最近买了一堆 NFC 的智能卡拿来测试,其中一张 MIFARE Classic 的总是在 iOS 上读不出来,无论是以 Tag 模式还是 NDEF 模式。于是通过一系列的研究,终于知道上怎么一回事,然后成功地把一个 MIFARE Classic 卡配置成了 NDEF。
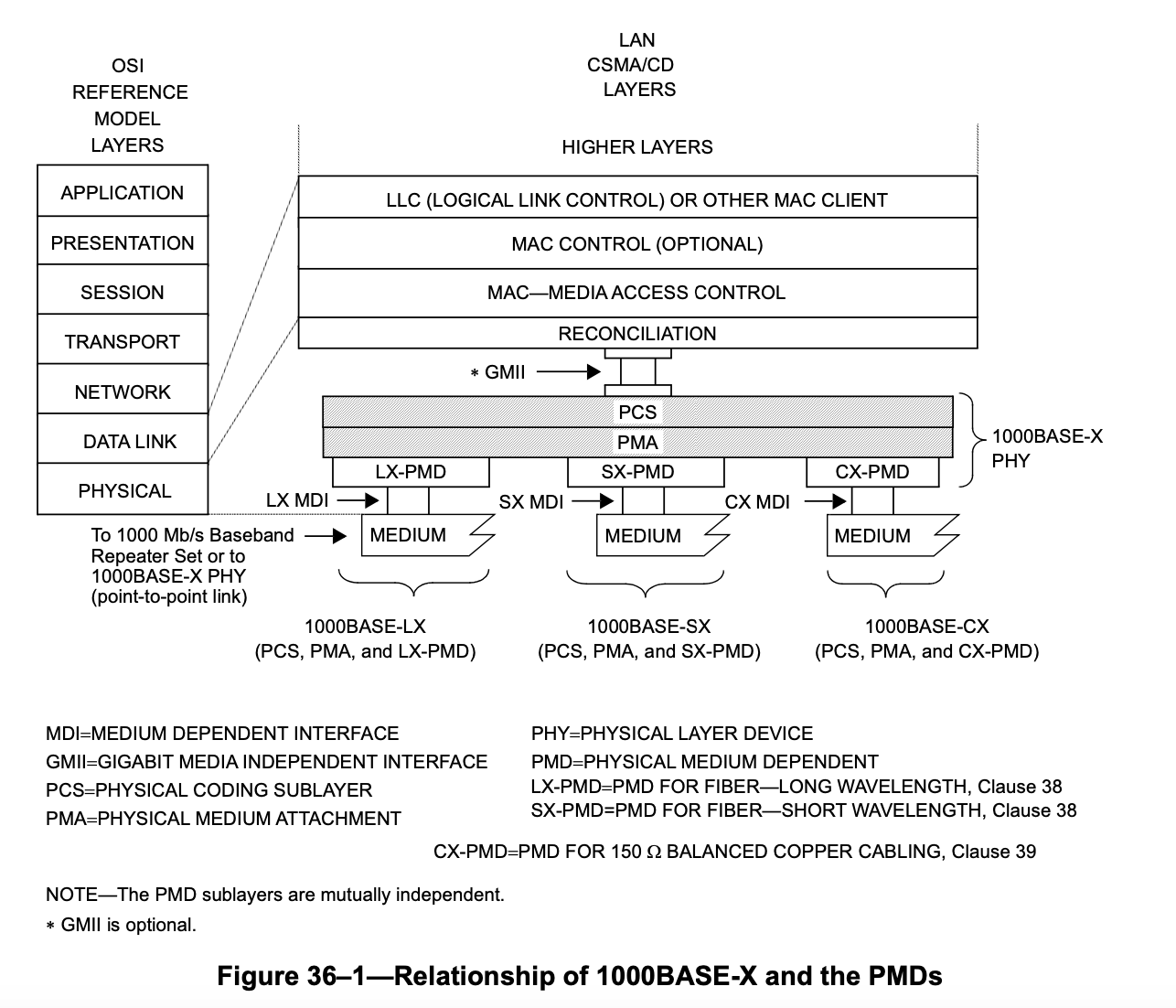
NFC 有很多协议,其中 MIFARE Classic 基于 ISO 14443-3 Type A 标准,里面有一些 MIFARE 的命令。通过这些命令,就可以控制 MIFARE Classic 卡的内容。具体来说,以我使用的 MIFARE Classic EV1 4K S70 为例,这篇文章会涉及到如下的背景知识:
在 MIFARE Classic 中,有 Sector 和 Block 的概念,每个 Sector 有若干个 Block,其中最后一个 Block 是特殊的(称为 Sector Trailer),保存了这个 Sector 的一些信息:Key A、Access Bits、GPB 和 Key B。对于 Classic 4K,首先是 32 个有 4 blocks 的 sector,然后是 8 个 有 16 blocks 的 sector,整体的内存布局大概是:
Sector 0:
Block 0
Block 1
Block 2
Block 3(Sector Trailer)
Sector 1:
Block 4
Block 5
Block 6
Block 7(Sector Trailer)
...
Sector 32:
Block 128
Block 129
...
Block 143(Sector Trailer)
...
Sector 39:
...
每个 Block 有 16 字节,一共 256 个 block,所以是 4K 大小的存储空间。Block 0 比较特殊,保存的是生产商写入的信息,不可更改。
Sector Trailer 的布局如下:
| Key A |
Access Bits |
GPB |
Key B |
| 6 字节 |
3 字节 |
1 字节 |
6 字节 |
其中 Key A 和 Key B 上用于当前 Sector 认证的两个 Key,用相应的 Key 认证以后就可以修改 Sector 里面 Block 的内容。既然有 Key,就会有细粒度的权限控制,就是 Access Bits。它的计算方式比较复杂,首先举个文档AN1305出现过的例子 0x7F 0x07 0x88:
- 按字节翻转:0x88 0x07 0x7F
- 改写成二进制:1000 1000 0000 0111 0111 1111
- 拆成前半部分:1000 1000 0000 和后半部分:0111 0111 1111
- 如果前后部分互补,说明这是个合法的 Access Bits(这种取反拼接做校验的方法挺常见的)
- 取出前半部分:1000 1000 0000
- 从后往前取三个字节的最高位:011
- 从后往前取第三个字节的次高位,依此类推:000 000 000
这里的 011 表示的是 Sector Trailer 的访问权限,特别地,它表示,不能读出 Key A,只能用 Key B 认证后修改 Key A;用 Key A 或者 Key B 认证后都可以读 Access Bits,但只能在 Key B 认证后修改 Access Bits;不能读出 Key B,只能用 Key B 认证后修改 Key B。也就是说,Key A 认证只能读 Access Bits,而 Key B 认证有权限写入 Key A、Access Bits 和 Key B 字段。完整表格见AN1305 Table 7 。
之后的三个 000 分别对应前三个 Blocks(又称 Data Blocks,先只考虑带 4 Blocks 的 Sector)的访问权限。000 表示的是,用 Key A 和 Key B 都有完整的读写权限。完整的表格见 AN 1305 Table 8 。
这里可以给读者留一个练习:0x78 0x77 0x88 对应的权限上什么?
答案:对 Sector Trailer:011;对 Data Blocks:100;此时 Data Blocks 可以用 Key A 或者 Key B 认证读取,但只能用 Key B 认证写入。
如果查看完整的表格就可以发现,Key B 的权限一般是比 Key A 大的,所以 Key B 一般是保密的,而 Key A 可以是公开的。
为了向 MIFARE Classic 卡发送命令,首先需要一个 ISO 14443-3 Type A 的接口,Android 的 NfcA 或者 libnfc 都提供了接口。这里发送的命令实际上会再经过一层解析、用 CRYPTO1 算法加密(猜测是读卡器做的?不是很确定),不过对应用程序来说是透明的。可以参考 MIFARE Classic EV1 1K 和 A Practical Attack on the MIFARE Classic 中的描述。
读出一个 Block 的内容,每个 Block 有 16 字节。命令格式如下:
如果要读第一个 Block,就是 30 00,如果要读第二个 Block,就是 30 01 。
返回的数据里刚好是 16 个字节。
向一个 Block 写入数据,命令格式如下:
A0 XX YY YY YY YY YY YY YY YY YY YY YY YY YY YY YY YY
这里的 XX 和上面一样,也是 Block 地址;之后是十六字节的数据。
注:这里和 S70 datasheet 里写的不完全一样。
这个命令会进行 Key A 或者 Key B 的认证,如果是对 Key A 认证:
60 XX YY YY YY YY ZZ ZZ ZZ ZZ ZZ ZZ
这里的 XX 也是 Block 地址,但实际上认证的粒度上 Sector,所以只要认证了 Sector 里面的一个 Block,其他 Block 也是同时认证,也是用同一个 Sector Trailer 中的信息进行认证。YY 则是 ISO 14443-3 Type A 中的 UID,如果用 Android 的 API 读取,就可以在 NfcA 中找到这个四字节的信息。ZZ 就是要认证的密钥,六个字节。
如果是对 Key B 认证,把第一个字节的 0x60 改成 0x61 即可。
认证成功后,返回一个 0x00;如果认证失败,则会断开 NFC。
NDEF 实际上是比较高层次的数据,就像 HTML,表示了一个格式化的数组数据,数组的元素可能是文本、URI 等等。它是由若干个 Record 组成的。一个 Record 如下:
03 0B 01 07 54 02 65 6E 61 62 63 64
首先是一个 03 表示类型,然后是长度 0x0B(11,从下一个字节开始数),接着是 0x01 0x07 表示这似乎一个 Well Known 类型的 Record,内容的长度为 7,0x54(ASCII T)表示这是文本格式,0x02 表示编码是 UTF-8,0x65 0x6E (ASCII "en") 表示语言是英语,之后的 0x61 0x62 0x63 0x64(ASCII "abcd")就是文本内容。
很多个 record 连起来,最终一个 0xFE 表示结束,这就是完整的 NDEF 信息了。
NDEF 只定义了数据格式,但为了实际使用,还得看具体情况。就好像文件内容保存在硬盘上的时候,并不是直接保存,而是通过文件系统,人为定义一个路径,这样大家才知道要从 /etc/shadow 文件去读 Linux 的用户密码信息,NDEF 也需要人为定义一些规则,再作为数据存放在智能卡里的某个地方,这样大家去读取 metadata,发现上 NDEF Tag,然后才会去解析 NDEF 信息。
有些时候,这个定义很简单,比如直接把 NDEF 数据放在某个 block 里面;有的时候又很复杂,因为可能同时存在很多应用,NDEF 只是其中的一种,所以要有一种类似目录的东西去索引 NDEF“文件”。
MIFARE Classic 上采用的方法上,在特定的 Sector(比如 Sector 0)放一些元数据,元数据里注明了其他的 Sector(从 1 开始的其它 sector)分别用于什么用途,然后 NDEF 是其中一种用途。这个结构叫做 MIFARE Application Directory。具体来说,在 MIFARE Classic 里面,它规定 Block 1 和 Block 2 的内容如下:
| 0-1 |
2-3 |
4-5 |
6-7 |
8-9 |
10-11 |
12-13 |
14-15 |
| Info & CRC |
AID |
AID |
AID |
AID |
AID |
AID |
AID |
| AID |
AID |
AID |
AID |
AID |
AID |
AID |
AID |
第一个字节是 CRC 8,它的定义可以在这里的 CRC-8/MIFARE-MAD 里找到:初始值 0xC7,多项式上 0x1D。参与 CRC 计算的是按顺序从第二个字节开始的 31 个字节。
第二个字节是 Info Byte,用处不大,见 MAD 的文档。
之后每两个字节对应一个 Sector 的 AID(Application ID),比如 Block 1 的 2-3 字节对应 Sector 1 的 AID,Block 1 的 4-5 字节对应 Sector 2 的 AID,最后 Block 2 的 14-15 字节对应 Sector 15 的 AID。NDEF 的 AID 就是 0x03 0xE1。当软件发现这里的 AID 是 0x03E1 的时候,它就会去相应的 Sector 去读取 NDEF 信息。
一个用 TagInfo 读出来的例子如下:
Sector 0 (0x00)
[skipped]
[01] F3 01 03 E1 03 E1 00 00
rW- 00 00 00 00 00 00 00 00
[02] 00 00 00 00 00 00 00 00
rW- 00 00 00 00 00 00 00 00
[03] A0:A1:A2:A3:A4:A5 MAD access key
WXW 78:77:88 C1
XX:XX:XX:XX:XX:XX (key unavailable)
可以看到,这里表示的是 Sector 1 和 Sector 2 是 03E1 NDEF。下面 [03] 行表示的是 Key A,下一行是 Access bits、GPD,最后一行是 Key B。TagInfo 会尝试从 well known 里的 Key A 和 Key B 一个个试,直到认证成功为止。常见的如下:
- A0 A1 A2 A3 A4 A5:MAD 的 Key A
- D3 F7 D3 F7 D3 F7:NDEF 的 Key A
- FF FF FF FF FF FF:出场默认的 Key A 和 Key B
如果看了这么多背景知识,你还有心情看到这里,那要给个掌声。
为什么要在 MIFARE Classic 上配置 NDEF 呢?因为直接买到的 MIFARE Classic(比如我用的 EV1 4K S70)里面都是出厂状态,Key A 和 Key B 都是 FF FF FF FF FF FF,除了 Block 0 以外数据都是 0,所以它并不能用作 NDEF,Android 也只是认为它 NdefFormattable。所以我们要做的就是,Format as NDEF。为啥要自己搞呢,也是因为试了几个现成的工具 format 都失败了。
其实整个流程在 AN1305 的 8.1 章节都写了,但看起来简单,实现起来还是有很多细节,在搞的时候也是来来回回做了很多尝试,同时也利用 TagInfo 强大的 Memory dump 配合调试。
首先复习一下我们可以用哪些命令:
- MIFARE Authenticate:对一个 sector 认证,认证成功了才能写操作
- MIFARE Read:读取一个 Block
- MIFARE Write:写入一个 Block
仔细观察 AN1305 的 Fig.10 和下面的文本描述,大概需要做这些事情:
- 修改 Block 1 和 Block 2 中的信息,符合 MAD 的格式
- 修改 Sector 0 的 Sector Trailer
- 修改 Block 4,填入一个空白的 NDEF,或者直接前面背景知识里的例子。
- 修改 Sector 1 和 Sector 2 的 Sector Trailer
但有一些细节:
- 修改 Sector Trailer 的时候要谨慎,因为会修改 Key,如果改完又忘了,这卡就废了
- 注意用 Key A 还是 Key B 进行认证。上面这些流程结束后,Sector 0 被保护了,需要用 Key B 才能修改数据;而 Sector 1 和 Sector 2 是开放的;如果执行完第一步和第二步以后,发现第一步写错了,就要注意权限的问题,必要时还可以先修改 Access bits 再修改数据
- 在这里为了简单,Key B 都用 FF FF FF FF FF FF 了,实际情况下可以用别的自己的密钥,只要记住就行
那么,按照前面的这些知识,就可以构造出每一步的 MIFARE 命令了:
注意:下面的命令不一定能工作,在执行前请仔细理解每条命令的结果,本文作者对卡的损失概不负责
第一步:
60 00 YY YY YY YY FF FF FF FF FF FF
A0 01 F3 01 03 E1 03 E1 00 00 00 00 00 00 00 00 00 00
A0 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
注意 YY 要填入 ID。这一步首先用 FF FF FF FF FF FF 认证了 Sector 0 的 Key A,然后写入了 Block 1 和 Block 2。Info Byte 用的是 0x01,然后用在线工具计算了一下 CRC=F3。
第二步:
A0 03 A0 A1 A2 A3 A4 A5 78 77 88 C1 FF FF FF FF FF FF
这一步设置了 Key A 为 MAD access key,权限是 78 77 88,GPB 是 C1,Key B 为 FF FF FF FF FF FF
第三步:
60 04 YY YY YY YY FF FF FF FF FF FF
A0 04 00 00 03 0B D1 01 07 54 02 65 6E 61 62 63 64 FE
这一步认证了 Sector 1,然后往 Block 4 写入了一个 abcd 的 NDEF 记录。
第四步:
A0 07 D3 F7 D3 F7 D3 F7 7F 07 88 40 FF FF FF FF FF FF
60 08 YY YY YY YY FF FF FF FF FF FF
A0 0B D3 F7 D3 F7 D3 F7 7F 07 88 40 FF FF FF FF FF FF
写入了 Sector 1 的 Sector Trailer,然后认证 Sector 2,再写入 Sector 2 的 Sector Trailer
这样就完成了,再用 TagInfo 等软件,就可以读取出来 NDEF 信息了。此时 iOS 也可以读出来。
上面这些过程,在实际情况下在不同 sector 的时候需要打断,每次重新认证一下。这里默认了一些卡的初始密钥,如果初始情况并不一致,可能并不会工作。
在这个过程中踩过很多的坑:
- 在空 NDEF 的时候,NFC Tools 能读出来是 Ndef,并且内容是空,但写入的时候表示 Write error,也读不出来;去 TagInfo 读内存,发现确实写进去了,但内容不对,有一个位置的长度写成了 0,可能是 BUG
- 上面也提到过的,就是在修改为只读以后,发现数据写错了,只好重新改成可写,把数据改好了以后再设为只读。
- iOS 上用 NFCNDEFReaderSession 可以读出来这个 NDEF 的内容,但 NFCTagReaderSession 并不能 poll 出来。