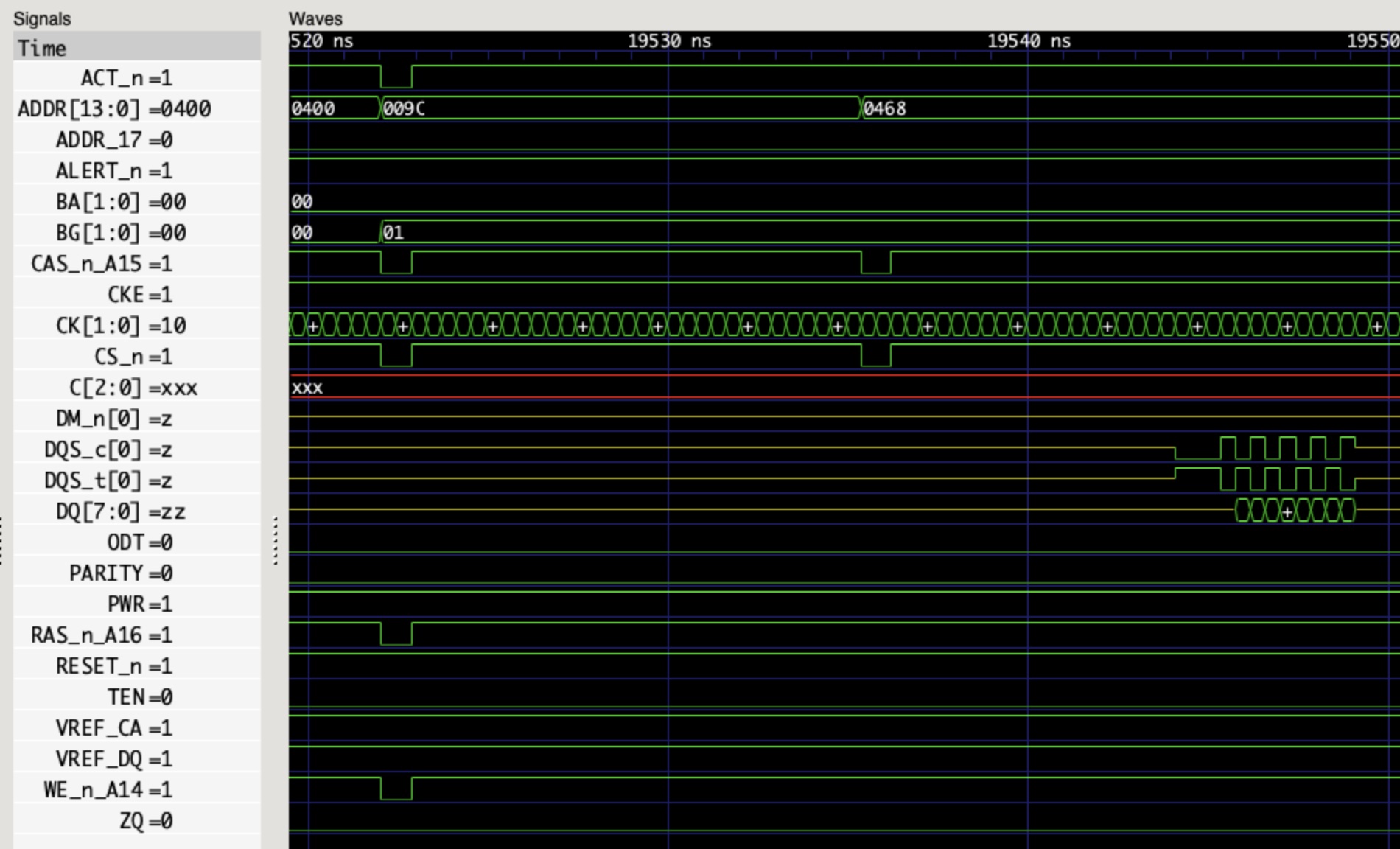
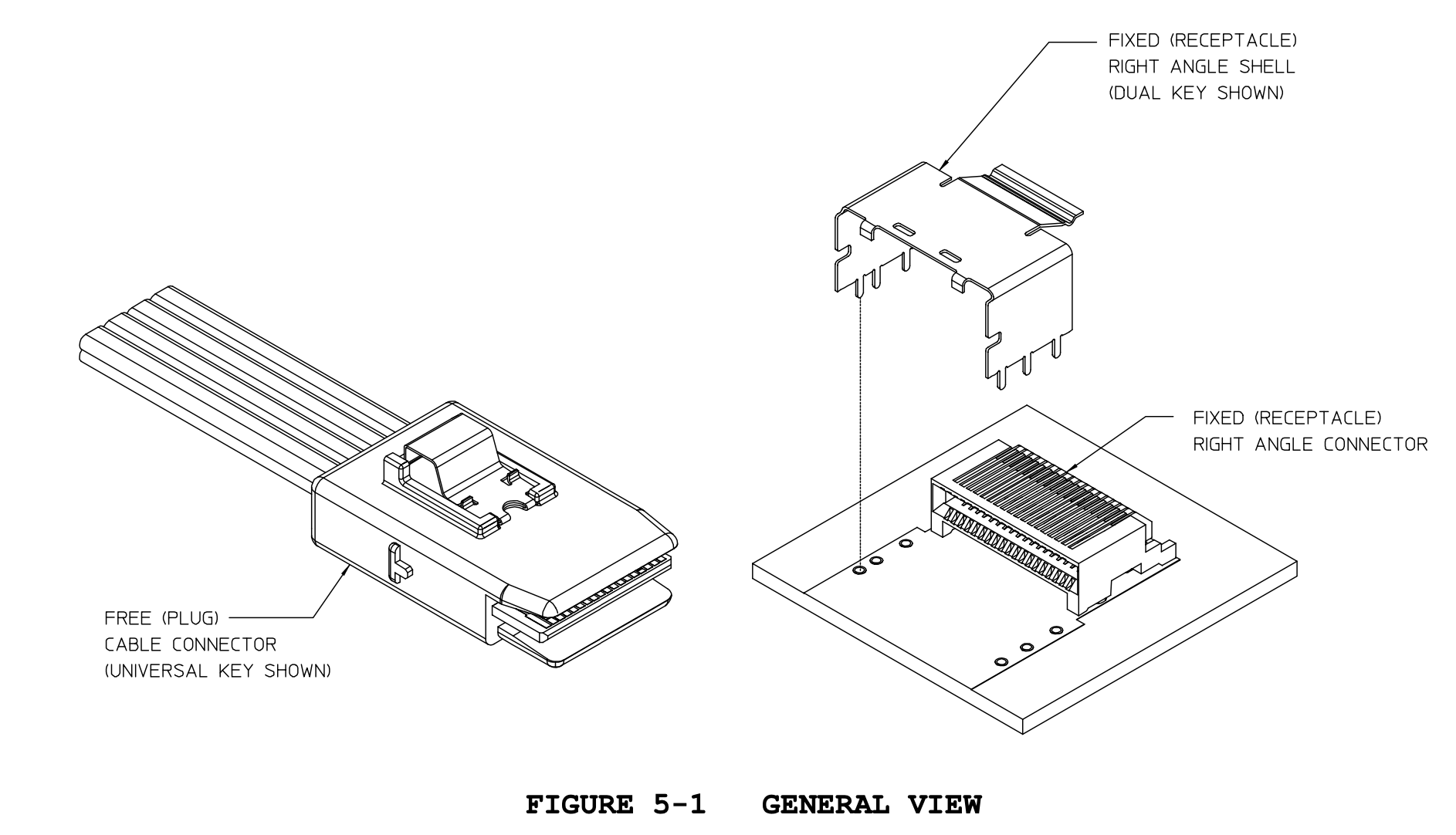
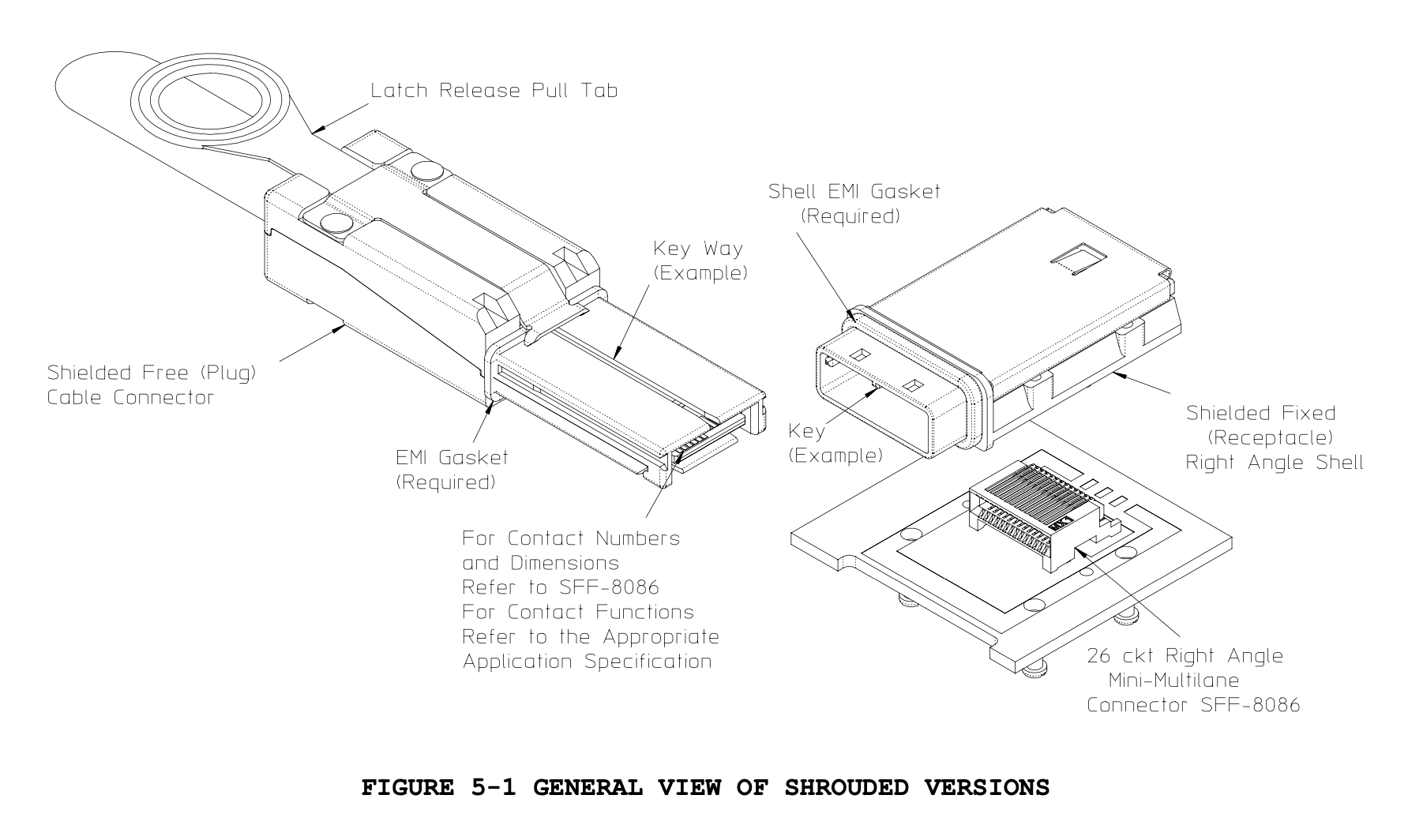
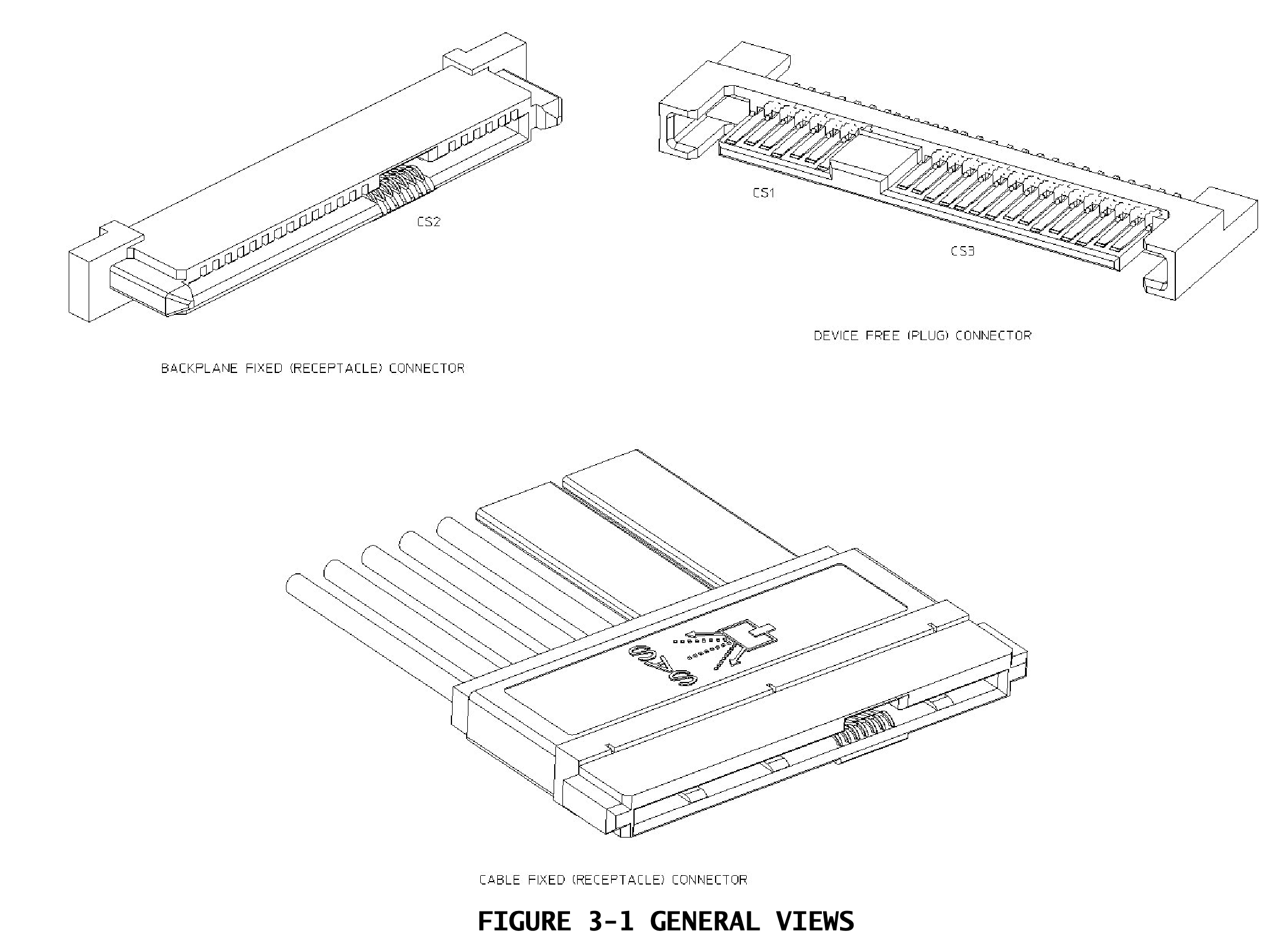
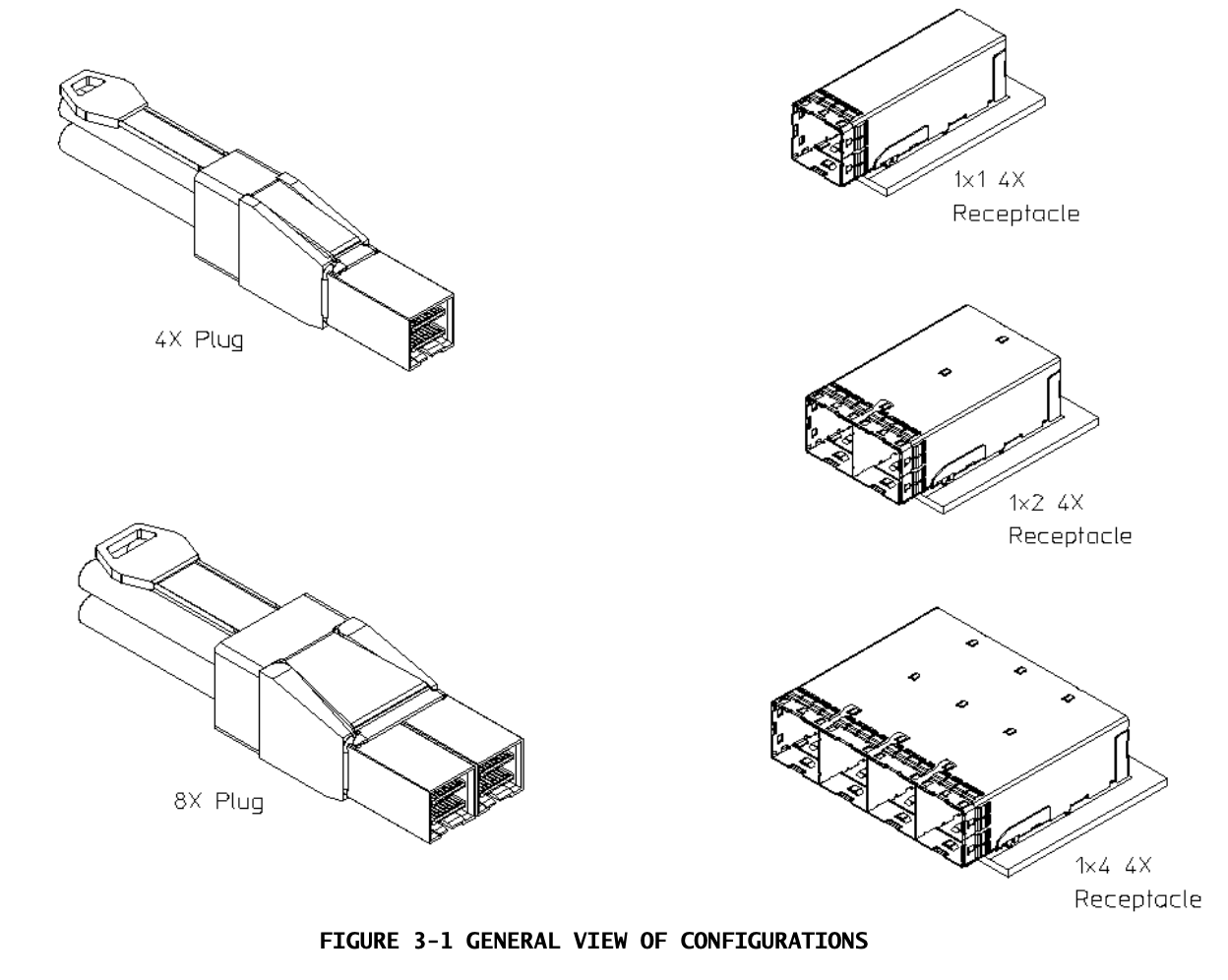
Read hit: The information is supplied by the current cache. No state change.
当 Read miss 的时候,会查看所有缓存,如果有其他缓存处于 Valid/Reserved/Dirty 状态,就从其他缓存处读取数据,然后设为 Valid,其他缓存也设为 Valid。如果其他缓存处于 Dirty 状态,还要把数据写入内存。
Read miss: The data is read from main memory. The read is snooped by other caches; if any of them have the line in the Dirty state, the read is interrupted long enough to write the data back to memory before it is allowed to continue. Any copies in the Dirty or Reserved states are set to the Valid state.
Write hit: If the information in the cache is in Dirty or Reserved state, the cache line is updated in place and its state is set to Dirty without updating memory. If the information is in Valid state, a write-through operation is executed updating the block and the memory and the block state is changed to Reserved. Other caches snoop the write and set their copies to Invalid.
当 Write miss 的时候,这个行为 Wikipedia 上和上课讲的不一样。按照 Wikipedia 的说法,首先按照 Read miss 处理,再按照 Write hit 处理,类似于 Write Allocate 的思路。如果是这样的话,那么首先从其他缓存或者内存读取数据,然后把其他缓存都设为 Invalid,把更新后的数据写入内存,进入 Reserved 状态。相当于 Write miss 的时候,也是按照 Write-through 实现。
Write miss: A partial cache line write is handled as a read miss (if necessary to fetch the unwritten portion of the cache line) followed by a write hit. This leaves all other caches in the Invalid state, and the current cache in the Reserved state.
一个稍微好一些的方法(Coarse bit vector format)是,我把核心分组,比如按照 NUMA 节点进行划分,此时每个缓存行都保存一个大小为 M(M 为 NUMA 数量)的位向量,只要这个 NUMA 节点里有这个缓存行,对应位就取 1。这样相当于是以牺牲一部分流量为代价(NUMA 节点内部广播),来节省一些目录的存储空间。
For DDR3 SDRAM interfaces running at or below 800 Mb/s (400 MHz),
users have the option of selecting Internal VREF to save two I/O
pins or using external VREF. VREF is required for banks containing
DDR3 interface input pins (DQ/DQS).
进一步,Xilinx 在 UltraScale 文档下解释了背后的原因:
The UltraScale internal VREF circuit includes enhancements compared
to the 7 Series internal VREF circuit. Whereas 7 Series MIG had datarate
limitations on internal VREF usage (see (Xilinx Answer 42036)), internal
VREF is recommended in UltraScale. The VREF for 7 Series had coarse steps
of VREF value that were based on VCCAUX. This saved pins but limited the
performance because VCCAUX did not track with VCCO as voltage went up and
down. Not being able to track with VCCO enforced the performance
limitations of internal VREF in MIG 7 Series. UltraScale includes several
changes to internal VREF including a much finer resolution of VREF for DDR4
read VREF training. Additionally, internal VREF is based on the VCCO supply
enabling it to track with VCCO. Internal VREF is not subject to PCB and
Package inductance and capacitance. These changes in design now give internal
VREF the highest performance.
用中文简单来说:
7 Series FPGA 中,Internal VREF 可以节省引脚,代价是 VREF 不会随着 VCCO 变化而变化(而是随着 VCCAUX 变化而变化),当 DRAM 频率提高的时候,可能无法满足 VREF 约等于 VDD 一半的要求
如果研究 DRAM 内存控制器,比如 FPGA 上的 MIG,可以发现它可以配置不同的地址映射方式,例如:
ROW_COLUMN_BANK
ROW_BANK_COLUMN
BANK_ROW_COLUMN
ROW_COLUMN_LRANK_BANK
ROW_LRANK_COLUMN_BANK
ROW_COLUMN_BANK_INTLV
就是将地址的不同部分映射到 DRAM 的几个地址:Row,Column,Bank。可以想象,不同的地址映射方式针对不同的访存模式会有不同的性能。对于连续的内存访问,ROW_COLUMN_BANK 方式是比较适合的,因为连续的访问会分布到不同的 Bank 上,这样性能就会更好。
此外,如果访问会连续命中同一个 Page,那么直接读写即可;反之如果每次读写几乎都不会命中同一个 Page,那么可以设置 Auto Precharge,即读写以后自动 Precharge,减少了下一次访问前因为 Row 不同导致的 PRE 命令。一个思路是在对每个 Page 的最后一次访问采用 Auto Precharge。
但是从八字班(2018)开始,多重因素下,问题就凸显了。一是总人数更多,保研难度本身就更大,竞争激烈;二是保研名额严格按照 GPA 排序,导致保研的同学必须科研学习两手抓;三是 GPA 改革以后,4.0 难度变低,以前会想 A B C 课程比较难,大部分人都拿不到 4.0,我 A 课程 3.7,B 课程 3.3 和你 A 课程 3.3,B 课程 3.7 是一样的,精力有限,只做三个里面最简单的一个,但现在会发现,比 GPA 实际上就是比谁 4.0 更多,虽然 A B C 课程也比较难,但是此时只能把三个都做了,不然就会排名下降明显。
在新闻稿和 Sunway supercomputer architecture towards exascale computing: analysis and practice 文章中出现,没有在今年发出来的论文里实际采用,名称可能是新闻稿自己编的,我猜可能没有实际采用,而是做了 SW26010P。和 SW26010 区别:
Performance improvements for AMD Zen CPUs: With ESXi 7.0 Update 2, out-of-the-box optimizations can increase AMD Zen CPU performance by up to 30% in various benchmarks. The updated ESXi scheduler takes full advantage of the AMD NUMA architecture to make the most appropriate placement decisions for virtual machines and containers. AMD Zen CPU optimizations allow a higher number of VMs or container deployments with better performance.
Reduced compute and I/O latency, and jitter for latency sensitive workloads: Latency sensitive workloads, such as in financial and telecom applications, can see significant performance benefit from I/O latency and jitter optimizations in ESXi 7.0 Update 2. The optimizations reduce interference and jitter sources to provide a consistent runtime environment. With ESXi 7.0 Update 2, you can also see higher speed in interrupt delivery for passthrough devices.
vSphere Lifecycle Manager fast upgrades: Starting with vSphere 7.0 Update 2, you can configure vSphere Lifecycle Manager to suspend virtual machines to memory instead of migrating them, powering them off, or suspending them to disk. For more information, see Configuring vSphere Lifecycle Manager for Fast Upgrades.
Zero downtime, zero data loss for mission critical VMs in case of Machine Check Exception (MCE) hardware failure: With vSphere 7.0 Update 3, mission critical VMs protected by VMware vSphere Fault Tolerance can achieve zero downtime, zero data loss in case of Machine Check Exception (MCE) hardware failure, because VMs fallback to the secondary VM, instead of failing. For more information, see How Fault Tolerance Works.
如果物理机的硬盘正在用(比如是保存 rootfs 的硬盘),建议重启到 Live CD(可以通过 BMC 挂着 Virtual Media),小心 Live CD 有没有网卡驱动和网卡固件。
本地导出:
# -p: progress# -O vmdk: output as vmdk# -o subformat=streamOptimized: thin provisioning# output file should be put in places other that /dev/sdaqemu-imgconvert-p-Ovmdk-osubformat=streamOptimized/dev/sdaxxx.vmdk
远程导出:
# on the source machine# expose raw /dev/sda as network block deviceqemu-nbd-fraw/dev/sda
# on the destination machine# -p: progress# -O vmdk: output as vmdk# -o subformat=streamOptimized: thin provisioningqemu-imgconvert-p-Ovmdk-osubformat=streamOptimizednbd://$SOURCE_IPxxx.vmdk
#### Max Tco
set tco_max 7
#### Min Tco
set tco_min 1
#### Setup time requirement
set tsu 2
#### Hold time requirement
set th 3
#### Trace delay
set tdata_trace_delay_max 0.25
set tdata_trace_delay_min 0.25
set tclk_trace_delay_max 0.2
set tclk_trace_delay_min 0.2
# You must provide all the delay numbers
# CCLK delay is 0.5, 6.7 ns min/max for K7-2; refer Data sheet
# Consider the max delay for worst case analysis
set cclk_delay 6.7
# Following are the SPI device parameters
# Max Tco
set tco_max 7
# Min Tco
set tco_min 1
# Setup time requirement
set tsu 2
# Hold time requirement
set th 3
# Following are the board/trace delay numbers
# Assumption is that all Data lines are matched
set tdata_trace_delay_max 0.25
set tdata_trace_delay_min 0.25
set tclk_trace_delay_max 0.2
set tclk_trace_delay_min 0.2
### End of user provided delay numbers
# this is to ensure min routing delay from SCK generation to STARTUP input
# User should change this value based on the results
# having more delay on this net reduces the Fmax
set_max_delay 1.5 -from [get_pins -hier *SCK_O_reg_reg/C] -to [get_pins -hier
*USRCCLKO] -datapath_only
set_min_delay 0.1 -from [get_pins -hier *SCK_O_reg_reg/C] -to [get_pins -hier
*USRCCLKO]
# Following command creates a divide by 2 clock
# It also takes into account the delay added by STARTUP block to route the CCLK
create_generated_clock -name clk_sck -source [get_pins -hierarchical
*axi_quad_spi_1/ext_spi_clk] [get_pins -hierarchical *USRCCLKO] -edges {3 5 7}
-edge_shift [list $cclk_delay $cclk_delay $cclk_delay]
# Data is captured into FPGA on the second rising edge of ext_spi_clk after the SCK
falling edge
# Data is driven by the FPGA on every alternate rising_edge of ext_spi_clk
set_input_delay -clock clk_sck -max [expr $tco_max + $tdata_trace_delay_max +
$tclk_trace_delay_max] [get_ports IO*_IO] -clock_fall;
set_input_delay -clock clk_sck -min [expr $tco_min + $tdata_trace_delay_min +
$tclk_trace_delay_min] [get_ports IO*_IO] -clock_fall;
set_multicycle_path 2 -setup -from clk_sck -to [get_clocks -of_objects [get_pins
-hierarchical */ext_spi_clk]]
set_multicycle_path 1 -hold -end -from clk_sck -to [get_clocks -of_objects [get_pins
-hierarchical */ext_spi_clk]]
# Data is captured into SPI on the following rising edge of SCK
# Data is driven by the IP on alternate rising_edge of the ext_spi_clk
set_output_delay -clock clk_sck -max [expr $tsu + $tdata_trace_delay_max -
$tclk_trace_delay_min] [get_ports IO*_IO];
set_output_delay -clock clk_sck -min [expr $tdata_trace_delay_min - $th -
$tclk_trace_delay_max] [get_ports IO*_IO];
set_multicycle_path 2 -setup -start -from [get_clocks -of_objects [get_pins
-hierarchical */ext_spi_clk]] -to clk_sck
set_multicycle_path 1 -hold -from [get_clocks -of_objects [get_pins -hierarchical */
ext_spi_clk]] -to clk_sck
$iptables-save-tnat
# Generated by xtables-save v1.8.2 on Sat Sep 18 10:44:49 2021*nat
:PREROUTINGACCEPT[0:0]:INPUTACCEPT[0:0]:POSTROUTINGACCEPT[0:0]:OUTPUTACCEPT[0:0]:DOCKER-[0:0]-APREROUTING-maddrtype--dst-typeLOCAL-jDOCKER
-APOSTROUTING-s172.17.0.0/16!-odocker0-jMASQUERADE
-AOUTPUT!-d127.0.0.0/8-maddrtype--dst-typeLOCAL-jDOCKER
-ADOCKER-idocker0-jRETURN
COMMIT
# Completed on Sat Sep 18 10:44:49 2021
简单试了一下,发现 dracut 的 initramfs 里程序太少了,调试起来很痛苦。所以,我在 BMC 里通过 Virtual Media 挂了一个 Arch Linux 的 Live CD。因为通过 Web 访问延迟太高,我设了一个 root 密码,然后直接 ssh 到 live cd 系统中。
Thank you for bringing this to our attention. We have verified and
encountered the same issue. Please know that we have escalated this
issue to our backend technical team.
We will get back to you as soon as we have an update. Have a nice day
ahead!
We have received an update from our backend team is that they are
working on this issue and, a more permanent fix is in the works.
Hopefully, it will resolve soon.
We appreciate your patience and understanding on this matter. Have a
nice day!
Thank you for your prompt response. We are glad that your issue has been
resolved and we would like to thank you for your co operation. Please
be informed that the offline version of the Intrinsic Guide is now
available for download from the site. The offline version of the guide
has the same content as the site, but is viewable offline by the user. A
link to the download is now added in the left column of the site:
https://software.intel.com/sites/landingpage/IntrinsicsGuide/
That said, we are closing this ticket and if you have further issues
please open another ticket and we will be happy to help you.
After case closure, you will receive a survey email. We appreciate it if
you can complete this survey regarding the support you received. Your
feedback will help us improve our support.
For any concerns related to Intel® Developer Zone account, login or
website, please feel free to open a new ticket:
https://software.intel.com/en-us/support
这次 Intel Support 的反应挺快的,给个好评。就是希望 Intel 能够不挤牙膏,能拿出和 AMD 相当水平的 CPU。
继续研究后,发现是硬盘满了。Nginx 在处理 POST body 的时候,如果 body 超过阈值,会写入到临时文件中:
Syntax: client_body_buffer_size size;
Default: client_body_buffer_size 8k|16k;
Context: http, server, location
Sets buffer size for reading client request body. In case the request body is larger than the buffer, the whole body or only its part is written to a temporary file. By default, buffer size is equal to two memory pages. This is 8K on x86, other 32-bit platforms, and x86-64. It is usually 16K on other 64-bit platforms.
In addition, the following catalog of abbreviations of the form "Sx" are used:
<substitution> ::= St # ::std::
<substitution> ::= Sa # ::std::allocator
<substitution> ::= Sb # ::std::basic_string
<substitution> ::= Ss # ::std::basic_string < char,
::std::char_traits<char>,
::std::allocator<char> >
<substitution> ::= Si # ::std::basic_istream<char, std::char_traits<char> >
<substitution> ::= So # ::std::basic_ostream<char, std::char_traits<char> >
<substitution> ::= Sd # ::std::basic_iostream<char, std::char_traits<char> >