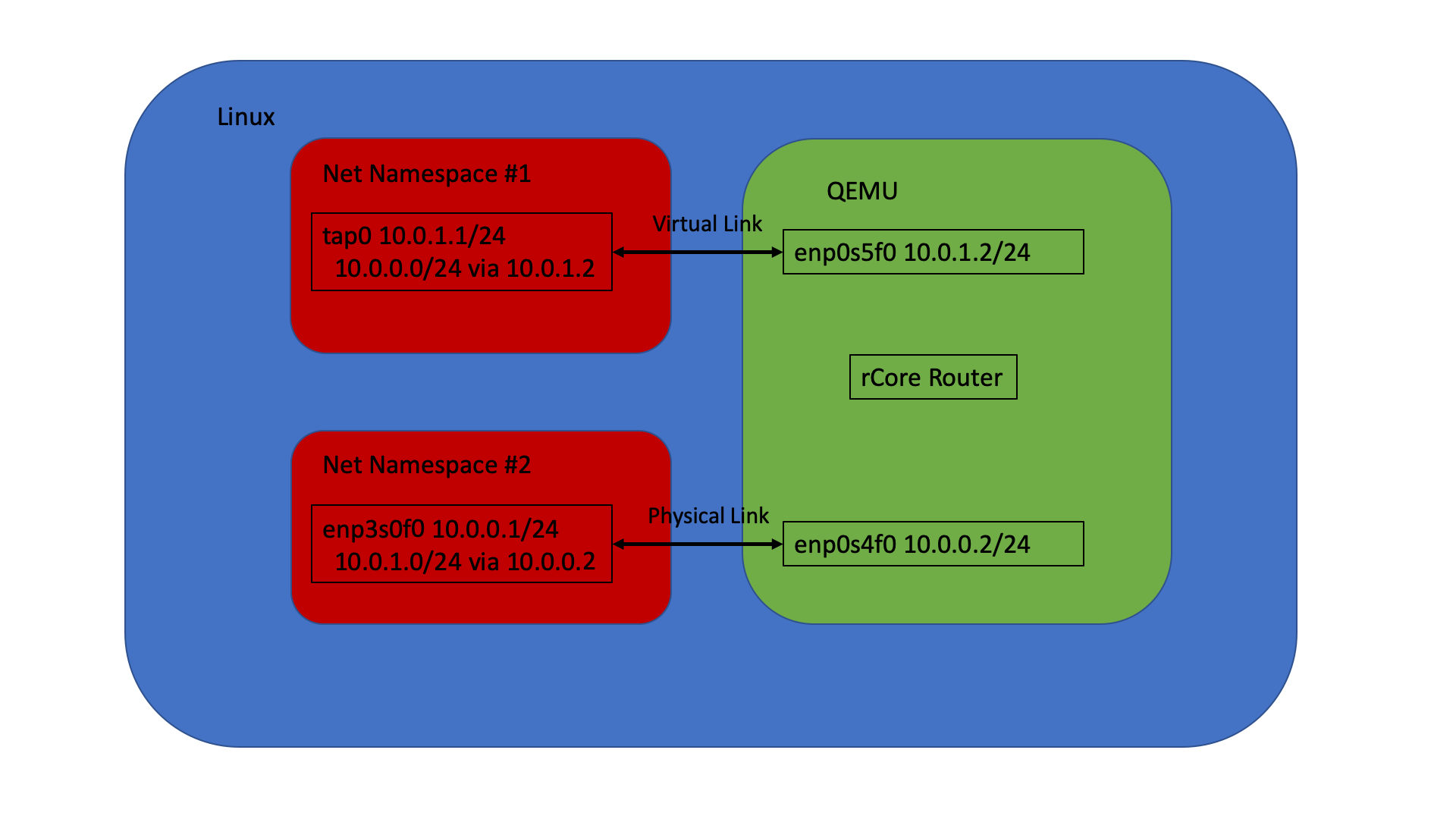
最近拿到了高云 FPGA GW2A-18 开发版,想在这上面做一些小工程。不过首先要配置好环境什么的。官方提供了 Linux 和 Windows 的两套工具,自然是拥抱 Linux 咯,但是由于官方适配的是 Redhat 系的操作系统,所以用 Debian 系的时候出现了若干问题,后面会谈到怎么解决的。
首先是官网下载了它的软件,大概有 IDE,综合器,布线器和 Programmer 四个工具,然后开始跑,发现缺少了 libcrypt.so.1.0.0。上网搜了一下解决方案,需要重新编译 openssl-1.0.0,于是下载并且编译了 openssl-1.0.0t 并且把 .so 的路径调好了,这时候就可以打开 IDE 了。然后发现需要 License,这个很简单,去官网申请一下,一天邮件就下来了。
接下来配置 License,IDE 很容易,直接选择邮件里发下来的 node-locked License 即可。不过 Synplify Pro 的 Linux 版本不支持直接单文件 node-locked 的 License,只允许跑 SCL … 不过高云也提供了 SCL 的下载,和 IDE 的 License Server 放在一起,安装完以后,在得到的 License 里加上两行:
SERVER ${hostname} ${hostid} ${port}
VENDER snpslmd /path/to/scl/2018.06/linux64/bin/snpslmd
然后把 $LM_LICENSE_FILE 指向这个文件路径,就可以了。这一部分感谢 @Jackey-Huo。
随手写了一个简化版的点亮数字人生(没有数码管),得到了 bistream,准备往板子里刷,然后问题出现了:
ImportError: /path/to/Gowin_YunYuan_V1.9.0Beta_linux/Programmer/bin/librt.so.1: symbol __vdso_clock_gettime version GLIBC_PRIVATE not defined in file libc.so.6 with link time reference
目测是 glibc 版本问题 … 这就很难处理了。另外又从官网下载了独立的 Programmer,仍然不行,检测不到设备。
最后想了想,找到了终极办法,在 Docker 里运行 CentOS 的 Privileged Container,再跑 programmer:
$ docker pull centos
$ docker run -it --privileged -v /home:/home centos /bin/bash
CentOS 镜像出乎意料地小。进去以后,找到 Programmer 路径,然后 scan:
# ./programmer_cli --scan
Scanning!
Current download-cable channel:0
Device Info:
Family: GW2A
Name: GW2A-18
ID: 0xREDACTED
1 device(s) found!
Cost 0.54 second(s)
接着烧到 SRAM 中:
# ./programmer_cli -d GW2A-18 --fsFile /path/to/bitstream.fs --run 2
"SRAM Program" starting on device-1...
Programming...: [#########################] 100%
User Code: 0xREDACTED
Status Code: 0xREDACTED
Cost 4.54 second(s)
烧录成功,功能测试也没有问题。可以继续进行下一步工作了。