浅谈乱序执行 CPU(二:访存)¶
本文的内容已经整合到知识库中。
背景¶
之前写过一个浅谈乱序执行 CPU,随着学习的深入,内容越来越多,页面太长,因此把后面的一部分内容独立出来,变成了这篇博客文章。
本文主要讨论访存的部分。
本系列的所有文章:
内存访问¶
内存访问是一个比较复杂的操作,它涉及到缓存、页表、内存序等问题。在乱序执行中,要尽量优化内存访问对其他指令的延迟的影响,同时也要保证正确性。这里参考的是 BOOM 的 LSU 设计。
首先是正确性。一般来说可以认为,Load 是没有副作用的(实际上,Load 会导致 Cache 加载数据,这也引发了以 Meltdown 为首的一系列漏洞),因此可以很激进地预测执行 Load。但是,Store 是有副作用的,写出去的数据就没法还原了。因此,Store 指令只有在 ROB Head 被 Commit 的时候,才会写入到 Cache 中。
其次是性能,我们希望 Load 指令可以尽快地完成,这样可以使得后续的计算指令可以尽快地开始进行。当 Load 指令的地址已经计算好的时候,就可以去取数据,这时候,首先要去 Store Queue 里面找,如果有 Store 指令要写入的地址等于 Load 的地址,说明后面的 Load 依赖于前面的 Store,如果 Store 的数据已经准备好了,就可以直接把数据转发过来,就不需要从 Cache 中获取,如果数据还没准备好,就需要等待这一条 Store 完成;如果没有找到匹配的 Store 指令,再从内存中取。不过,有一种情况就是,当 Store 指令的地址迟迟没有计算出来,而后面的 Load 已经提前从 Cache 中获取数据了,这时候就会出现错误,所以当 Store 计算出地址的时候,需要检查后面的 Load 指令是否出现地址重合,如果出现了,就要把这条 Load 以及依赖这条 Load 指令的其余指令重新执行。POWER8 处理器微架构论文中对此也有类似的表述:
The POWER8 IFU also implements mechanisms to mitigate performance
degradation associated with pipeline hazards. A Store-Hit-Load (SHL) is
an out-of-order pipeline hazard condition, where an older store executes
after a younger overlapping load, thus signaling that the load received
stale data. The POWER8 IFU has logic to detect when this condition
exists and provide control to avoid the hazard by flushing the load
instruction which received stale data (and any following instructions).
When a load is flushed due to detection of a SHL, the fetch address of
the load is saved and the load is marked on subsequent fetches allowing
the downstream logic to prevent the hazard. When a marked load
instruction is observed, the downstream logic introduces an explicit
register dependency for the load to ensure that it is issued after the
store operation.
下面再详细讨论一下 LSU 的设计。
Load Store Unit¶
LSU 是很重要的一个执行单元,负责 Load/Store/Atomic 等指令的实现。最简单的实现方法是按顺序执行,但由于 pipeline 会被清空,Store/Atomic/Uncached Load 这类有副作用(当然了,如果考虑 Meltdown 类攻击的话,Cached Load 也有副作用,这里就忽略了),需要等到 commit 的时候再执行。这样 LSU 很容易成为瓶颈,特别是在访存指令比较多的时候。
为了解决这个问题,很重要的是让读写也乱序起来,具体怎么乱序,受到实现的影响和 Memory Order/Program Order 的要求。从性能的角度上来看,我们肯定希望 Load 可以尽快执行,因为可能有很多指令在等待 Load 的结果。那么,需要提前执行 Load,但是怎么保证正确性呢?在 Load 更早的时候,可能还有若干个 Store 指令尚未执行,一个思路是等待所有的 Store 执行完毕,但是这样性能不好;另一个思路是用地址来搜索 Store 指令,看看是否出现对同一个地址的 Store 和 Load,如果有,直接转发数据,就不需要从 Cache 获取了,不过这种方法相当于做了一个全相连的 Buffer,面积大,延迟高,不好扩展等问题接踵而至。
为了解决 Store Queue 需要相连搜索的问题,A high-bandwidth load-store unit for single-and multi-threaded processors 的解决思路是,把 Store 指令分为两类,一类是需要转发的,一类是不需要的,那么可以设计一个小的相连存储器,只保存这些需要转发的 Store 指令;同时还有一个比较大的,保存所有 Store 指令的队列,因为不需要相连搜索,所以可以做的比较大。
仔细想想,这里还有一个问题:Load 在执行前,更早的 Store 的地址可能还没有就绪,这时候去搜索 Store Queue 得到的结果可能是错的,这时候要么等待所有的 Store 地址都就绪,要么就先执行,再用一些机制来修复这个问题,显然后者 IPC 要更好。
修复 Load Store 指令相关性问题,一个方法是当一个 Store 提交的时候,检查是否有地址冲突的 Load 指令(那么 Load Queue 也要做成相连搜索的),是否转发了错误的 Store 数据,这也是 Boom LSU 采用的方法。另一个办法是 Commit 的时候(或者按顺序)重新执行 Load 指令,如果 Load 结果和之前不同,要把后面依赖的刷新掉,这种方式的缺点是每条 Load 指令都要至少访问两次 Cache。Store Vulnerability Window (SVW): Re-Execution Filtering for Enhanced Load Optimization 属于重新执行 Load 指令的方法,通过 Bloom filter 来减少一些没有必要重复执行的 Load。还有一种办法,就是预测 Load 指令和哪一条 Store 指令有依赖关系,然后直接去访问那一项,如果不匹配,就认为没有依赖。Scalable Store-Load Forwarding via Store Queue Index Prediction 把 Load 指令分为三类,一类是不确定依赖哪条 Store 指令(Difficult Loads),一类是基本确定依赖哪一条 Store 指令,一类是不依赖 Store 指令。这个有点像 Cache 里面的 Way Prediction 机制。
分析完了上述一些优化方法,我们也来看一些 CPU 设计采用了哪种方案。首先来分析一下 IBM POWER8 的 LSU,首先,可以看到它设计了比较多项目的 virtual STAG/LTAG,然后再转换成比较少项目的 physical STAG/LTAG,这样 LSQ 可以做的比较小,原文:
A virtual STAG/LTAG scheme is used to minimize dispatch holds due to
running out of physical SRQ/LRQ entries. When a physical entry in the
LRQ is freed up, a virtual LTAG will be converted to a real LTAG. When a
physical entry in the SRQ is freed up, a virtual STAG will be converted
to a real STAG. Virtual STAG/LTAGs are not issued to the LSU until they
are subsequently marked as being real in the UniQueue. The ISU can
assign up to 128 virtual LTAGs and 128 virtual STAGs to each thread.
这个思路在 2007 年的论文 Late-Binding: Enabling Unordered Load-Store Queues 里也可以看到,也许 POWER8 参考了这篇论文的设计。可以看到,POWER8 没有采用那些免除 CAM 的方案:
The SRQ is a 40-entry, real address based CAM structure. Similar to the
SRQ, the LRQ is a 44-entry, real address based, CAM structure. The LRQ
keeps track of out-of-order loads, watching for hazards. Hazards
generally exist when a younger load instruction executes out-of-order
before an older load or store instruction to the same address (in part
or in whole). When such a hazard is detected, the LRQ initiates a flush
of the younger load instruction and all its subsequent instructions from
the thread, without impacting the instructions from other threads. The
load is then re-fetched from the I-cache and re-executed, ensuring
proper load/store ordering.
而是在传统的两个 CAM 设计的基础上,做了减少物理 LSQ 项目的优化。比较有意思的是,POWER7 和 POWER8 的 L1 Cache 都是 8 路组相连,并且采用了 set-prediction 的方式(应该是通常说的 way-prediction)。
此外还有一个实现上的小细节,就是在判断 Load 和 Store 指令是否有相关性的时候,由于地址位数比较多,完整比较的延迟比较大,可以牺牲精度的前提下,选取地址的一部分进行比较。POWER9 论文 提到了这一点:
POWER8 and prior designs matched the effective address (EA) bits 48:63
between the younger load and the older store queue entry. In POWER9,
through a combination of outright matches for EA bits 32:63 and hashed
EA matches for bits 0:31, false positive avoidance is greatly improved.
This reduces the number of flushes, which are compulsory for false
positives.
这里又是一个精确度和时序上的一个 tradeoff。
具体到 Load/Store Queue 的大小,其实都不大:
- Zen 2 Store Queue 48
- Intel Skylake Store Buffer 56 Load Buffer 72
- POWER 8 Store Queue 40 Load Queue 44 (Virtual 128+128)
- Alpha 21264 Store Queue 32 Load Queue 32
Load Pipeline¶
下面来举例分析 LSU 中 Load Pipeline 每一拍需要做些什么。
以香山雁栖湖微架构为例,它的 Load Pipeline 分为三级流水线:
- 第一级:计算虚拟地址(基地址 + 立即数偏移),把虚拟地址送进 DTLB 和 L1 DCache(因为 VIPT,虚拟地址作为 index 访问 L1 DCache),从 DTLB 读取物理地址,从 L1 DCache Tag Array 读取各路的 Tag
- 第二级:从 DTLB 得到了物理地址,根据物理地址计算出 Tag,和 L1 DCache 读出的 Tag 做比较,找到匹配的 Way,从 L1 DCache 的 Data Array 读取对应 Way 的数据;把物理地址送到 Store Queue,查找匹配的 Store
- 第三级:根据从 L1 DCache 读取的数据和 Store to Load Forwarding 得到的数据,得到最终的读取结果,写回
以香山南湖微架构为例,它的 Load Pipeline 分为四级流水线:
- 第一级:计算虚拟地址(基地址 + 立即数偏移),把虚拟地址送进 DTLB 和 L1 DCache(因为 VIPT,虚拟地址作为 index 访问 L1 DCache),从 DTLB 读取物理地址,从 L1 DCache Tag Array 读取各路的 Tag
- 第二级:从 DTLB 得到了物理地址,根据物理地址计算出 Tag,和 L1 DCache 读出的 Tag 做比较,找到匹配的 Way,从 L1 DCache 的 Data Array 读取对应 Way 的数据;把物理地址送到 Store Queue,查找匹配的 Store
- 第三级:由于 L1 DCache 容量较大,需要的延迟比较高,在这一级完成数据的读取和 Store to Load Forwarding
- 第四级:根据从 L1 DCache 读取的数据和 Store to Load Forwarding 得到的数据,得到最终的读取结果,写回
可见香山南湖相比雁栖湖的主要区别就是留给 L1 DCache 读取的时间更长了,4 周期也是一个比较常见的 Load to use latency。
为了减少额外的 1 个周期对 pointer chasing 场景的性能影响,南湖架构针对 pointer chasing 做了优化:pointer chasing 场景下,读取的数据会成为后续 load 指令的地址。为了优化它,南湖架构在流水线的第四级上做了前传,直接传递到下一条 load 指令的由虚拟地址计算出的 index,这样的话可以做到 3 cycle 的 load to use latency。为了优化时序,前传的时候,假设基地址加上 imm 以后,不会影响 index,这样预测的时候就不用加上 imm,时序上会好一些,不过这也限制了优化可以生效的 imm 范围。
注:PPT 里绘制的是第三级前传,但是如果是这样的话,就是 2 cycle 的 load to use latency 了,和描述不符。
类似的优化在商用处理器上也可以看到,正常的 load to use latency 是 4 周期,load to load 则可以 3 周期。例如苹果的专利 Reducing latency for pointer chasing loads 提到了它的 LSU 流水线设计以及前传的做法:
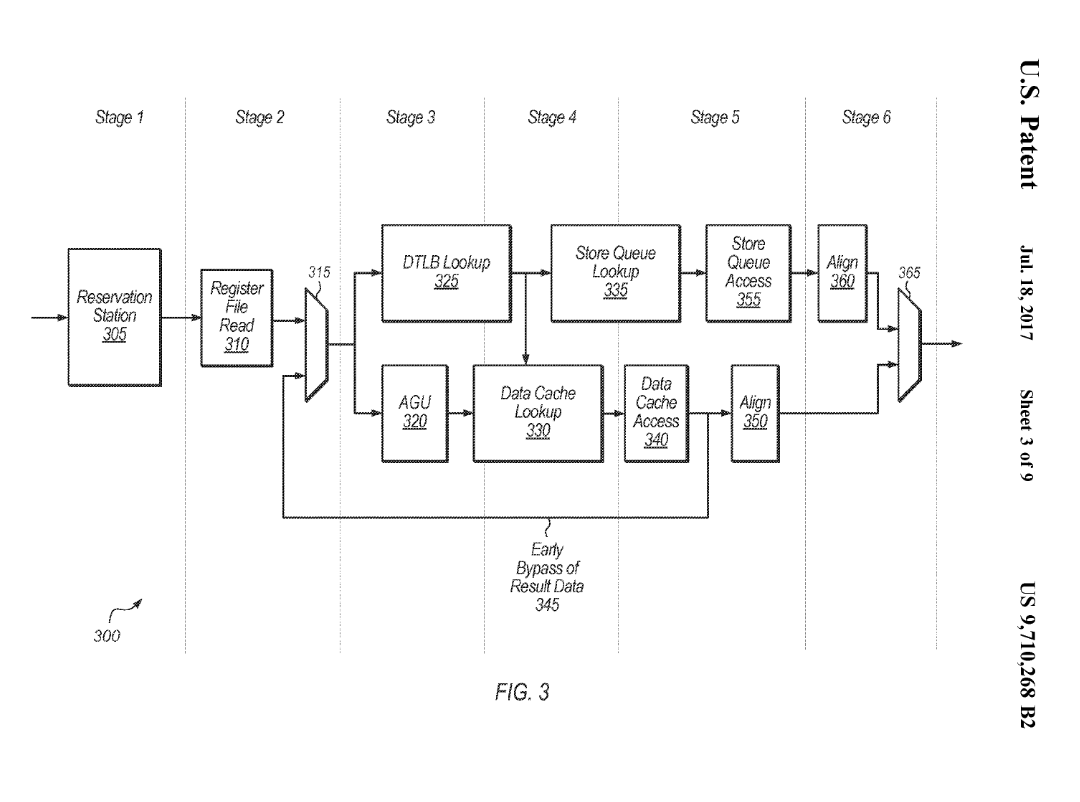
和香山南湖类似,它的 Load Pipeline 也是四级流水线(对应图中 Stage 3-6),功能也类似。不过它的 3 周期 load to load 前传的实现方法则不同。
这个专利的前传是从第三级前传到读寄存器的阶段,这样也可以实现 3 周期的 load to load latency。这样的好处是,AGU 阶段保留,这对于 AGU 阶段比较复杂的 ARM 架构是比较好的,因为 ARM 架构下 AGU 阶段可能涉及到加法和移位,而 RISCV 只有立即数加法。不过这样也要求 Load 不命中 Store Queue,而是从 L1 DCache 获得,因为 Store to Load Forwarding 的合并操作是在第四级流水线,为了能在第三级流水线前传,只能预测它不命中 Store Queue,数据完全从 L1 DCache 中取得。
图中把 AGU 和 DTLB Lookup 并着画可能有一些问题,应该是先由 AGU 计算出虚拟地址,再走 DTLB Lookup。
Memory Dependence Predictor¶
在 Load 指令要执行时,在它之前的 Store 指令可能还没有执行,此时如果要提前执行 Load,可能会读取到错误的数据。但是如果要等待 Load 之前的所有 Store 指令都就绪再执行 Load,性能会受限。因此处理器可以设计一个 Memory Dependence Predictor,预测 Load 和哪些 Store 会有数据依赖,如果有依赖,那就要等待依赖的 Store 完成,再去执行 Load;如果没有依赖,那就可以大胆提前执行 Load,当然了,为了保证正确性,Store 执行的时候,也要去看是否破坏了提前执行的 Load。总之,Memory Dependency Predictor 的目的是,找到一个尽量早的时间去执行 Load 指令,同时避免回滚。
Alpha 21264 使用了一种简单的方法 Load Wait Table 来解决这个问题:对于那些出现过顺序违例的 Load 指令,打上一个标记,那么未来这个 Load 都要等到在它之前的所有 Store 执行才能执行。这个标记的方法也很简单,维护 Load 指令的 PC 到单 bit 的映射。香山处理器有对应的实现。
另一个实现方法叫做 Store Set。Store Set 是相对 Load 说的,指的是一个 Load 依赖过的所有的 Store 的集合。如果一个 Load 的 Store Set 内的所有的 Store 都执行完了,那么这个 Load 就可以提前执行了,不用考虑别的 Store 指令。
当然了,一开始并不知道 Load 依赖哪些 Store,所以 Store Set 是空的,此时 Load 可能会提前执行。当发现执行顺序错误,需要回滚时,就把导致回滚的 Store 添加到对应 Load 的 Store Set 当中。
具体到硬件实现上,怎么去维护 Store Set 就是一个问题,因为 Store Set 可能会很大,同一个 Store 也可能会出现在很多个 Load 的 Store Set 当中。上述论文提出了一种硬件上的简化方式:
- 每个 Store 只能出现在一个 Store Set 当中,这个 Store Set 可以由多个 Load 共享。
- 执行 Load 之前,为了保证 Store Set 中的 Store 指令都完成执行,要求这些 Store 指令按照一定的顺序完成,那么 Load 只用等待 Store Set 内的最后一条 Store 指令,而不用考虑 Store Set 内所有 Store 指令完成。
具体到硬件上,有两个表来维护这些信息:首先是 Store Set Identifier Table (SSIT),这个表实现了 Load/Store 指令 PC 到 Store Set ID 的映射。通过 SSIT,就可以知道 Load 的 Store Set 是哪个 ID,哪些 Store 在这个 Store Set 当中。第二个表是 Last Fetched Store Table (LFST),它记录了这个 Store Set 中最晚被取指的 Store 指令。
前面提到,为了简化依赖的检查,同一个 Store Set 内的 Store 指令需要按照顺序执行,那么 Load 只需要依赖 Store Set 的最后一条 Store 指令。这个就是通过 LFST 来实现的:
- 每个 Store 首先根据 SSIT 找到自己的 Store Set ID,再用 Store Set ID 访问 LFST,如果里面已经有更早的 Store,那就要依赖这个更早的 Store;同时也会更新 LFST,把自己写进去。
- 同理 Load 也会根据 SSIT 找到 Store ID,用 Store Set ID 反问 LFST,去依赖最晚的 Store。
- 如果 Store 已经被执行(准确地说,Issue),自然后续的 Load 也不用等待它了,如果 LFST 记录的还是这条 Store,它就可以从 LFST 中清除掉。
下面引用论文中的一个例子。假如一开始 SSIT 和 LFST 都是空的,此时所有的 Load 指令的 Store Set 都是空的,预测为提前执行。此时一条 Load 指令和一条 Store 指令出现了执行顺序错误,这时候硬件会分配一个 Store Set ID,写入到 SSIT 中分别对应 Load 和 Store 的位置,这样就把 Load 和 Store 关联到了同一个 Store Set 当中。
未来 Store 再次被取指时,Store 通过 SSIT 找到自己的 Store Set ID,再读取 LFST,发现同一个 Store Set 内没有更早的 Store 指令,那么不创建额外的依赖,只是把自己写入到 LFST 当中。当 Load 再次被取指时,通过 SSIT 找到 Load 的 Store Set ID,再读取 LFST,发现 LFST 记录了 Store 指令的信息,那么在调度时,这个 Load 就要依赖这个 Store。
如果是一条 Load 依赖两条 Store,那么按照上面的规律,三条指令在 SSIT 中都映射到同一个 Store Set ID,第二条 Store 依赖第一条 Store,Load 依赖第二条 Store。
这个机制自然支持了多个 Load 依赖同一个 Store Set,只要给它们设置相同的 Store Set ID 即可。但缺点是,每条 Store 都只能在一个 Store Set 当中,有时候会出现这么一种情况:
- Load A 的 Store Set 是 Store X, Store Y
- Load B 的 Store Set 是 Store Z
此时出现了 Load A 和 Store Z 之间的顺序错误,但是 Store Z 和 Load A 属于不同的 Store Set。为了解决这个问题,需要引入 Store Set 合并机制:如果一条 Store 要同时出现在两个 Store Set 当中,那就把这两个 Store Set 合并成一个:Load A、Load B 的 Store Set 都是 Store X、Store Y 和 Store Z。代价是可能引入了一些假的依赖。
香山处理器也实现了 Store Set 算法的变种,其区别可以参考香山的访存依赖预测文档。
Store to Load Forwarding¶
对于那些依赖之前的 Store 的 Load 指令,如果 Store 还没有写进缓存,那么 Load 在执行的时候,就需要从 Store 要写入的数据里获取数据,这就是 Store to Load Forwarding。但实际情况可能会比较复杂,例如 Load 和 Store 只有一部分的重合,不重合的部分要从缓存中获取;或者 Load 和多个 Store 重合,要从多个 Store 分别取数据合并起来;或者前后有对同一个地址的 Store,那么要选取最晚的那一个。
首先来看看 Intel 在 Intel® 64 and IA-32 Architectures Optimization Reference Manual 中对 Core(不是 Core 系列 CPU)微架构的表述:
- 尽量通过寄存器传递函数参数,而不是栈;虽然通过栈传参数,比较容易享受到 Store to Load Forwarding 的优化,但浮点的转发还是比较慢。
- 转发时,Load 的起始地址和 Store 相同。Load 的读取范围要包含在 Store 的写入范围之内。
- 如果要从 Store 写入范围的中间而不是开头读取数据,直接从中间开始读无法享受 Store to Load Forwarding,想要更好的性能,需要先从头开始读,满足转发条件,再通过位运算提取出想要的部分。
当然了,这是很老的微架构了。
再看看 ARM 的公版核,从 ARM Cortex-X925 Core Software Optimization Guide 中可以看到这样的描述:
Load start address should align with the start or middle address of the older store.
Load 的起始地址等于 Store 的起始地址或者正好在中间。
Loads of size greater than 8 bytes can get the data forwarded from a maximum of 2 stores. If there are 2 stores, then each store should forward to either first or second half of the load.
大于 8 字节的 Load 最多可以从两个 Store 中转发数据,此时每个 Store 分别贡献一半,例如两个 Store 分别写入 8 个字节,然后 Load 把 16 个字节读出来。
Loads of size less than or equal to 4 bytes can get their data forwarded from only 1 store
小于或等于 4 字节的 Load 只能从一个 Store 中获取数据。
再看看更早的 ARM 核心,ARM Cortex-A78 Core Software Optimization Guide 中的描述:
Load start address should align with the start or middle address of the older store. This does not apply to LDPs that load 2 32b registers or LDRDs Loads of size greater than 8 bytes can get the data forwarded from a maximum of 2 stores. If there are 2 stores, then each store should forward to either first or second half of the load. Loads of size less than or equal to 8 bytes can get their data forwarded from only 1 store.
因此 X925 相比 A78 的主要区别是,8 bytes Load 也可以从多个 Store 中转发数据了。
下面是在几款处理器上实测 Store to Load Forwarding 在各种访存模式下能否转发以及转发的条件:
| uArch | 1 ld + 1 st | 1 ld + 2 st | 1 ld + 4 st | 1 ld + 8 st |
|---|---|---|---|---|
| AMD Zen5 | Yes [1] | No | No | No |
| Ampere Skylark | Yes [1] | No | No | No |
| ARM Neoverse V2 | Yes [2] | Yes [3] | No | No |
| ARM Neoverse V3 | Yes [2] | Yes [3] | No | No |
| Qualcomm Oryon | Yes [4] | Yes [5] | No | No |
| Apple M1 Firestorm | Yes | Yes [6] | Yes [6] | Yes [6] |
| Apple M2 Avalanche | Yes | Yes [6] | Yes [6] | Yes [6] |
| Apple M4 P-Core | Yes | Yes | Yes | Yes |
| Intel Golden Cove | Yes [7] | No | No | No |
| Intel Redwood Cove | Yes [7] | No | No | No |
| Intel Gracemont | Yes [8] | No | No | No |
- [1]: 要求 st 完全包含 ld
- [2]: 要求 ld 和 st 地址相同或差半个 st 宽度
- [3]: 要求 ld 和 st 地址相同
- [4]: 要求不跨越 64B 边界
- [5]: 要求 ld 对齐到 4B 边界且不跨越 64B 边界
- [6]: 要求不跨越 64B 边界
- [7]: 要求 st 完全包含 ld;特别地,在 st 和 ld 访问相同地址时,无 Forwarding 性能损失
- [8]: 要求 st 完全包含 ld,ld 和 st 地址相同,不跨越 64B 边界;特别地,64b st 到 32b ld 转发允许 ld 地址和 st 地址差半个 st 宽度
Memory Renaming¶
Register Renaming 把物理寄存器重命名为架构寄存器,那么 Memory Renaming: Fast, Early and Accurate Processing of Memory Communication 类似地把内存重命名为寄存器。具体地,如果发现某个 Load 的数据总是来自于某个 Store,按照先前的做法,要等 Store 先执行,然后 Load 从 Store Queue 中拿到 Store 的结果,更进一步,不如直接把 Load 的目的寄存器复制为 Store 的源数据寄存器,相当于把内存重命名成了寄存器,Load 变成了简单的寄存器的 Move。
具体做法是,在 Memory Dependency Predictor 的基础上,还把 Store 写入的数据保存到 Value File 当中。当预测 Load 会从某个 Store 取数据时,就从 Value File 中取出对应的数据,提早执行依赖 Load 结果的指令。
这个优化在苹果的专利中被称为 Zero cycle load:Zero cycle load 和 Zero cycle load bypass:
a destination operand of the load is renamed with a same physical register identifier used for a source operand of the store. Also, the data of the store is bypassed to the load.
Load Address Prediction¶
Prefetch 是一个常见的优化手段,根据访存模式,提前把数据预取到缓存当中。不过最终数据还是要通过访存指令把数据从缓存中读取到寄存器中,那么能否更进一步,把数据预取到寄存器中呢?这实际上就相当于,我需要预测 Load 指令要读取的地址,这样才能提前把数据读到寄存器当中。
在 1993 年的论文 A load-instruction unit for pipelined processors 提出了类似的想法:预测 Load 指令的地址,提前把数据从缓存中读取,如果命中了,把数据存到 Load Queue 中,当 Load 指令被执行,计算出实际地址时,如果实际地址和预测的匹配,就直接从 Load Queue 中取数据,而不用读取缓存,可以节省一个周期;如果缓存缺失了,就相当于进行了一次缓存的预取。为了实现地址的预测,需要维护一个 Load Delta Table,根据 Load 指令的地址来查询,Entry 记录了最后一次访问的地址以及每次访存地址的偏移 Delta,当 Delta 为 0 时,对应 Constant Address;当 Delta 不等于 0 时,对应 Stride Address。这个设计比较简单和保守,因为它要等到 Load 的地址实际计算出来才能 Bypass。
下面来分析一个来自苹果公司的专利:Early load execution via constant address and stride prediction,它实现的优化是,当一条 load 指令的地址是可预测的,例如它总是访问同一个地址(constant address),或者访问的地址按照固定的间隔(constant stride)变化,那就按照这个规律去预测这条 load 指令要访问的地址,而不用等到地址真的被计算出来,这样就可以提前执行这条 load 指令。
既然是一个预测算法,首先就要看它是怎么预测的。专利里提到了两个用于预测的表:
- Load Prediction Table,给定 PC,预测 Load 指令要访问的地址
- Load Prediction Learning Table,用于跟踪各个 PC 下的 Load 指令的访存模式以及预测正确率
一开始,两个表都是空的,随着 Load 指令的执行,首先更新的是 Load Prediction Learning Table,它会跟踪 Load 指令的执行历史,训练预测器,计算预测器的准确率。
当 Load Prediction Learning Table 发现能够以较高的准确率预测某条 Load 指令时,就会在 Load Prediction Table 中分配一个 entry,那么之后前端(IFU)再次遇到这条 Load 指令时,通过检查 Load Prediction Table,就可以预测要访问的地址。
当 Load Prediction Learning Table 发现某条 Load 指令的预测错误次数多了,就会把对应的表项从 Load Prediction Table 和 Load Prediction Learning Table 中删除,此时就会回退到正常的执行过程,Load 指令需要等待地址计算完成才可以执行。
为了避免浪费功耗,如果 Load 指令的地址很快就可以算出来,那么预测也就没有必要了,此时即使做了预测,也不会带来很高的性能提升。判断的依据是,计算从预测地址到计算出地址耗费的周期数,如果超过一个阈值,那么优化就有效果;如果没有超过阈值,那就不预测。
那么,如果 Load 的地址需要比较长的时间去计算,但实际上又是可以预测的,那就可以通过 Load Address Prediction 的方法,来提升性能。
根据论文 SLAP: Data Speculation Attacks via Load Address Prediction on Apple Silicon,苹果在 M2/M3/M4/A15/A16/A17 等处理器的 P 核上实装了 Load Address Prediction 预测器,它会观察 Load 指令的访存的规律,如果一条 Load 总是访问同一个地址,或者总是以相同的跨步访问地址,那么就会预测它的下一个访问地址,从而提升性能。它的各项参数如下:
- 支持 Constant 和 Striding Address 两种访存模式
- 支持 Stride 范围是正负 256B,过大的 Stride 则不会预测
- 大概 500 次符合规律的 load 后使能地址预测以提升性能
- 当下一次预测的地址要跨到下一个 page 的时候不预测,避免污染 DTLB
- 用 load 指令的地址做 full tag,不同地址的 load 指令互不干扰,不会出现 alias
Way Prediction¶
组相连结构在处理器的很多地方都有,例如各种缓存,那么在访问组相连结构的缓存的时候,首先需要用 Index 取出一个 Set,再进行 Way 的匹配。但缓存在硬件中通常是用 SRAM 实现的,读取有一个周期的延迟,因此读取的过程并没有这么简单,下面分析几种读取组相连缓存的设计:
第一种最简单的办法是,第一个周期根据 Index 把整个 Set 所有 Way 的 Tag 和数据都读出来,第二个周期就可以拿到所有的 Tag 和数据,比较 Tag 后得到结果。这个方法比较简单,缺点是功耗比较大,实际只命中最多一个 Way,却要把所有的 Way 和 Tag 和数据都读出来。
既然只有一个 Way 的数据需要用,一个直接的想法是把读取拆成两步:第一个周期根据 Index 把整个 Set 所有 Way 的 Tag 都读出来,只读 Tag 不读数据,比对 Tag 后,第二个周期再把 Tag 正确的那一个 Way 的数据读出来。这样省下了很多数据 SRAM 的读取功耗,Tag 的读取没有省,同时付出了多了一个周期的代价。
有没有什么办法改进呢?能否只读一个 Way 的 Tag 和数据?这就需要引入 Way Prediction,这在论文 Way-Predicting Set-Associative Cache for High Performance and Low Energy Consumption 中提出,它的思路是,引入一个预测器,预测这次访问会命中哪个 Way,然后第一个周期只读这一个 Way 的 Tag 和数据,如果 Tag 命中了,数据也有了,这样功耗和性能都是比较好的。不过如果预测错了,第二个周期就需要把其他几个 Way 的 Tag 和数据读出来,再比较一次:
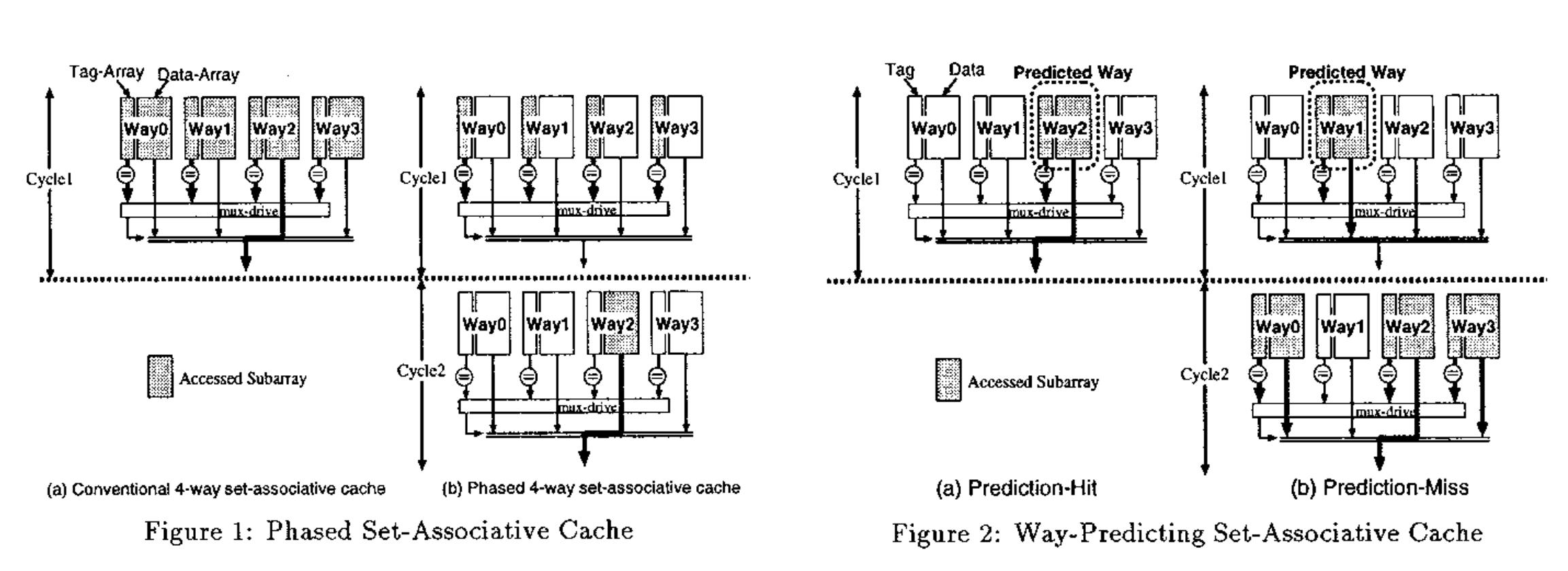
(图源 Way-Predicting Set-Associative Cache for High Performance and Low Energy Consumption)
通过这样的方法,可以大大降低缓存读取的功耗。这样的设计在商用处理器中也有使用,见 Take A Way: Exploring the Security Implications of AMD’s Cache Way Predictors。
Zen5 的文档里提到了它怎么在 L1 DCache 上做 Way Prediction:
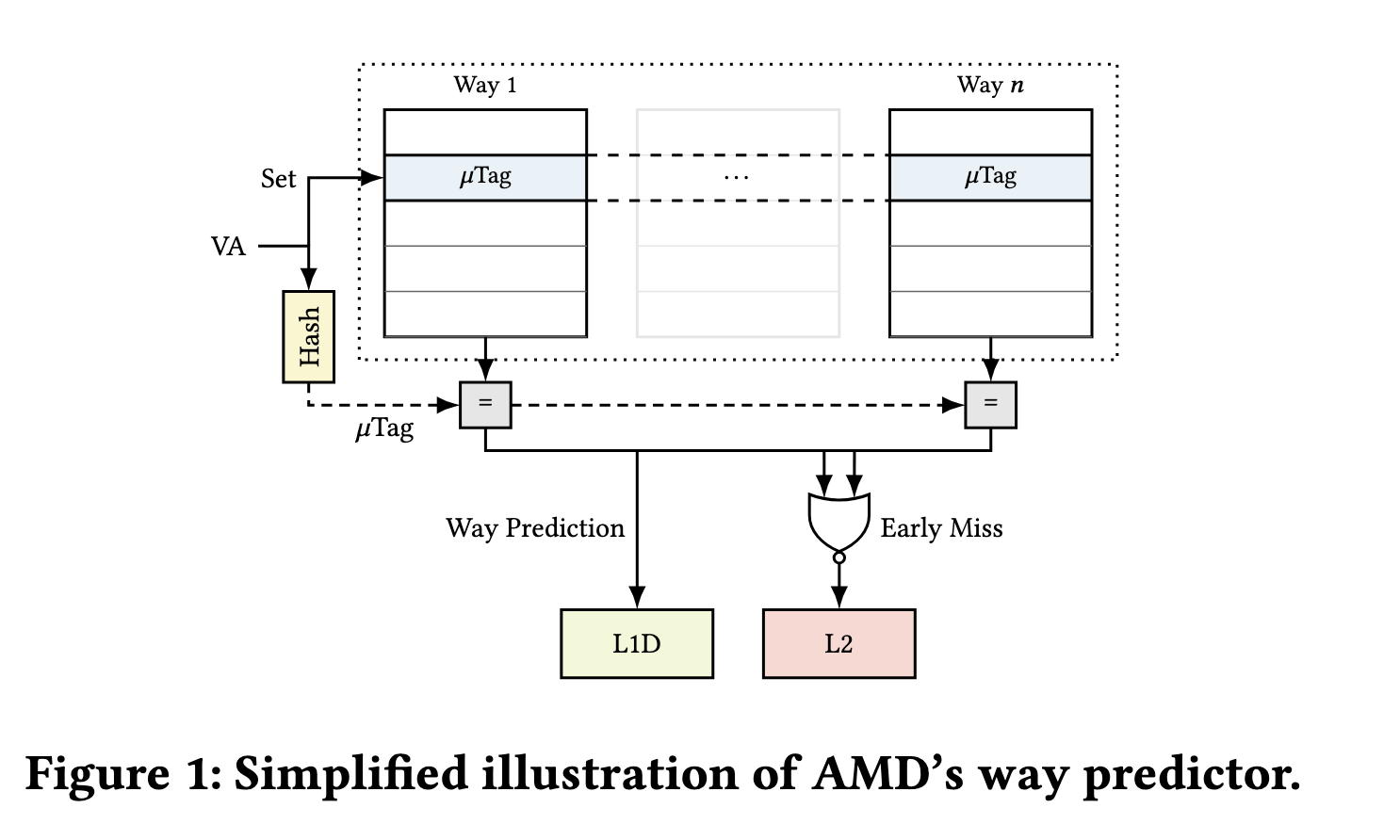
(图源 Take A Way: Exploring the Security Implications of AMD’s Cache Way Predictors)
- 对于 VIPT 的 cache 来说,它的 tag 来自于物理地址,意味着如果要做 way 比对,判断哪一个 way 命中,需要等到虚实地址转换,得到物理地址以后,才能知道实际的 tag,才能去比对
- Zen 5 为了避免等待虚实地址转换,基于虚拟地址计算出一个 8-bit 的 microtag(utag),在一个类似缓存的 way predictor 结构里,保存每个 set 的每个 way 的 utag,同一个 set 内不同 way 的 utag 互不相同,way predictor 的 way 和 data cache 的 way 一一对应
- 访存的时候,读出那个 set 的所有 way 的 utag(12 路,每路 8 bit),用 utag 进行比对:
- 因为 utag 互不相同,所以最多只有一个 way 命中
- 如果有且仅有一个 way 命中,下一个周期就去读取出这一个 way 对应的数据以及用物理地址算出来的 tag
- 如果没有 way 命中,则认为 miss
- 由于 utag 完全用的是虚拟地址,它可能会出错,分两种情况:
- 把 miss 的预测为 hit,比如出现了 hash 冲突,有两个 way 的 tag 不同,但是 utag 一样,只能预测其中一个 way,访问另一个的时候就会 miss
- 把 hit 的预测为 miss,比如两个虚拟页映射到同一个物理页,用物理地址算出来的 tag 相同,但用虚拟地址算出来的 utag 不同,这两个 utag 就会抢同一个 way 的位置(注:这个问题是可以解决的,比如不要求 way predictor 的 way 与 data cache 的 way 一一对应,在 way predictor 每个 entry 里面加上一个 data cache 的 way index,不过考虑到概率和开销,好处不明显)
- 等虚实地址转换完成,再用物理地址验证访问是否正确
除了 Way Prediction,实际的 L1 DCache 为了每个周期可以处理多条 Load/Store 指令,还会分 Bank。那么每条访存指令要访问哪个 Bank,也需要预测,这和 Way Prediction 是类似的,比如 Zen5 的文档是这么说的:
Address bits 5:3 and the size of an access along with its DC way determine
which DC banks are needed for that access. DC way is determined using the
linear-address-based utag/way-predictor.
论文 Take A Way: Exploring the Security Implications of AMD’s Cache Way Predictors 是这么逆向 AMD 的 utag/way predictor 的:
- 由于是 VIPT,所以 cache 的 index 位是 VA[11:6],因此可以构造出不同的虚拟地址,让它对应同一个 set(
We pick two random virtual addresses that map to the same cache set.) - 如果两个虚拟地址映射到了不同的物理地址,但是用这两个虚拟地址算出来的 utag 相同,那么 way predictor 会把它们预测到同一个 way 上,但它们实际上对应了不同的物理地址,这就导致冲突,性能会下降(
If the two addresses have the same 𝜇Tag, repeatedly accessing them one after the other results in conflicts);不断寻找性能下降的情况,发现最多可以得到 256 组地址,组内 utag 相同,组间 utag 不同,这暗示了 utag 来源于用虚拟地址 hash 出来的 8 个 bit 信息 - 也可以反过来测,如果两个虚拟地址映射到相同的物理地址,但是 utag 不同,那么 way predictor 把它们映射到不同的 way 上,结果会有两个不同 way 的用物理地址算出来的 tag 相同,同一个数据存两份,这也是不允许的
- 根据这 256 组地址,找到 AMD Zen/Zen+/Zen2 的 uTag 哈希函数:
- uTag[7] = VA[19] xor VA[24]
- uTag[6] = VA[18] xor VA[23]
- uTag[5] = VA[17] xor VA[22]
- uTag[4] = VA[16] xor VA[21]
- uTag[3] = VA[15] xor VA[20]
- uTag[2] = VA[14] xor VA[25]
- uTag[1] = VA[13] xor VA[26]
- uTag[0] = VA[12] xor VA[27]
- 类似地,找到更早的 AMD Bulldozer/Piledriver/Streamroller 的 uTag 哈希函数:
- uTag[7] = VA[19] xor VA[27]
- uTag[6] = VA[18] xor VA[26]
- uTag[5] = VA[17] xor VA[25]
- uTag[4] = VA[16] xor VA[24]
- uTag[3] = VA[15] xor VA[23]
- uTag[2] = VA[14] xor VA[22]
- uTag[1] = VA[13] xor VA[21]
- uTag[0] = VA[12] xor VA[20]
Load Value Prediction¶
Value Locality and Load Value Prediction 提出了 Load Value Prediction,就是对 Load 得到的值进行预测。它设计了一个 Load Value Prediction Table,根据 Load 指令的地址来索引,得到预测的读取的值。然后设计一个 Load Classification Table 来记录预测准确与否的历史,记录了 saturating counter,以此来判断是否要进行预测。预测时,可以提前把结果写入到目的寄存器内,但还要验证预测的正确性。验证的方式有两种:第一是依然完成正常的访存,把读出来的数据和预测的数据做比较;第二是针对预测正确率很高的 Load,从一个小的 Constant Verification Unit 确认这个值没有变过。
如果要拿分支预测来类比,BTB 记录分支的目的地址,对应这里的 Load Value Prediction Table,记录 Load 指令得到的值;BHT 记录分支的跳转方向,对应这里的 Load Classification Table,判断 Load 的可预测性。
Constant Verification Unit 类似一个小的针对 Load Value Prediction 的 L0 Cache,只记录那些预测正确率很高的 Load 的地址 - 值映射关系,可以在地址计算出来后查询,判断访存是否正确预测,如果正确,就不用访问缓存了。
可见这个优化主要解决的是打破了 Load 指令带来的依赖,但缓存带宽还是要耗费的(Constant Verification Unit 可以节省一些)。
根据论文 FLOP: Breaking the Apple M3 CPU via False Load Output Predictions,苹果在 M3/M4/A17 等处理器的 P 核上实装了 Load Value Prediction 预测器,它会观察 Load 指令的访存的规律,如果一条 Load 总是读出来相同的数据,那就会预测它未来读出来还是相同的数据。它的各项参数如下:
- 只支持 Constant value,即 load 指令读出来的数据不变
- 不支持 Striding value,即 load 指令读出来的数据构成等差数列
- 大概 240 次 load 相同的值后使能值预测以提升性能
- 对于 1/2/4 字节 load,可以预测出所有可能的值,意味着这最多 4 字节的值会记录在预测器内部
- 对于 8 字节 load,只能预测值等于 0 的情况,没有做 8 字节 load 的通用场景,背后的考虑可能是:
- 8 字节比较长,开销大
- 8 字节且非零的 constant load 相对少见
- 指针也是 8 字节,避免预测的 8 字节的值被当成指针来用
- 观察到可以预测最多 72 个 Load 的 Value,可能是 4 路组相连
- 用 load 指令的地址做 full tag,不能跨越上下文共享
前面提到,苹果也实装了 Load Address Prediction,意味着在 M3/A17 及之后的处理器的 P 核上,既有 Load Address Prediction,又有 Load Value Prediction,分别对 Load 的地址和读出来的数据做预测。为此,苹果专利 Shared Learning Table for Load Value Prediction and Load Address Prediction 设计了一种机制来同时支持两种预测,并且共享 Learning Table:
- 前面分析苹果的 Load Address Prediction 专利时提到,硬件实现中会用到两个表,一个用来跟踪训练的状态(Learning Table),另一个用来进行实际的预测(Prediction Table)
- 类似地,Load Value Prediction 也会有类似的设计:一个 Learning Table 寻找潜在的可以被预测的 Load,一个 Prediction Table 跟踪正在被预测的 Load
- 既然两种预测都是针对 Load 进行的,就要考虑应用哪种预测,避免冲突,提升性能
- 具体的实现方法就是,用一个 Learning Table 解决 Value 和 Address 两种预测的训练,再分别给 Value 和 Address 设置各自的 Prediction Table
- 专利中给出了一种可能的 Learning Table 的 Entry 的字段:
- Status: 状态,比如 Valid,Age,Priority 等等
- PC tag: 区分不同 Load,Full Tag
- Predicted address:预测的访存地址
- Stride or value:适用 Address 还是 Value Prediction
- Predicted stride/hash of value:预测的 Stride 或者 Value 的哈希
- Striding load indicator: 是否是 Striding Load
- Confidence level:预测的信心
- Allocated in prediction table?:是否在 Prediction Table
- Number of consecutive mis-predictions:连续的错误预测次数
- 接下来讨论一条 Load 指令的训练过程:
- 当一条 Load 指令第一次进入 Prediction Table 时,还不知道它是否能够被预测,它的 Address 还是 Value 能够被预测,此时它的地址和数据会记录在 Prediction Table 当中
- 当这条 Load 再次被执行时,如果它的值和上一次相同(使用哈希判断,节省开销,当然也可能出错),则标记为 Value 预测模式;如果值不相同,那就把这次 Load 的地址减去上一次 Load 的地址作为 Stride 保存下来,标记为 Address 预测模式
- 在 Value 预测模式下,持续跟踪 Load 的值是否预测正确:
- 如果 Value 预测正确,则累积 Confidence
- 当 Confidence 超过阈值时,在 Value Prediction Table 中分配,启动 Value 预测
- 如果 Value 预测失败,则结束 Value 预测,切换到 Address 预测模式
- 在 Address 预测模式下,持续跟踪相邻两次 Load 的地址的差值:
- 如果发现连续两次访问的 Stride 相同,则标记为 Striding Load
- 反过来,如果两次访问的 Stride 不同,则取消 Striding Load 标记,重新识别 Load 的类型
- 如果 Striding Load 的 Stride 预测正确,则累积 Confidence
- 当 Confidence 超过阈值时,在 Address Prediction Table 中分配,启动 Address 预测
- 接下来分析 Value Prediction Table,专利中给出了一种可能的 Value Prediction Table 的 Entry 的字段:
- Status: 状态
- PC tag:区分不同 Load,Full Tag
- Value acquired:数据是否已经保存到 Data 字段,如果没有,需要发送一个 Probing load 去把数据取进来
- Probe Sent:标记是否已经发送 Probing load,避免重复发送
- Data:记录了预测的数据
- LRU:维护 LRU 信息
- 接下来分析 Address Prediction Table,专利中给出了一种可能的 Address Prediction Table 的 Entry 的字段:
- Status: 状态
- PC tag:区分不同 Load,Full Tag
- Predicted Address:预测要访问的地址
- Predicted Stride:预测的地址跨步
- Striding load indicator:标记是否为 Striding Load
- Intermittent striding loads:记录跨步访存的进度
Stable Load¶
论文 Constable: Improving Performance and Power Efficiency by Safely Eliminating Load Instruction Execution 指出,很多 Load 指令总是从相同的地址取出相同的值,对于这种 Load 指令(称为 Stable Load),可以通过硬件的扩展来优化,提升性能。它是这么做的:
- 检测这样的 Stable Load:Load 执行的时候,判断这次的 Load 地址和数据,与同一个 PC 的上一次 Load 是否相同,如果相同,就增加置信度
- 如果一段时间内地址和数据都不变(通过置信度判断),认为这是一个可以消除的 Stable Load
- 消除的方法是,直接把 Load 的数据复制给目的寄存器,跳过了地址计算,也不用访存
- 在 Register Monitor Table 中记录 Stable Load 使用的源寄存器,如果这些寄存器被修改了,那么大概率地址会发生变化,不再消除这条 Stable Load
- 在 Address Monitor Table 中记录 Stable Load 访问的地址,如果对这个地址有写入操作,或者被其他核心访问,那么大概率数据会发生变化,不再消除这条 Stable Load
这篇论文可以认为是 Load Value Prediction 的变体:缩小 Load 指令优化的范围,只考虑数据 Constant 且源地址寄存器不变的 Load,此时不再需要去读缓存来验证正确性,同时也省去了地址的重复计算(Load Value Prediction 中,因为没有跟踪寄存器的变化,所以预测时,还是需要重新计算地址,去查询缓存或者 Constant Verification Unit)。
数据预取¶
数据预取的目的是预测程序的访存模式,提前把数据准备到缓存当中,提升缓存的命中率。以 AMD Zen 5 为例,它实现了这些预取器(来源:Processor Programming Reference (PPR) for AMD Family 1Ah Model 24h, Revision B0 Processors):
- L2 Up/Down Prefetcher: uses memory access history to determine whether to fetch the next or previous line into L2 cache for all memory accesses.
- L2 Stream Prefetcher: uses history of memory access patterns to fetch additional sequential lines into L2 cache.
- L1 Region Prefetcher: uses memory access history to fetch additional lines into L1 cache when the data access for a given instruction tends to be followed by a consistent pattern of other accesses within a localized region.
- L1 Stride Prefetcher: uses memory access history of individual instructions to fetch additional lines into L1 cache when each access is a constant distance from the previous.
- L1 Stream Prefetcher: uses history of memory access patterns to fetch additional sequential lines into L1 cache.
简单来说,Stream Prefetcher 就是取一段连续的 Cache Line,Stride Prefetcher 则是根据 Stride 去预取数据,未必是连续的 Cache Line,Up/Down Prefetcher 更好理解,就是取相邻的一个 Cache Line。Region Prefetcher 则比较复杂,属于 Spatial Prefetcher 的一种。
Intel 的处理器通过 MSR 1A4H 可以配置各个预取器:
- the L2 hardware prefetcher, which fetches additional lines of code or data into the L2 cache.
- the L2 adjacent cache line prefetcher, which fetches the cache line that comprises a cache line pair (128 bytes). 这和 AMD 的 Up/Down Prefetcher 应该是一个意思
- the L2 Adaptive Multipath Probability (AMP) prefetcher. 根据专利 Systems and methods for adaptive multipath probability (amp) prefetcher 的描述,这个应该属于 Spatial Prefetcher
- the L1 data cache prefetcher, which fetches the next cache line into L1 data cache. 这个应该属于 Next Line Prefetcher
- the L1 data cache IP prefetcher, which uses sequential load history (based on instruction pointer of previous loads) to determine whether to prefetch additional lines.
接下来介绍 Spatial Prefetching 和 Temporal Prefetching。
Spatial Prefetching 的思想是这样的:程序经常会访问数组,那么对数组每个元素的访问模式,应该是类似的。比如访问数组前十个元素有某种规律,那么访问接下来的十个元素应该也有类似的规律,只是地址变了而已。如果这个数组的元素的结构比较复杂,这个访存模式(例如从 0、256 和 320 三个偏移分别读取数据)可能既不满足 Stride 又不满足 Stream,此时就需要 Spatial Prefetcher 来介入。例如程序在同一个物理页内,总是会从 A、B、C 和 D 四个页内偏移读取数据,那么当程序从页内偏移 A 读取一个新的物理页的数据时,大概率新的物理页内 B、C 和 D 偏移处的数据将来会被读取,那就预取进来。
一种 Spatial Prefetcher 实现是 Spatial Memory Streaming (SMS)。它的做法是,把内存分成很多个相同大小的 Region(通常一个 Region 是多个连续 Cacheline),在访问缓存时,维护当前 Region 的信息,记录这次访存指令的 PC 以及访存的地址相对 Region 的偏移,然后开始跟踪这个 Region 内哪些数据被读取了,直到这个 Region 的数据被换出 Cache,就结束记录,把信息保存下来。以上面的 0、256 和 320 为例子,访问 0 时创建一个 Region,然后把 256 和 320 这两个偏移记下来。当同一条访存指令访问到了和之前一样的偏移时,根据之前保存的信息,把 Region 里曾经读过的地址预取一遍,按上面的例子,也就是 256 和 320。这里的核心是只匹配偏移而不是完整的地址,忽略了地址的高位,最后预取的时候,也是拿新的导致缓存缺失的地址去加偏移,自然而然实现了平移。从 AMD 的专利 DATA CACHE REGION PREFETCHER 来看,AMD 的 L1 Region Prefetcher 应该采用的是 SMS 的思想,缓存缺失时,创建一个 Region,记录这个 Region 中哪些数据被访问了。
具体来说,Spatial Memory Streaming 维护了一个 Active Generation Table(缩写 AGT)来记录上面所述的 Region 内哪些数据被读取的信息,当这个 Region 里的数据被换出 Cache,对应的信息就会被保存到 Pattern History Table(缩写 PHT)当中,后续会根据 PHT 来预测预取的地址。其中 Active Generation Table 又包括了 Accumulation Table 和 Filter Table,这样做是为了减少不必要的分配,只有一个 Region 出现至少两次访问才会被分配到 Accmuluation Table 当中。具体步骤:
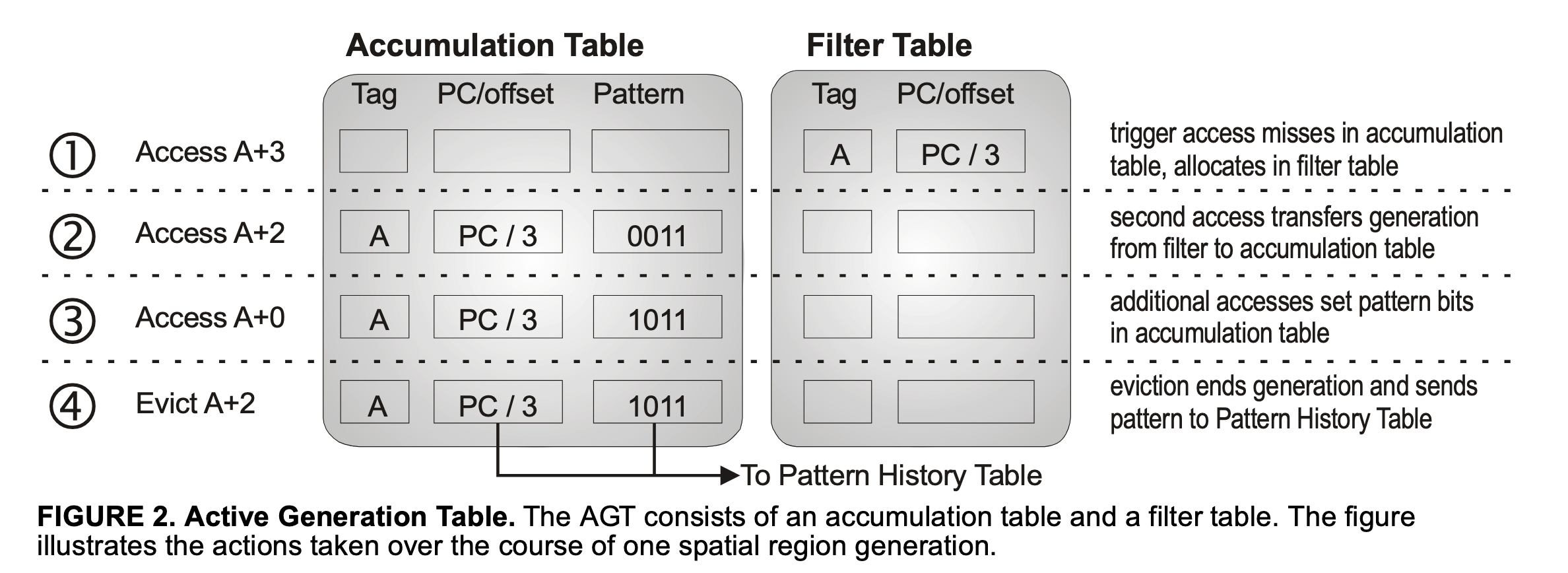
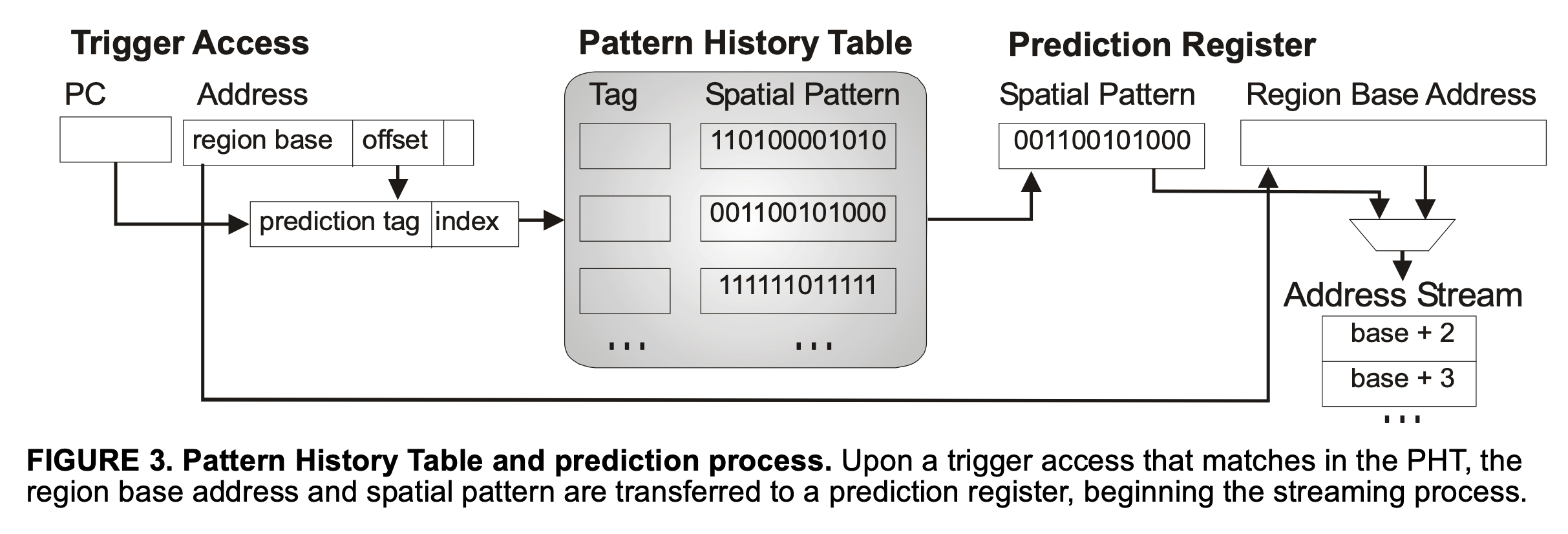
- 当一个 Region 第一次被访问的时候,此时 Accumuation Table 还没有对应的表项,把访存的 PC 和 Region 内 offset 记录到 Filter Table 当中
- 当一个 Region 第二次被访问的时候,此时 Filter Table 中应当有对应的表项,把表项挪到 Accumulation Table 当中,用 Bitmap 维护一个 Region 内哪些 Cacheline 被访问过的信息
- 当一个 Region 内第三次或更多次被访问的时候,继续更新 Region 内哪些 Cacheline 被访问过的信息
- 当 Region 内缓存被换出 Cache 时,认为这个 Region 已经学习完毕,把对应的信息移动到 Pattern History Table 中,注意 Region 地址信息不会被记录在 Pattern History Table 上,这样它就可以被用来预测多个 Region
- 与此同时,查询 Pattern History Table,如果有 PC 和 offset 匹配的 entry,就把 Region 内被访问过的 Cacheline 预取进来
Gem5 实现了 Spartial Memory Stream 预取器,基本就是按照上面的思路实现的。
另一种 Spatial Prefetcher 实现是 Variable length delta prefetcher (VLDP),它的思路是,对访存序列求差分,即用第 k 次访存地址减去第 k-1 次访存地址,得到 Delta 序列,然后对当前的 Delta 序列,预测下一个 Delta,那么预取的地址,就是 Delta 加上最后一次访存的地址。从 Intel 的专利 Systems and methods for adaptive multipath probability (amp) prefetcher 来看,它的 AMP Prefetcher 实现思路和 VLDP 类似,专利中给出了一个例子:
- 假如程序对某个物理页的访存模式是:0, 2, 4, 16, 15
- 求差分,得到:+2, +2, +12, -1
- 那么 AMP 预测器要做的就是:
- 无历史时,预测第一个差分值:N/A -> +2
- 第一个差分是 +2 时,预测第二个差分值:+2 -> +2
- 已知前两个差分时,预测第三个差分值:+2, +2 -> +12
- 已知前三个差分时,预测第四个差分值:+2, +2, +12 -> -1
不过 Spatial Prefetcher 遇到动态分配的不连续的数据结构就犯了难(比如链表和树),因为数据在内存里的分布比较随机,而且还有各种指针,要访问的数据之间的偏移大概率是不同的。这时候就需要 Temporal Prefetcher,它的思路是跟踪缓存缺失的历史,如果发现当前缺失的地址在历史中曾经出现过,那就预取在历史中紧随其后的几次缓存缺失。比如链表节点按顺序是 A、B 和 C,第一次访问时,按照 A B C 的顺序出现缓存缺失,这些缺失被记录在历史当中;未来如果再次访问 A,预取器在历史中找到 A 的位置,发现其后的缓存缺失为 B 和 C,那就对它们进行预取。就好像预取器自己存了一份链表,提前去查后继的节点,也可以说是 Record and Replay 思想的实践。
一种 Temporal Prefetch 的实现是 Sampled Temporal Memory Streaming (STMS)。它的思路是,既然要存历史,就把最近若干次 Cache Miss 的地址用一个环形数组都存下来,然后为了在缓存缺失时快速定位地址在历史中的位置,构建一个类似哈希表的结构,记录各内存地址最近一次出现在历史数组中的位置。访存时查询哈希表,如果命中了,就从历史数组中取出后续的缓存缺失的地址来预取。
ARM 公版核从 Cortex-A78/Cortex-X1/Neoverse-V1 开始引入的 Correlated Miss Caching (CMC) 预取器就是一种 Temporal Prefetcher,它可以明显降低 pointer chasing 的延迟,此时再用随机 pointer chasing 测出来的缓存容量和延迟可能就不准了。没有配备 CMC Prefetcher 的 ARM 公版核,当 footprint 超出 L2 时,随机 pointer chasing 测试可以观察到明显的延迟上升,而配备了 CMC Prefetcher 后,footprint 需要到接近 L3 才能看到明显的延迟上升。
在 Golden Cove 上进行测试,它的 L1 DCache 大小是 48KB,如果用随机的 pointer chasing 方式访存,可以观察到在 48KB 之内是 5 cycle latency,在 L2 Cache 范围内是 16 cycle latency。但如果把 pointer chasing 的访存模式改成比较有规律的模式,比如按 64B、128B、192B、256B 直至 512B 的跳步进行,可以观察到,即使超过了 L1 DCache 的容量,还是可以做到大约 5-8 cycle 的 latency。这就是 L1 Prefetcher 在起作用。
如果我们通过 wrmsr -p 0 0x1a4 0x8 把 DCU_IP_PREFETCHER_DISABLE 设为 1,关闭 L1 data cache IP prefetcher,再在 0 号核心上重新跑上面的测试,就可以看到 L2 Cache 的范围内的性能退化到了 16 Cycle,和随机 pointer chasing 一样。关闭其他的 prefetcher 则没有这个现象,说明正是 L1 data cache IP prefetcher 实现了针对 L1 的 Stride Prefetcher。
缓存/内存仿真模型¶
最后列举一下科研里常用的一些缓存/内存仿真模型:
- DRAMSim2: 论文 DRAMSim2: A Cycle Accurate Memory System Simulator 代码
- DRAMsim3: 论文 DRAMsim3: A Cycle-Accurate, Thermal-Capable DRAM Simulator 代码
- DRAMSys4.0:论文 DRAMSys4.0: A Fast and Cycle-Accurate SystemC/TLM-Based DRAM Simulator 4.0 代码 5.0 代码
- CACTI: 论文 CACTI 2.0: An Integrated Cache Timing and Power Model 代码
- McPAT: 论文 McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures 代码
- Ramulator: 论文 Ramulator: A Fast and Extensible DRAM Simulator 代码
- Ramulator: 论文 Ramulator 2.0: A Modern, Modular, and Extensible DRAM Simulator 代码