本文的内容已经整合到知识库中。
之前一直没搞懂 Vivado 中 xdc 需要怎么编写,遇到一些必须要写 xdc 的时候就很头疼,不知道怎么写才可以得到正确的结果。今天分析了一下 AXI Quad SPI 的时序 xdc,终于理解了其中的含义。
AXI Quad SPI 是一个 SPI 的控制器,它支持 XIP(eXecute In Place)模式,即可以暴露一个只读 AXI Slave 接口,当接收到读请求的时候,就按照标准的 SPI Flash 命令去对应的地址进行读取,然后返回结果。由于不同厂家的 SPI Flash 支持有所不同,所以 IP 上的设置可以看到厂家的选择。
特别地,一个常见的需求是希望访问 Cfg(Configuration)Flash,亦即用来保存 Bitstream 的 Flash。当 FPGA 上电的时候,如果启动模式设置为 SPI Flash,FPGA 就会向 Cfg Flash 读取 Bitstream,Cfg Flash 需要连接到 FPGA 的指定引脚上,当 FPGA 初始化的时候由内部逻辑驱动,初始化完成后又要转交给用户逻辑。转交的方式就是通过 STARTUP 系列的 primitive。
通常,如果要连接外部的 SPI Flash,需要连接几条信号线到顶层,然后通过 xdc 把信号绑定到引脚上,然后引脚连接了一个外部的 SPI Flash。但由于 Cfg Flash 比较特殊,所以信号从 AXI Quad SPI 直接连到 STARTUP 系列的 primitive 上。如果是采用 STARTUPE2 原语的 7 系列的 FPGA,那么只有时钟会通过 STARTUPE2 pritimive 连接到 SPI Flash 上,其他数据信号还是正常通过顶层绑定;如果是采用 STARTUPE3 原语的 UltraScale 系列的 FPGA,那么时钟和数据都通过 STARTUPE3 primitive 连接到 SPI Flash。
把信号连好了只是第一步,因为外设对时序要求比较复杂,如果用一个比较高直接跑,很大可能就读取到错误的数据了。很贴心的是,AXI Quad SPI 已经在生成的文件里提供了一个样例的 xdc,在文档里也有体现。在这里,我使用的设备是 Virtex Ultrascale+ 的 FPGA,其他系列的 FPGA 会有所不一样。它内容如下:
#### All the delay numbers have to be provided by the user
#### Following are the SPI device parameters
#### Max Tco
set tco_max 7
#### Min Tco
set tco_min 1
#### Setup time requirement
set tsu 2
#### Hold time requirement
set th 3
#####################################################################################################
# STARTUPE3 primitive included inside IP for US+ #
#####################################################################################################
set tdata_trace_delay_max 0.25
set tdata_trace_delay_min 0.25
set tclk_trace_delay_max 0.2
set tclk_trace_delay_min 0.2
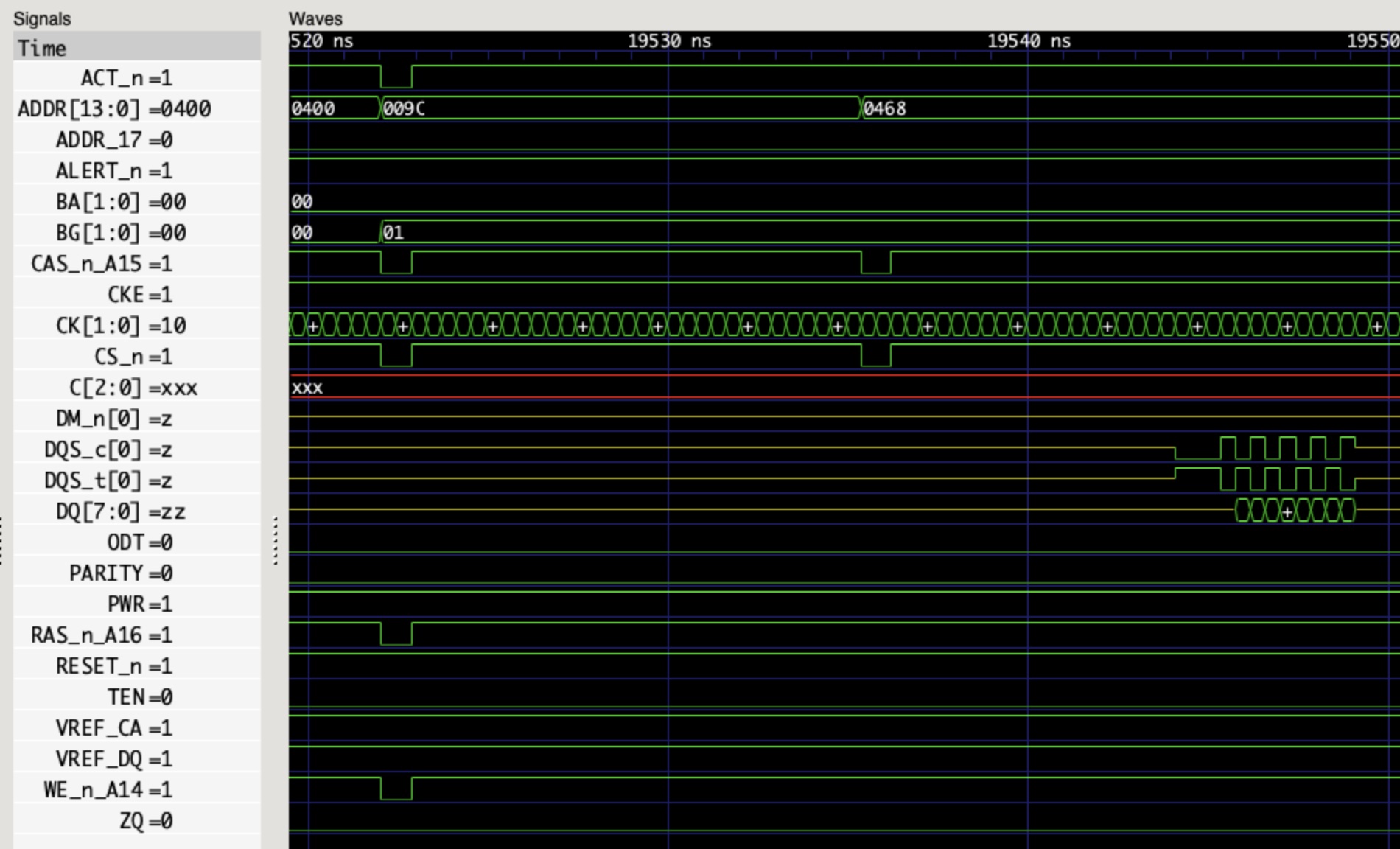
create_generated_clock -name clk_sck -source [get_pins -hierarchical *axi_quad_spi_0/ext_spi_clk] [get_pins -hierarchical */CCLK] -edges {3 5 7}
set_input_delay -clock clk_sck -max [expr $tco_max + $tdata_trace_delay_max + $tclk_trace_delay_max] [get_pins -hierarchical *STARTUP*/DATA_IN[*]] -clock_fall;
set_input_delay -clock clk_sck -min [expr $tco_min + $tdata_trace_delay_min + $tclk_trace_delay_min] [get_pins -hierarchical *STARTUP*/DATA_IN[*]] -clock_fall;
set_multicycle_path 2 -setup -from clk_sck -to [get_clocks -of_objects [get_pins -hierarchical */ext_spi_clk]]
set_multicycle_path 1 -hold -end -from clk_sck -to [get_clocks -of_objects [get_pins -hierarchical */ext_spi_clk]]
set_output_delay -clock clk_sck -max [expr $tsu + $tdata_trace_delay_max - $tclk_trace_delay_min] [get_pins -hierarchical *STARTUP*/DATA_OUT[*]];
set_output_delay -clock clk_sck -min [expr $tdata_trace_delay_min - $th - $tclk_trace_delay_max] [get_pins -hierarchical *STARTUP*/DATA_OUT[*]];
set_multicycle_path 2 -setup -start -from [get_clocks -of_objects [get_pins -hierarchical */ext_spi_clk]] -to clk_sck
set_multicycle_path 1 -hold -from [get_clocks -of_objects [get_pins -hierarchical */ext_spi_clk]] -to clk_sck
我们分段来看这个 xdc 都做了什么:
create_generated_clock -name clk_sck -source [get_pins -hierarchical *axi_quad_spi_0/ext_spi_clk] [get_pins -hierarchical */CCLK] -edges {3 5 7}
首先,它创建了一个时钟 clk_sck。CCLK 是 STARTUP 输出的实际时钟,会连接到 Cfg Flash 的时钟信号上。而 AXI Quad SPI 的 ext_spi_clk 会输出到 CCLK 上,因此这里是一个生成的时钟,并且指定上下边沿的位置。edges 参数有三个,分别表示上升、下降和上升沿分别的位置。1 表示源时钟的第一个上升沿,2 表示源时钟的第一个下降沿,以此类推,所以 {3, 5, 7} 的意思就是频率减半,相位差半个周期。
接着,最主要的就是,怎么设置延迟。可以看到,代码中首先定义了一些参数:
#### Max Tco
set tco_max 7
#### Min Tco
set tco_min 1
#### Setup time requirement
set tsu 2
#### Hold time requirement
set th 3
#### Trace delay
set tdata_trace_delay_max 0.25
set tdata_trace_delay_min 0.25
set tclk_trace_delay_max 0.2
set tclk_trace_delay_min 0.2
首先是 \(t_{co}\),应该表示的是 SPI Flash 的时钟到输出的延迟。本文用的 SPI Flash 型号是 Micron MT25QU02GCBB8E12-0SIT,可以从它的 Datasheet 看到,时钟到输出的延迟应该是 Max 7ns:
Clock LOW to output valid under 30pF Max 7ns
Clock LOW to output valid under 10pF Max 6ns
因此 tco_max 设为 7,tco_min 默认即可,因为 Datasheet 中没有做要求。
然后 \(t_{su}\) 和 \(t_h\) 则是输入的 setup 和 hold time。类似的,可以查到 SPI Flash 的参数:
Data in setup time Min 2.5ns
Data in hold time Min 2ns
所以 tsu 设为 2.5,th 设为 2。
接下来则是 tdata 和 tclk 的 trace delay。这指的是从 FPGA 引脚到 SPI Flash 引脚的信号传输延迟。从严谨的角度来说,可以从板子的布线上测量长度来计算出来,不过这里就先用默认值了。一个简单的估算方法:光速 \(3*10^8 \text{m/s}\),考虑电信号传播速度是光速的一半,可以得到延迟和长度的比值: \(0.06 \text{ns/cm} = 0.15 \text{ns/inch}\)。
那么,这些变量怎么参与到 input/output delay 的计算呢?
首先考虑 input delay。它指的是,从 SPI Flash 到 FPGA 的数据,相对于时钟的延迟。这个延迟由三部分组成:
- 从 FPGA 输出的时钟 CCLK 到 SPI Flash 的时钟有延迟 \(t_{clk}\),下图
a -> b
- 从 SPI Flash 的时钟到数据输出有延迟 \(t_{co}\),下图
b -> c
- 从 SPI Flash 的数据到 FPGA 的数据输入有延迟 \(t_{data}\),下图
c -> d
因此总延迟就是 \(t_{clk}+t_{co}+t_{data}\),就可以得到对应的设置:
set_input_delay -clock clk_sck -max [expr $tco_max + $tdata_trace_delay_max + $tclk_trace_delay_max] [get_pins -hierarchical *STARTUP*/DATA_IN[*]] -clock_fall;
set_input_delay -clock clk_sck -min [expr $tco_min + $tdata_trace_delay_min + $tclk_trace_delay_min] [get_pins -hierarchical *STARTUP*/DATA_IN[*]] -clock_fall;
接下来要考虑 output delay。虽然 output delay 也有 min 和 max,但其含义有所区别,需要分别考虑。
首先是 max,它对应的是 setup time。如果定义时间 0 为时钟的上升沿,沿更早的时间为正的时间轴,沿更晚的时间为负的时间轴。那么,我们希望的是,数据到达寄存器输入的时间大于 setup time,此时可以满足 setup 条件。那么,具体怎么算呢?注意,我们要考虑的是从 FPGA 数据输出到 SPI Flash 上时钟的延迟。
假设 FPGA CCLK 时钟上升沿在 \(0\) 时刻(下图的 a),那么 SPI Flash 时钟上升沿在 \(-t_{clk}\) 时刻(下图的 b)。假设 FPGA 数据输出时刻为 \(t_0\)(通常为正,下图的 c),那么 FPGA 数据输出到达 SPI Flash 在 \(t_0-t_{data}\) 时刻(下图的 d),我们期望 \(t_0-t_{data}\) 在 \(-t_{clk}\) 时刻之前(下图的 d -> b)至少 \(t_{su}\) 时间到达,可以得到表达式:
\[
t_0 - t_{data} > -t_{clk} + t_{su}
\]
化简一下,就可以得到 \(t_0 > t_{data} + t_{su} - t_{clk}\),如果考虑极端情况,右侧 \(t_{data}\) 取最大值,\(t_{clk}\) 取最小值,我们就可以得到约束:
set_output_delay -clock clk_sck -max [expr $tsu + $tdata_trace_delay_max - $tclk_trace_delay_min] [get_pins -hierarchical *STARTUP*/DATA_OUT[*]];
接下来考虑 output delay 的 min,这对应的是 hold time。我们希望数据到达 SPI Flash 寄存器的时候,距离上升沿时间超过了 \(t_h\)。还是一样的假设,如果 FPGA CCLK 时钟上升沿在 0 时刻(下图的 a),那么 SPI Flash 时钟上升沿在 \(-t_{clk}\) 时刻(下图的 b)。假设 FPGA 数据输出时刻为 \(t_0\)(下图的 c),那么 FPGA 数据输出到达 SPI Flash 在 \(t_0-t_{data}\) 时刻(下图的 d),要求满足 hold 条件,可以得到:
\[
t_0 - t_{data} < -t_{clk} - t_h
\]
化简以后,可以得到 \(t_0 < t_{data} - t_{clk} - t_h\),按照极限来取,\(t_{data}\) 取最小值,\(t_{clk}\) 取最大值,可以得到最终的时序约束:
set_output_delay -clock clk_sck -min [expr $tdata_trace_delay_min - $th - $tclk_trace_delay_max] [get_pins -hierarchical *STARTUP*/DATA_OUT[*]];
这样就可以实现 FPGA 和 SPI Flash 之间的正常通讯了。我觉得,这里比较绕的就是时间轴的定义,和我们平常思考的是反过来的。而且,这里的 min 和 max 并不是指 \([\min, \max]\),而是 \((-\inf, \min] \cup [\max, \inf)\)。代入上面的数据,可以得到 \(\max=2.05, \min=-2.95, t_0 \in (\inf, -2.95] \cup [2.05, \inf)\)。如果变化的时刻距离时钟上升沿太接近,就会导致在 SPI Flash 侧出现不满足 setup 或者 hold 约束的情况。
也可以换个角度来理解 min 和 max:对于同一个周期的时钟和数据来说,数据相对时钟有一个延迟,这个延迟不能太小,至少要满足 hold,所以这是一个最小的延迟;同时这个延迟不能太大,最多需要满足下一个时钟上升沿的 setup,所以这是一个最大的延迟。如果从这个角度来看,那就是延迟在一个 \([\min, \max]\) 的范围内。但是,这样在计算的时候就需要把时钟周期纳入到 \(\max\) 的计算中,比如 \(\max=t_c-t_{su}\)。如果我们把坐标轴修改一下,原点变成原来的下一个时钟周期的上升沿,x 的正方向变成反向,就可以得到上面的形式了。
那么,更常见的 FPGA 是 7 系列的,比如 Artix 7,它采用的是 STARTUPE2 原语,只有时钟是通过 STARTUPE2 原语的 USRCCLKO 信号传递到 CCLK 引脚上的,其他数据信号都是需要在顶层信号绑定对应的引脚。在 AXI Quad SPI 文档中,描述了 STARTUPE2 所需要的时序约束,我们分段来分析一下。
# You must provide all the delay numbers
# CCLK delay is 0.5, 6.7 ns min/max for K7-2; refer Data sheet
# Consider the max delay for worst case analysis
set cclk_delay 6.7
# Following are the SPI device parameters
# Max Tco
set tco_max 7
# Min Tco
set tco_min 1
# Setup time requirement
set tsu 2
# Hold time requirement
set th 3
# Following are the board/trace delay numbers
# Assumption is that all Data lines are matched
set tdata_trace_delay_max 0.25
set tdata_trace_delay_min 0.25
set tclk_trace_delay_max 0.2
set tclk_trace_delay_min 0.2
### End of user provided delay numbers
可以看到,这一部分和上面 UltraScale+ 部分差不多,只是多一个 cclk_delay 变量,这是因为 Artix 7 中,时钟只能创建到 USRCCLKO 引脚上,但是实际 SPI Flash 接收到的时钟等于 USRCCLKO 到 CCLK 引脚,然后再通过 PCB 上的线传播到 SPI Flash,所以需要手动添加一个偏移,这个偏移就是 USRCCLKO 到 CCLK 的延迟,可以在 Artix 7 Data Sheet 里面看到:对于 1.0V,-2 速度的 FPGA,这个延迟最小值为 0.50ns,最大值为 6.70ns,这里采用了最大值。
所以,下面的约束,除了时钟部分以外,和上面分析的 UltraScale+ 时序约束计算方法是相同的。不同点在于,首先约束了从 AXI Quad SPI 到 STARTUPE2 的路由时延,从 0.1ns 到 1.5ns,然后又从 USRCCLKO 创建了一个分频 + 延迟 cclk_delay 纳秒的时钟,作为 SPI Flash 上 SCK 引脚的时钟。
# this is to ensure min routing delay from SCK generation to STARTUP input
# User should change this value based on the results
# having more delay on this net reduces the Fmax
set_max_delay 1.5 -from [get_pins -hier *SCK_O_reg_reg/C] -to [get_pins -hier
*USRCCLKO] -datapath_only
set_min_delay 0.1 -from [get_pins -hier *SCK_O_reg_reg/C] -to [get_pins -hier
*USRCCLKO]
# Following command creates a divide by 2 clock
# It also takes into account the delay added by STARTUP block to route the CCLK
create_generated_clock -name clk_sck -source [get_pins -hierarchical
*axi_quad_spi_1/ext_spi_clk] [get_pins -hierarchical *USRCCLKO] -edges {3 5 7}
-edge_shift [list $cclk_delay $cclk_delay $cclk_delay]
# Data is captured into FPGA on the second rising edge of ext_spi_clk after the SCK
falling edge
# Data is driven by the FPGA on every alternate rising_edge of ext_spi_clk
set_input_delay -clock clk_sck -max [expr $tco_max + $tdata_trace_delay_max +
$tclk_trace_delay_max] [get_ports IO*_IO] -clock_fall;
set_input_delay -clock clk_sck -min [expr $tco_min + $tdata_trace_delay_min +
$tclk_trace_delay_min] [get_ports IO*_IO] -clock_fall;
set_multicycle_path 2 -setup -from clk_sck -to [get_clocks -of_objects [get_pins
-hierarchical */ext_spi_clk]]
set_multicycle_path 1 -hold -end -from clk_sck -to [get_clocks -of_objects [get_pins
-hierarchical */ext_spi_clk]]
# Data is captured into SPI on the following rising edge of SCK
# Data is driven by the IP on alternate rising_edge of the ext_spi_clk
set_output_delay -clock clk_sck -max [expr $tsu + $tdata_trace_delay_max -
$tclk_trace_delay_min] [get_ports IO*_IO];
set_output_delay -clock clk_sck -min [expr $tdata_trace_delay_min - $th -
$tclk_trace_delay_max] [get_ports IO*_IO];
set_multicycle_path 2 -setup -start -from [get_clocks -of_objects [get_pins
-hierarchical */ext_spi_clk]] -to clk_sck
set_multicycle_path 1 -hold -from [get_clocks -of_objects [get_pins -hierarchical */
ext_spi_clk]] -to clk_sck
一个 Artix 7 上配置 STARTUP SPI Flash 的例子 io_timings.xdc 可供参考。