求,规定一个 C channel 让 master 发送响应,这样就可以了。这就相当于 TileLink 里面的 B channel(Probe 请求)和 C channel(ProbeAck 响应)。实际 ACE 和刚才设计的实际有一些区别,把 C channel 拆成了两个:CR 用于返回所有响应,CD 用于返回那些需要数据的响应。这就像 AW 和 W 的关系,一个传地址,一个传数据;类似地,CR 传状态,CD 传数据。
那么,接下来考虑一下 AC channel 上要发送什么请求呢?我们回顾一下上面已经用到的请求类型:需要 snoop 的有 ReadShared,ReadUnique 和 CleanUnique,不需要 snoop 的有 WriteBack。那我们直接通过 AC channel 把 ReadShared,ReadUnique 和 CleanUnique 这三种请求原样发送给需要 snoop 的 cache 那里就可以了。
Cache 在 AC channel 收到这些请求的时候,可以做相应的动作。由于 MOESI 协议下同样的请求可以有不同的响应方法,这里就不细说了。
这时候我们已经基本把 ACE 协议的信号和大题的工作流程推导出来了。哦,我们还忘了第五件事情:需要一个方法来通知下一级 Cache/Interconnect,告诉它第一和第二步完成了。TileLink 添加了一个额外的 E channel 来做这个事情,ACE 更加粗暴:直接用一对 RACK 和 WACK 信号来分别表示最后一次读和写已经完成。
关于 WACK 和 RACK 详见 What's the purpose for WACK and RACK for ACE and what's the relationship with WVALID and RVALID? 的讨论。
总结
到这里就暂时不继续分析了,其他的很多请求类型是服务于更多场景,比如一次写整个 Cache Line 的话,就不需要读取已有的数据了;或者一次性读取完就不管了,或者这是一个不带缓存的加速器,DMA 等,有一些针对性的优化或者简化的处理,比如对于不带缓存的 master,可以简化为 ACE-Lite,比如 ARM 的 CCI-400 支持两个 ACE master 和 三个 ACE-Lite Master,这些 Master 可以用来接 GPU 等外设。再简化一下 ACE-Lite,就得到了 ACP(Accelerator Coherency Port)。
最后我们再把文章开头的五件事对应到 ACE 上,作为一个前后的呼应:
- 读或写 miss 的时候,需要请求这个缓存行的数据(AR 上发送 ReadShared/ReadUnique),并且更新自己的状态,比如读取到 Shared,写入到 Modified 等。
- 写入一个 valid && !dirty 的缓存行的时候,需要升级自己的状态(AR 上发送 CleanUnique),比如从 Shared 到 Modified。
- 需要 evict 一个 valid && dirty 的缓存行的时候,需要把 dirty 数据写回(AW 上发送 WriteBack),并且降级自己的状态,比如 Modified -> Shared/Invalid。如果需要 evict 一个 valid && !dirty 的缓存行,可以选择通知(AW 上发送 Evict),也可以选择不通知下一级。
- 收到 snoop 请求的时候(AC 上收到 snoop 请求),需要返回当前的缓存数据(通过 CR 和 CD),并且更新状态。
- 需要一个方法(读 RACK 写 WACK)来通知下一级 Cache/Interconnect,告诉它第一和第二步完成了。
参考文献
向 Rocket Chip 添加自定义调试信号
背景
最近在尝试把核心作为一个 Tile 加到 Rocket System 中,所以想要把核心之前自定义的调试信号接到顶层上去。Rocket System 自带的支持是 trace,也就是输出每个周期 retire 的指令信息,但和自定义的不大一样,所以研究了一下怎么添加自定义的调试信号,并且连接到顶层。
分析 Trace 信号连接方式
首先,观察 Rocket Chip 自己使用的 Trace 信号是如何连接到顶层的。在顶层上,可以找到使用的是 testchipip.CanHaveTraceIO:
trait CanHaveTraceIO { this: HasTiles =>
val module: CanHaveTraceIOModuleImp
// Bind all the trace nodes to a BB; we'll use this to generate the IO in the imp
val traceNexus = BundleBridgeNexusNode[Vec[TracedInstruction]]()
val tileTraceNodes = tiles.flatMap {
case ext_tile: WithExtendedTraceport => None
case tile => Some(tile)
}.map { _.traceNode }
tileTraceNodes.foreach { traceNexus := _ }
}
可以看到,它采用了 diplomacy 的 BundleBridgeNexusNode,把每个 tile 取出来,把它的 traceNode 接到 traceNexus 上。再看一下模块 CanHaveTraceIOModuleImp 是怎么实现的:
trait CanHaveTraceIOModuleImp { this: LazyModuleImpLike =>
val outer: CanHaveTraceIO with HasTiles
implicit val p: Parameters
val traceIO = p(TracePortKey) map ( traceParams => {
val extTraceSeqVec = (outer.traceNexus.in.map(_._1)).map(ExtendedTracedInstruction.fromVec(_))
val tio = IO(Output(TraceOutputTop(extTraceSeqVec)))
val tileInsts = ((outer.traceNexus.in) .map { case (tileTrace, _) => DeclockedTracedInstruction.fromVec(tileTrace) }
// Since clock & reset are not included with the traced instruction, plumb that out manually
(tio.traces zip (outer.tile_prci_domains zip tileInsts)).foreach { case (port, (prci, insts)) =>
port.clock := prci.module.clock
port.reset := prci.module.reset.asBool
port.insns := insts
}
tio
})
}
可以看到,它从 traceNexus 上接了若干的 trace 信号,然后通过 IO(TraceOutputTop()) 接到了顶层的输出信号。
再来看看 Rocket 是如何连接的,首先是 traceNode 的定义:
/** Node for the core to drive legacy "raw" instruction trace. */
val traceSourceNode = BundleBridgeSource(() => Vec(traceRetireWidth, new TracedInstruction()))
/** Node for external consumers to source a legacy instruction trace from the core. */
val traceNode: BundleBridgeOutwardNode[Vec[TracedInstruction]] = traceNexus := traceSourceNode
然后 Rocket Tile 实现的时候,把自己的 trace 接到 traceSourceNode 上:
添加自定义调试信号
到这里,整个思路已经比较清晰了,我们只需要照猫画虎地做一个就行。比如要把自己的 Custom Debug 接口暴露出去,首先也是在 Tile 里面创建一个 SourceNode:
// expose debug
val customDebugSourceNode =
BundleBridgeSource(() => new CustomDebug())
val customDebugNode: BundleBridgeOutwardNode[CustomDebug] =
customDebugSourceNode
在 BaseTileModuleImp 里,进行信号的连接:
为了暴露到顶层,我们可以类似地做。在 Subsystem 中:
// expose debug
val customDebugNexus = BundleBridgeNexusNode[CustomDebug]()
val tileCustomDebugNodes = tiles
.flatMap { case tile: MeowV64Tile =>
Some(tile)
}
.map { _.customDebugNode }
tileCustomDebugNodes.foreach { customDebugNexus := _ }
最后在 SubsystemModule Imp 中连接到 IO:
// wire custom debug signals
val customDebugIO = outer.customDebugNexus.in.map(_._1)
val customDebug = IO(
Output(
Vec(customDebugIO.length, customDebugIO(0).cloneType)
)
)
for (i <- 0 until customDebug.length) {
customDebug(i) := customDebugIO(i)
}
这样就搞定了。
总结
找到这个实现方法,基本是对着自带的 trace 接口做的,比较重要的是理解 diplomacy 里面的两层,第一层是把不同的模块进行一些连接,然后第二层在 ModuleImp 中处理实际的信号和逻辑。
「教学」内存认证算法
背景
之前 @松 给我讲过一些内存认证(Memory Authentication)算法的内容,受益匪浅,刚好今天某硬件群里又讨论到了这个话题,于是趁此机会再学习和整理一下相关的知识。
内存认证计算的背景是可信计算,比如要做一些涉及重要数据的处理,从软件上,希望即使系统被攻击非法进入了,也可以保证重要信息不会泄漏;从硬件上,希望即使系统可以被攻击者进行一些物理的操作(比如导出或者修改内存等等),也可以保证攻击者无法读取或者篡改数据。
下面的内容主要参考了 Hardware Mechanisms for Memory Authentication: A Survey of Existing Techniques and Engines 这篇 2009 年的文章。
威胁模型
作为一个防御机制,首先要确定攻击方的能力。一个常见的威胁模型是认为,攻击者具有物理的控制,可以任意操控内存中的数据,但是无法读取或者修改 CPU 内部的数据。也就是说,只有 CPU 芯片内的数据是可信的,离开了芯片都是攻击者掌控的范围。一个简单的想法是让内存中保存的数据是加密的,那么怎样攻击者可以如何攻击加密的数据?下面是几个典型的攻击方法:
- Spoofing attack:把内存数据改成任意攻击者控制的数据;这种攻击可以通过签名来解决
- Splicing or relocation attack:把某一段内存数据挪到另一部分,这样数据的签名依然是正确的;所以计算签名时需要把地址考虑进来,这样地址变了,验证签名就会失败
- Replay attack:如果同一个地址的内存发生了改变,攻击者可以把旧的内存数据再写进去,这样签名和地址都是正确的;为了防止重放攻击,还需要引入计数器或者随机 nonce
Authentication Primitives
为了防御上面几种攻击方法,上面提到的文章里提到了如下的思路:
一是 Hash Function,把内存分为很多个块,每一块计算一个密码学 Hash 保存在片内,那么读取数据的时候,把整块数据读取进来,计算一次 Hash,和片内保存的结果进行比对;写入数据的时候,重新计算一次修改后数据的 Hash,更新到片内的存储。这个方法的缺点是没有加密,攻击者可以看到内容,只不过一修改就会被 CPU 发现(除非 Hash 冲突),并且存储代价很大:比如 512-bit 的块,每一块计算一个 128-bit 的 Hash,那就浪费了 25% 的空间,而片内空间是十分宝贵的。
二是 MAC Function,也就是密码学的消息验证码,它需要一个 Key,保存在片内;由于攻击者不知道密码,根据 MAC 的性质,攻击者无法篡改数据,也无法伪造 MAC,所以可以直接把计算出来的 MAC 也保存到内存里。为了防御重放攻击,需要引入随机的 nonce,并且把 nonce 保存在片内,比如每 512-bit 的数据,保存 64-bit 的 nonce,这样片内需要保存 12.5% 的空间,依然不少。MAC 本身也不加密,所以如果不希望攻击者看到明文,还需要进行加密。
三是 Block-Level AREA,也就是在把明文和随机的 nonce 拼接起来,采用块加密算法,保存在内存中;解密的时候,验证最后的 nonce 和片内保存的一致。这个方法和 MAC 比较类似,同时做了加密的事情,也需要在片内保存每块数据对应的随机 nonce。
Integrity Tree
但是上面几种方法开销都比较大,比如要保护 1GB 的内存,那么片内就要保存几百 MB 的数据,这对于片内存储来说太大了。这时候,可以采用区块链里常用的 Merkle Tree 或者类似的方法来用时间换空间。
这种方法的主要思路是,首先把内存划分为很多个块,这些块对应一颗树的叶子结点;自底向上构建一颗树,每个结点可以验证它的子结点的完整性,那么经过 log(n) 层的树,最后只会得到一个很小的根结点,只需要把根结点保存在片内。
为了验证某一个块的完整性,就从这一块对应的叶子结点开始,不断计算出一个值,和父亲结点比较;再递归向上,最后计算出根结点的值,和片内保存的值进行对比。这样验证的复杂度是 O(logn),但是片内保存的数据变成了 O(1),所以是以时间换空间。更新数据的时候,也是类似地从叶子结点一步一步计算,最后更新根结点的值。
这个方法浪费的空间,考虑所有非叶子结点保存的数据,如果是二叉树,总的大小就是数据的一半,但是好处是大部分都可以保存在内存里,所以是比较容易实现的。缺点是每次读取和写入都要进行 O(logn) 次的内存访问和计算,开销比较大。
上面提到的父结点的值的计算方法,如果采用密码学 Hash 函数,这棵树就是 Merkle Tree。它的验证过程是只读的,可以并行的,但是更新过程是串行的,因为要从子结点一步一步计算 Hash,父结点依赖子结点的 Hash 结果。
另一种设计是 Parallelizable Authentication Tree(PAT),它采用 MAC 而不是 Hash,每个结点保存了一个随机的 nonce 和计算出来的 MAC 值,最底层的 MAC 输入是实际的数据,其他层的 MAC 输入是子结点的 nonce,最后在片内保存最后一次 MAC 使用的 nonce 值。这样的好处是更新的时候,每一层都可以并行算,因为 MAC 的输入是 nonce 值,不涉及到子结点的 MAC 计算结果。缺点是要保存更多数据,即 MAC 和 nonce。
还有一种设计是 Tamper-Evident Counter Tree(TEC-Tree),计算的方法则是上面提到的 Block-level AREA。类似地,最底层是用数据和随机 nonce 拼起来做加密,而其他层是用子节点的随机 nonce 拼起来,再拼接上这一层的 nonce 做加密。验证的时候,首先对最底层进行解密,然后判断数据是否匹配,然后再解密上一层,判断 nonce 是否匹配,一直递归,最后解密到根的 nonce,和片内保存的进行匹配。更新的时候,也可以类似地一次性生产一系列的 nonce,然后并行地加密每一层的结果。
最后引用文章里的一个对比:

可以看到,后两种算法可以并行地更新树的节点,同时也需要保存更多的数据。
Cached Trees
从上面的 Integrity Tree 算法可以发现,每次读取或者写入都要访问内存 O(logn) 次,这个对性能影响是十分巨大的。一个简单的思路是,我把一些经常访问的树结点保存在片内的缓存,这样就可以减少一些内存访问次数;进一步地,如果认为攻击者无法篡改片内的缓存,那就可以直接认为片内的结点都是可信的,在验证和更新的时候,只需要从叶子结点遍历到缓存在片内的结点即可。
The Bonsai Merkle Tree
为了进一步减少空间的占用,Bonsai Merkle Tree(BMT)的思路是,既然对每个内存块都生成一个比较长的(比如 64 位)的 nonce 比较耗费空间,那是否可以减少一下 nonce 的位数,当 nonce 出现重复的时候,换一个密钥重新加密呢?具体的做法是,每个内存块做一次 MAC 计算,输入是数据,地址和 counter:M=MAC(C, addr, ctr)。此时,地址和 ctr 充当了原来的 nonce 的作用,所以类似地,此时的 Merkle Tree 保护的是这些 counter,由于 counter 位数比较少,就可以进一步地减少空间的开销,而且树的层数也更少了。缺点是既然位数少了,如果 counter 出现了重复,就需要更换密钥,重新进行一次加密,这个比较耗费时间,所以还要尽量减少重新加密的次数。
具体来说,为了避免重放攻击,每次更新数据的时候,就让 counter 加一,这和原来采用一个足够长(比如 64-bit)的随机 nonce 是类似的。重新加密是很耗费时间的,因此为了把重新加密的范围局限到一个小的局部,又设计了一个两级的 counter:7-bit 的 local counter,每次更新数据加一;64-bit 的 global counter,当某一个 local counter 溢出的时候加一。这时候实际传入 MAC 计算的 counter 则是 global counter 拼接上 local counter。这样相当于是做了一个 counter 的共同前缀,在内存访问比较均匀的时候,比如每个 local counter 轮流加一,那么每次 local counter 溢出只需要重新加密一个小范围的内存,减少了开销。
文章后续还提到了一些相关的算法,这里就不继续翻译和总结了。
Mountable Merkle Tree
再来看一下 Scalable Memory Protection in the Penglai Enclave 中提到的 Mountable Merkle Tree 设计。它主要考虑的是动态可变的保护内存区域,比如提到的微服务场景,并且被保护内存区域的访问有时间局部性,因此它的思路是,不去构造一个对应完整内存的 Merkle Tree,而是允许一些子树不存在。具体来说,它设计了一个 Sub-root nodes 的概念,对应了 Merkle Tree 中间的一层。这一层往上是预先分配好的,并且大部分保存在内存中,根结点保存在片内,这一层往下是动态分配的。比如应用创建了一个新的 enclave,需要新的一个被保护的内存区域,再动态分配若干个 Merkle Tree,接到 Sub-root nodes 层,成为新的子树。
由于片内空间是有限的,所以这里采取了缓存的方式,只把一部分常用的树结点保存在片内;如果某一个子树一直没有被访问,就可以换出到内存里。如果删除了一个已有的 enclave,那么相应的子树就可以删掉,减少内存空间的占用。