PCIe Bifurcation
本文的内容已经整合到知识库中。
背景
最近看到两篇关于 PCIe Bifurcation 的文章:
文章讲的是如何在 CPU 上进行跳线,从而实现 PCIe Bifurcation 的配置。正好借此机会来研究一下 PCIe Bifurcation。
本文的内容已经整合到知识库中。
最近看到两篇关于 PCIe Bifurcation 的文章:
文章讲的是如何在 CPU 上进行跳线,从而实现 PCIe Bifurcation 的配置。正好借此机会来研究一下 PCIe Bifurcation。
本文的内容已经整合到知识库中。
InfiniBand 的网络分为两层,第一层是由 End Node 和 Switch 组成的 Subnet,第二层是由 Router 连接起来的若干个 Subnet。有点类似以太网以及 IP 的关系,同一个二层内通过 MAC 地址转发,三层间通过 IP 地址转发。
在 IB 网络中,End Node 一般是插在结点上的 IB 卡(Host Channel Adapter,HCA)或者是存储结点上的 Target Channel Adapter。End Node 之间通过 Switch 连接成一个 Subnet,由 Subnet Manager 给每个 Node 和 Switch 分配 Local ID,同一个 Subnet 中通过 LID(Local ID)来路由。但是 LID 位数有限,为了进一步扩展,可以用 Router 连接多个 Subnet,此时要通过 GID(Global ID)来路由。
最近发现有一台机器,插上 ConnectX-4 IB 网卡后,内核模块可以识别到设备,但是无法使用,现象是 ibstat 等命令都看不到设备。降级 OFED 从 5.8 到 5.4 以后问题消失,所以认为可能是新的 OFED 与比较旧的固件版本有兼容性问题,所以尝试升级网卡固件。升级以后,问题就消失了。
首先,在 https://network.nvidia.com/products/adapter-software/firmware-tools/ 下载 MFT,按照指示解压,安装后,启动 mst 服务,就可以使用 mlxfwmanager 得到网卡的型号以及固件版本:
Device Type: ConnectX4
Description: Mellanox ConnectX-4 Single Port EDR PCIE Adapter LP
PSID: DEL2180110032
Versions: Current
FW 12.20.1820
从 PSID 可以看到,这是 DELL OEM 版本的网卡,可以在 https://network.nvidia.com/support/firmware/dell/ 处寻找最新固件,注意需要保证 PSID 一致,可以找到这个 PSID 的 DELL 固件地址:https://www.mellanox.com/downloads/firmware/fw-ConnectX4-rel-12_28_4512-06W1HY_0JJN39_Ax-FlexBoot-3.6.203.bin.zip。
下载以后,解压,然后就可以升级固件:
升级以后重启就工作了。
考虑到类似的情况之后还可能发生,顺便还升级了其他几台机器的网卡,下面是一个例子:
Device Type: ConnectX4
Description: ConnectX-4 VPI adapter card; FDR IB (56Gb/s) and 40GbE; dual-port QSFP28; PCIe3.0 x8; ROHS R6
PSID: MT_2170110021
Versions: Current
FW 12.25.1020
注意这里的 PSID 是 MT_ 开头,说明是官方版本。这个型号可以在 https://network.nvidia.com/support/firmware/connectx4ib/ 找到最新的固件,注意 PSID 要正确,可以找到固件下载地址 https://www.mellanox.com/downloads/firmware/fw-ConnectX4-rel-12_28_2006-MCX454A-FCA_Ax-UEFI-14.21.17-FlexBoot-3.6.102.bin.zip。用同样的方法更新即可。
还有一个 ConnectX-3 的例子:
Device Type: ConnectX3
Description: ConnectX-3 VPI adapter card; single-port QSFP; FDR IB (56Gb/s) and 40GigE; PCIe3.0 x8 8GT/s; RoHS R6
PSID: MT_1100120019
Versions: Current
FW 2.36.5150
ConnectX-3 系列的网卡固件可以在 https://network.nvidia.com/support/firmware/connectx3ib/ 找,根据 PSID,可以找到固件下载地址是 http://www.mellanox.com/downloads/firmware/fw-ConnectX3-rel-2_42_5000-MCX353A-FCB_A2-A5-FlexBoot-3.4.752.bin.zip。
如果遇到 Mellanox 网卡能识别 PCIe,但是不能使用,可以考虑降级 OFED 或者升级网卡固件。
可以用 mlxfwmanager 查看 PSID 和更新固件。根据 PSID,判断是 OEM(DELL)版本还是官方版本。如果是 OEM 版本,要到对应 OEM 的固件下载地址找,例如 https://network.nvidia.com/support/firmware/dell/;如果是官方版,在 https://network.nvidia.com/support/firmware/firmware-downloads/ 找。
本文的内容已经整合到知识库中。
最近在知乎上看到 LogicJitterGibbs 的 资料整理:可以学习 1W 小时的 PCIe,我跟着资料学习了一下,然后在这里记录一些我学习 PCIe 的笔记。
以前买过 RTL-SDR,用 Gqrx 做过收音机,当时还给 Homebrew 尝试提交过几个 sdr 相关的 pr,但是限于知识的缺乏,后来就没有再继续尝试了。
前两天,@OceanS2000 讲了一次 Tunight: 高级收音机使用入门,又勾起了我的兴趣,所以我来尝试一下在 GNURadio Companion 中收听 FM 广播电台。
我没有上过无线电相关课程,所以下面有一些内容可能不正确或者不准确。
本文的内容已经整合到知识库中。
最近在研究如何把 Wishbone 总线协议引入计算机组成原理课程,因此趁此机会学习了一下 Wishbone 的协议。
总线是什么?总线通常用于连接 CPU 和外设,为了更好的兼容性和可复用性,会想到能否设计一个统一的协议,其中 CPU 实现的是发起请求的一方(又称为 master),外设实现的是接收请求的一方(又称为 slave),那么如果要添加外设、或者替换 CPU 实现,都会变得比较简单,减少了许多适配的工作量。
那么,我们来思考一下,一个总线协议需要包括哪些内容?对于 CPU 来说,程序会读写内存,读写内存就需要以下几个信号传输到内存:
addr):例如 32 位处理器就是 32 位地址,或者按照内存的大小计算地址线的宽度w_data 和 r_data):分别是写数据和读数据,宽度通常为 32 位 或 64 位,也就是一个时钟周期可以传输的数据量we):高表示写,低表示读be):例如为了实现单字节写,虽然 w_data 可能是 32 位宽,但是实际写入的是其中的一个字节除了请求的内容以外,为了表示 CPU 想要发送请求,还需要添加 valid 信号:高表示发送请求,低表示不发送请求。很多时候,外设的速度比较慢,可能无法保证每个周期都可以处理请求,因此外设可以提供一个 ready 信号:当 valid=1 && ready=1 的时候,发送并处理请求;当 valid=1 && ready=0 的时候,表示外设还没有准备好,此时 CPU 需要一直保持 valid=1 不变,等到外设准备好后,valid=1 && ready=1 请求生效。
简单总结一下上面的需求,可以得到 master 和 slave 端分别的信号列表。这次,我们在命名的时候用 _o 表示输出、_i 表示输入,可以得到 master 端(CPU 端)的信号:
clock_i:时钟输入valid_o:高表示 master 想要发送请求ready_i:高表示 slave 准备好处理请求addr_o:master 想要读写的地址we_o:master 想要读还是写data_o:master 想要写入的数据be_o:master 读写的字节使能,用于实现单字节写等data_i:slave 提供给 master 的读取的数据除了时钟都是输入以外,把上面其余的信号输入、输出对称一下,就可以得到 slave 端(外设端)的信号:
clock_i:时钟输入valid_i:高表示 master 想要发送请求ready_o:高表示 slave 准备好处理请求addr_i:master 想要读写的地址we_i:master 想要读还是写data_i:master 想要写入的数据be_i:master 读写的字节使能,用于实现单字节写等data_o:slave 提供给 master 的读取的数据根据我们上面设计的自研总线,可以绘制出下面的波形图(以 master 的信号为例):
a 周期:此时 valid_o=1 && ready_i=1 说明有请求发生,此时 we_o=1 说明是一个写操作,并且写入地址是 addr_o=0x01,写入的数据是 data_o=0x12b 周期:此时 valid_o=0 && ready_i=0 说明无事发生c 周期:此时 valid_o=1 && ready_i=0 说明 master 想要从地址 0x02(addr_o=0x02)读取数据(we_o=0),但是 slave 没有接受(ready_i=0)d 周期:此时 valid_o=1 && ready_i=1 说明有请求发生,master 从地址 0x02(addr_o=0x02)读取数据(we_o=0),读取的数据为 0x34(data_i=0x34)e 周期:此时 valid_o=0 && ready_i=0 说明无事发生f 周期:此时 valid_o=1 && ready_i=1 说明有请求发生,master 向地址 0x03(addr_o=0x03)写入数据(we_o=1),写入的数据为 0x56(data_i=0x56)g 周期:此时 valid_o=1 && ready_i=1 说明有请求发生,master 从地址 0x01(addr_o=0x01)读取数据(we_o=0),读取的数据为 0x12(data_i=0x12)h 周期:此时 valid_o=1 && ready_i=1 说明有请求发生,master 向地址 0x02(addr_o=0x02)写入数据(we_o=1),写入的数据为 0x9a(data_i=0x9a)从上面的波形中,可以有几点观察:
valid_o=1;当 slave 可以接受请求的时候,就设置 ready_i=1;在 valid_o=1 && ready_i=1 时视为一次请求valid_o=1 && ready_i=0,此时 master 要保持 addr_o we_o data_o 和 be_o 不变,直到请求结束valid_o=0,此时总线上的信号都视为无效数据,不应该进行处理;对于读操作,只有在 valid_o=1 && ready_i=1 时 data_i 上的数据是有效的valid_o=1 && ready_i=1 连续多个周期等于一,此时是理想情况,可以达到总线最高的传输速度首先我们来看最简单的 Wishbone 版本 Wishbone Classic Standard。其设计思路和上面的自研总线非常相似,让我们来看看它的信号,例如 master 端(CPU 端)的信号:
CLK_I: 时钟输入,即自研总线中的 clock_iSTB_O:高表示 master 要发送请求,即自研总线中的 valid_oACK_I:高表示 slave 处理请求,即自研总线中的 ready_iADR_O:master 想要读写的地址,即自研总线中的 addr_oWE_O:master 想要读还是写,即自研总线中的 we_oDAT_O:master 想要写入的数据,即自研总线中的 data_oSEL_O:master 读写的字节使能,即自研总线中的 be_oDAT_I:master 从 slave 读取的数据,即自研总线中的 data_iCYC_O:总线的使能信号,无对应的自研总线信号还有一些可选信号,这里就不赘述了。可以看到,除了最后一个 CYC_O,其他的信号其实就是我们刚刚设计的自研总线。CYC_O 的可以认为是 master 想要占用 slave 的总线接口,在常见的使用场景下,直接认为 CYC_O=STB_O。它的用途是:
把上面自研总线的波形图改成 Wishbone Classic Standard,就可以得到:
上面的 Wishbone Classic Standard 协议非常简单,但是会遇到一个问题:假设实现的是一个 SRAM 控制器,它的读操作有一个周期的延迟,也就是说,在这个周期给出地址,需要在下一个周期才可以得到结果。在 Wishbone Classic Standard 中,就会出现下面的波形:
a 周期:master 给出读地址 0x01,此时 SRAM 控制器开始读取,但是此时数据还没有读取回来,所以 ACK_I=0b 周期:此时 SRAM 完成了读取,把读取的数据 0x12 放在 DAT_I 并设置 ACK_I=1c 周期:master 给出下一个读地址 0x02,SRAM 要重新开始读取d 周期:此时 SRAM 完成了第二次读取,把读取的数据 0x34 放在 DAT_I 并设置 ACK_I=1从波形来看,功能没有问题,但是每两个周期才能进行一次读操作,发挥不了最高的性能。那么怎么解决这个问题呢?我们在 a 周期给出第一个地址,在 b 周期得到第一个数据,那么如果能在 b 周期的时候给出第二个地址,就可以在 c 周期得到第二个数据。这样,就可以实现流水线式的每个周期进行一次读操作。但是,Wishbone Classic Standard 要求 b 周期时第一次请求还没有结束,因此我们需要修改协议,来实现流水线式的请求。
实现思路也很简单:既然 Wishbone Classic Standard 认为 b 周期时,第一次请求还没有结束,那就让第一次请求提前在 a 周期完成,只不过它的数据要等到 b 周期才能给出。实际上,这个时候的一次读操作,可以认为分成了两部分:首先是 master 向 slave 发送读请求,这个请求在 a 周期完成;然后是 slave 向 master 发送读的结果,这个结果在 b 周期完成。为了实现这个功能,我们进行如下修改:
STALL_I 信号:CYC_O=1 && STB_O=1 && STALL_I=0 表示进行一次读请求ACK_I 信号含义:CYC_O=1 && STB_O=1 && ACK_I=1 表示一次读响应进行如上修改以后,我们就得到了 Wishbone Classic Pipelined 总线协议。上面的两次连续读操作波形如下:
a 周期:master 请求读地址 0x01,slave 接收读请求(STALL_O=0)b 周期:slave 返回读请求结果 0x12,并设置 ACK_I=1;同时 master 请求读地址 0x02,slave 接收读请求(STALL_O=0)c 周期:slave 返回读请求结果 0x34,并设置 ACK_I=1;master 不再发起请求,设置 STB_O=0d 周期:所有请求完成,master 设置 CYC_O=0这样我们就实现了一个每周期进行一次读操作的 slave。
在一些场合里,我们会使用异步的(即没有时钟信号的)外部 SRAM 来存储数据,而我们经常使用的很多外部接口都是同步接口(即有时钟信号的接口),比如 SPI 和 I2C 等等,UART 虽然是异步,但是它速度很低,不怎么需要考虑时序的问题。所以在 FPGA 上编写一个正确的异步 SRAM 控制器是具有一定的挑战的。
考虑到读者可能已经不记得寄存器的时序了,这里首先来复习一下 setup 和 hold 的概念。如果你已经比较熟悉了,可以直接阅读下一节。
寄存器在时钟的上升沿(下图的 a)进行采样,为了保证采样的稳定性,输入引脚 D 需要在时钟上升沿之前 \(t_{su}\) 的时刻(下图的 b)到时钟上升沿之后 \(t_h\) 的时刻(下图的 c)保持稳定,输出引脚 Q 会在时钟上升沿之后 \(t_{cko}\) 的时刻(下图的 d)变化:
首先我们来看看异步 SRAM 的接口。下文中,采用 IS61WV102416BLL-10TLI 和 AS7C34098A-10TCN 作为例子:

可以看到,它有 20 位的地址,16 位的数据,若干个控制信号,同时只能进行读或者写(简称 1RW)。它没有时钟信号,所以是异步 SRAM。
对于一个同步接口,我们通常只需要给一个满足时钟周期的时钟,然后通过约束文件保证 setup 和 hold 条件满足即可。但是对于异步接口,由于输出的时候没有时钟,我们需要更小心地完成这件事情。
首先来看一下比较简单的读时序:
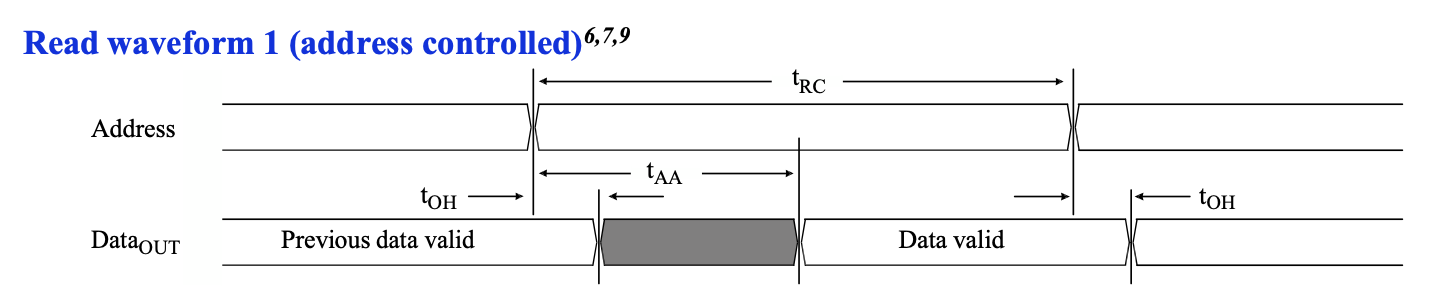
可以看到地址和数据的关系:首先是地址需要稳定 \(t_{RC}\) 的时间,那么数据合法的范围是地址稳定的初始时刻加上 \(t_{AA}\),到地址稳定的结束时刻加上 \(t_{OH}\)。我们再来看一下这几个时间的范围:
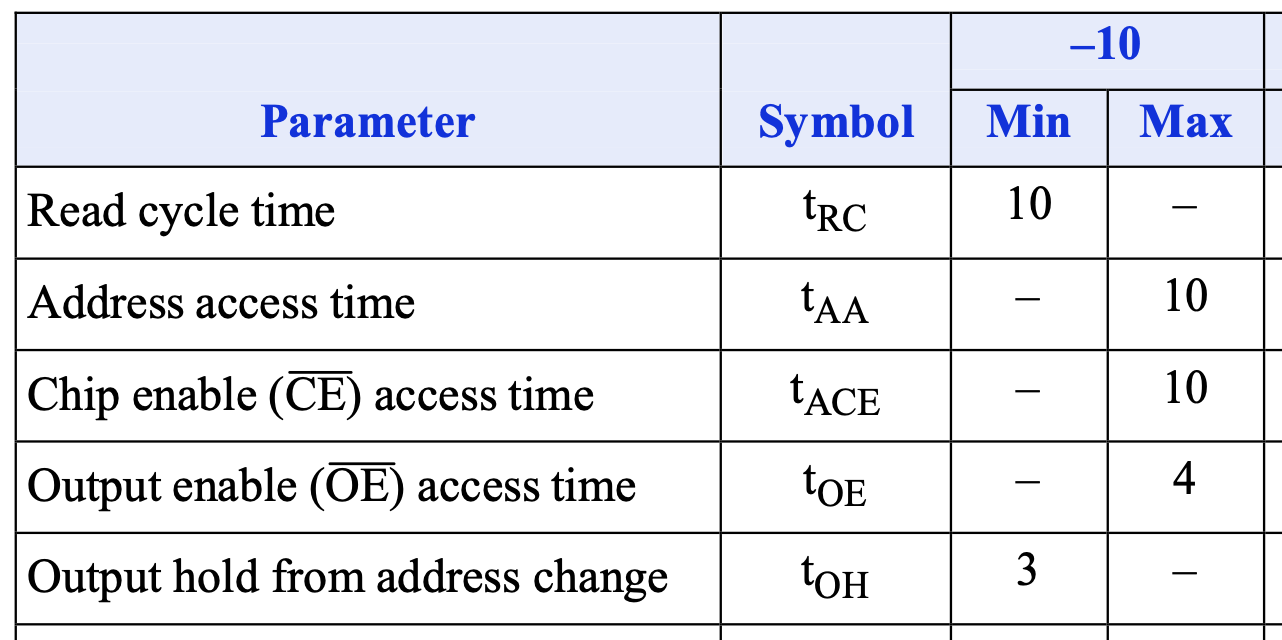
首先可以看到读周期时间 \(t_{RC}\) 至少是 10ns,这对应了型号中最后的数字,这表示了这个 SRAM 最快的读写速度。比较有意思的是 \(t_{AA}\) 最多是 10ns,刚好和 \(t_{RC}\) 的最小值相等。
接下来我们考虑一下如何为 SRAM 控制器时序读取的功能。看到上面的波形图,大概可以想到几条设计思路:
简单起见,先设置一个非常快的 SRAM 控制器频率:500MHz,每个周期 2ns,假如在 a 时刻地址寄存器输出了当前要读取的地址,那么数据会在一段时间后变为合法。这里 a->b 是读取周期时间 \(t_{RC}\),a->c 是地址到数据的延迟 \(t_{AA}\),b->d 是地址改变后数据的保持时间 \(t_{OH}\)。
那么根据这个图,很自然的想法是,我先给出地址,然后数周期,数了五个周期后,此时 \(t_{RC}=10\mathrm{ns}\),然后我就在 e 的上升沿上把输入数据锁存到寄存器中,例如下面的波形:
这个时候 data_reg 的 setup 时间是 c->e,hold 时间是 e->d。从图中看起来还有很多的余量,但如果考虑最坏情况,\(t_{AA}=10\mathrm{ns}\),就会变成下面的波形:
这个时候在 e 时刻不再满足 setup 约束。这个问题在仿真中,可能会“极限操作”表现为没有问题,但实际上,地址从 FPGA 到 SRAM 的延迟有:
数据从 SRAM 到 FPGA 的延迟有:
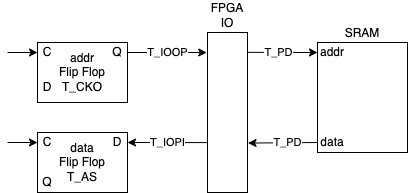
上面的一些数据可以从 Artix-7 FPGA Datasheet 里查到,取的是速度等级 -3 的数据,IO 标准是 LVCMOS33。其中寄存器到 FPGA 输入输出引脚的延迟,实际上由两部分组成:从寄存器到 IOB(IO Block)的延迟,以及 IOB 到 FPGA 输入输出引脚的延迟。我们把地址寄存器的输出作为地址输出,这样 Vivado 就会把寄存器放到 IOB,于是可以忽略寄存器到 IOB 的延迟,详情可以阅读文档 Successfully packing a register into an IOB with Vivado。
把上面一串加起来,已经有大概 4 到 5ns 了。考虑了延迟以后,上面的图可能实际上是这个样子:
考虑了这么多实际的延迟因素以后,会发现这个事情并不简单,需要预先估计出数据在大概什么时候稳定,这时候才能保证数据寄存器上保存的数据是正确的。
转念一想,我们的 SRAM Controller 肯定不会跑在 500MHz 这么高的频率下。假如采用 100MHz,可以每两个周期进行一次读操作:
此时在 b 时钟上边沿对 data_fpga 采样就可以保证满足时序的要求。注意这里第二个周期(上图的 a)不能给出第二次读取的地址,否则稳定时间太短,不满足 hold 约束。
如果频率继续降低,使得一个时钟周期大于 \(t_{AA}\) 加上各种延迟和 setup 时间,那就可以每个周期进行一次读操作:
此时在 a 时钟上升沿上,对 data_fpga 进行采样,并且输出下一次读请求的地址。
接下来再看看写时序。写时序涉及的信号更多,更加复杂一些,但好处是信号都是从 FPGA 到 SRAM,因此考虑延迟的时候会比较简单,比如上面读时序中需要考虑从 FPGA 到 SRAM 的地址,再从 SRAM 到 FPGA 的数据的路径。时序图如下:
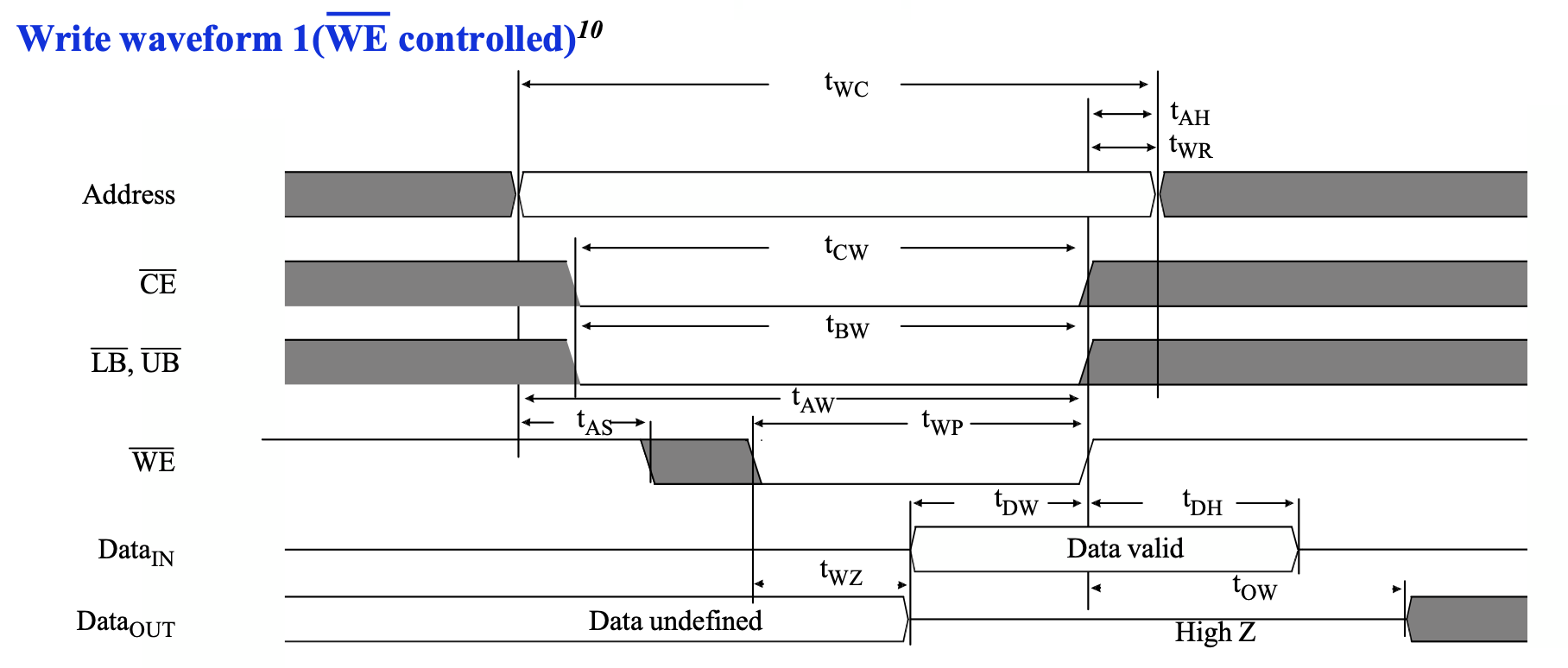
这个写的时序图,从时间顺序来看有这么几件事情按顺序发生:
这些数据的范围如下:
根据上面的分析,还是先考虑一个 500MHz 的 SRAM 控制器。控制器要写入的话,可以按照如下的顺序操作:
a)先输出要写入的地址和数据,并且设置好 ce_n, oe_n, we_n, ub_n 和 lb_n。c)设置 \(\overline{WE}\) 为低电平,这是为了满足 \(t_{AS}\) (下图的 a -> c)的条件c -> d),直到 \(t_{WP}\) (下图的 c -> d)和 \(t_{AW}\) (下图的 a -> d)时间满足条件d),等待若干个周期(下图的 d -> b),直到满足图中的 \(t_{WC}\) (下图的 a -> b)时间满足条件这时候你可能有点疑惑,之前分析读时序的时候,考虑了那么多延迟,为什么写的时候不考虑了?这是因为,写的时候所有的信号都是从 FPGA 输出到 SRAM 的,只要这些信号都是从寄存器直接输出,它们的延迟基本是一样的,所以在 FPGA 侧是什么波形,在 SRAM 侧也是什么波形(准确来说,数据信号因为输出是三态门,所以延迟会稍微高一点,但是由于数据信号的时序余量很大,这个额外的延迟可以忽略不计)。
这时候你可能又有一个疑惑了,在阅读 Datasheet 后发现,\(t_{AS}\) 最小是 0ns,那能不能在上图的 a 时刻就输出 we_n=0?答案是不行,虽然从波形上来看,是在同一个时钟上升沿更新,但实际上会有一微小的延迟差距,可能导致 we_n 在 addr 之前变化,这时候就可能导致 SRAM 观察到的地址是不稳定的。
再考虑一个比较实际的 100MHz 主频 SRAM 控制器,按照如下的波形,则是每三个周期进行一次写操作:
如果觉得这样做太过保守,想要提升性能,有如下几个可能的思路:
we_n=0 在时钟下降沿输出,但是编写的时候需要比较谨慎,比如先设置一个上升沿触发的寄存器,然后用另一个寄存器在下降沿对这个寄存器进行采样,再输出。we_n 的寄存器。ODELAY 自定义输出延迟原语,设置一个固定的输出延迟,比如 1ns。ODDR 原语,人为地添加一个大约 0.50ns 的延迟。we_n 设置一个最小的输出延迟(设置了一个很大的 hold),并且不允许输出 we_n 的寄存器放在 IOB 中(否则无法人为增加信号传播的路径长度)。约束:set_output_delay -clock [get_clocks sram_clk] -min -5.00 [get_ports sram_we_n] 和 set_property IOB FALSE [get_cells top/sram_controller/we_n_reg]。这里的信号和寄存器名称需要按照实际情况修改,第二个不允许放置在 IOB 的约束也可以在 Verilog 代码中用 (* IOB = "FALSE" *) 来实现。按照上面的思路实现,下面是可能达到的效果:
单周期:
双周期:
刚刚我们已经设计好了我们的 SRAM 控制器,再让我们来看看 ARM 提供的 SRAM 控制器时序是怎么样的:ARM 文档提供了 PrimeCell AHB SRAM/NOR Memory Controller (PL241) 的时序图。
读时序:

它第一个周期设置了 ce_n=0 和 addr,等待一个周期后,设置 oe_n=0,再等待两个周期,得到数据。
写时序:

它第一个周期设置了 ce_n=0 addr 和 data,等待一个周期后,设置 we_n=0,等待两个周期,再设置 we_n=1,这样就完成了写入。这和我们的实现是类似的:等待一个额外的周期,保证满足 we_n 下降时地址已经是稳定的。ARM 的文档里也写了如下的备注:
The timing parameter tWC is controlling the deassertion of smc_we_n_0. You can
use it to vary the hold time of smc_cs_n_0[3:0], smc_add_0[31:0] and
smc_data_out_0[31:0]. This differs from the read case where the timing
parameter tCEOE controls the delay in the assertion of smc_oe_n_0.
Additionally, smc_we_n_0 is always asserted one cycle after smc_cs_n_0[3:0] to
ensure the address bus is valid.
本文的内容已经整合到知识库中。
最近几天分析了 TileLink 的缓存一致性协议部分内容,见TileLink 总线协议分析,趁此机会研究一下之前尝试过研究,但是因为缺少一些基础知识而弃坑的 ACE 协议分析。
下面主要参考了 IHI0022E 的版本,也就是 AXI4 对应的 ACE 版本。
首先回顾一下一个缓存一致性协议需要支持哪些操作。对于较上一级 Cache 来说,它需要这么几件事情:
如果之前看过我的 TileLink 分析,那么上面的这些操作对应到 TileLink 就是:
秉承着这个思路,再往下看 ACE 的设计,就会觉得很自然了。
首先来看一下 ACE 的缓存状态模型,我在之前的缓存一致性协议分析中也分析过,它有这么五种,就是 MOESI 的不同说法:
文档中的定义如下:
大致理解的话,Unique 表示只有一个缓存有这个缓存行,Shared 表示有可能有多个缓存有这个缓存行;Clean 表示它不负责更新内存,Dirty 表示它负责更新内存。下面的很多操作都是围绕这些状态进行的。
文档中也说,它支持 MOESI 的不同子集:MESI, ESI, MEI, MOESI,所以也许在一个简化的系统里,一些状态可以不存在,实现会有所不同。
到目前为止,我还没有介绍 ACE 的信号,但是我们可以尝试一下,如果我们是协议的设计者,我们要如何添加信号来完成这个事情。
首先考虑上面提到的第一件事情:读或写 miss 的时候,需要请求这个缓存行的数据,并且更新自己的状态,比如读取到 Shared,写入到 Modified 等。
我们知道,AXI 有 AR 和 R channel 用于读取数据,那么遇到读或者写 miss 的时候,可以在 AR channel 上捎带一些信息,让下一级的 Interconnect 知道自己的意图是读还是写,然后 Interconnect 就在 R channel 上返回数据。
那么,具体要捎带什么信息呢?我们“不妨”用这样一种命名方式:操作 + 目的状态,比如我读 miss 的时候,需要读取数据,进入 Shared 状态,那就叫 ReadShared;我写 miss 的时候,需要读取数据(通常写入缓存的只是一个缓存行的一部分,所以先要把完整的读进来),那就叫 ReadUnique。这个操作可以编码到一个信号中,传递给 Interconnect。
再来考虑上面提到的第二件事情:写入一个 valid && !dirty 的缓存行的时候,需要升级自己的状态,比如从 Shared 到 Modified。
这个操作,需要让 Interconnect 把其他缓存中的这个缓存行数据清空,并且把自己升级到 Unique。根据上面的 操作 + 目的状态 的命名方式,我们可以命名为 CleanUnique,即把其他缓存都 Clean 掉,然后自己变成 Unique。
接下来考虑上面提到的第三件事情:需要 evict 一个 valid && dirty 的缓存行的时候,需要把 dirty 数据写回,并且降级自己的状态,比如 Modified -> Shared/Invalid。
按照前面的 操作 + 目的状态 命名法,可以命名为 WriteBackInvalid。ACE 实际采用的命名是 WriteBack。
终于到了第四件事情:收到 snoop 请求的时候,需要返回当前的缓存数据,并且更新状态。
既然 snoop 是从 Interconnect 发给 Master,在已有的 AR R AW W B channel 里没办法做这个事情,不然会打破已有的逻辑。那不得不添加一对 channel,比如我规定一个 AC channel 发送 snoop 请求,规定一个 C channel 让 master 发送响应,这样就可以了。这就相当于 TileLink 里面的 B channel(Probe 请求)和 C channel(ProbeAck 响应)。实际 ACE 和刚才设计的实际有一些区别,把 C channel 拆成了两个:CR 用于返回所有响应,CD 用于返回那些需要数据的响应。这就像 AW 和 W 的关系,一个传地址,一个传数据;类似地,CR 传状态,CD 传数据。
那么,接下来考虑一下 AC channel 上要发送什么请求呢?我们回顾一下上面已经用到的请求类型:需要 snoop 的有 ReadShared,ReadUnique 和 CleanUnique,不需要 snoop 的有 WriteBack。那我们直接通过 AC channel 把 ReadShared,ReadUnique 和 CleanUnique 这三种请求原样发送给需要 snoop 的 cache 那里就可以了。
Cache 在 AC channel 收到这些请求的时候,可以做相应的动作。由于 MOESI 协议下同样的请求可以有不同的响应方法,这里就不细说了。
这时候我们已经基本把 ACE 协议的信号和大题的工作流程推导出来了。哦,我们还忘了第五件事情:需要一个方法来通知下一级 Cache/Interconnect,告诉它第一和第二步完成了。TileLink 添加了一个额外的 E channel 来做这个事情,ACE 更加粗暴:直接用一对 RACK 和 WACK 信号来分别表示最后一次读和写已经完成。
关于 WACK 和 RACK 详见 What's the purpose for WACK and RACK for ACE and what's the relationship with WVALID and RVALID? 的讨论。
到这里就暂时不继续分析了,其他的很多请求类型是服务于更多场景,比如一次写整个 Cache Line 的话,就不需要读取已有的数据了;或者一次性读取完就不管了,或者这是一个不带缓存的加速器,DMA 等,有一些针对性的优化或者简化的处理,比如对于不带缓存的 master,可以简化为 ACE-Lite,比如 ARM 的 CCI-400 支持两个 ACE master 和 三个 ACE-Lite Master,这些 Master 可以用来接 GPU 等外设。再简化一下 ACE-Lite,就得到了 ACP(Accelerator Coherency Port)。
最后我们再把文章开头的五件事对应到 ACE 上,作为一个前后的呼应:
最近在尝试把核心作为一个 Tile 加到 Rocket System 中,所以想要把核心之前自定义的调试信号接到顶层上去。Rocket System 自带的支持是 trace,也就是输出每个周期 retire 的指令信息,但和自定义的不大一样,所以研究了一下怎么添加自定义的调试信号,并且连接到顶层。
首先,观察 Rocket Chip 自己使用的 Trace 信号是如何连接到顶层的。在顶层上,可以找到使用的是 testchipip.CanHaveTraceIO:
trait CanHaveTraceIO { this: HasTiles =>
val module: CanHaveTraceIOModuleImp
// Bind all the trace nodes to a BB; we'll use this to generate the IO in the imp
val traceNexus = BundleBridgeNexusNode[Vec[TracedInstruction]]()
val tileTraceNodes = tiles.flatMap {
case ext_tile: WithExtendedTraceport => None
case tile => Some(tile)
}.map { _.traceNode }
tileTraceNodes.foreach { traceNexus := _ }
}
可以看到,它采用了 diplomacy 的 BundleBridgeNexusNode,把每个 tile 取出来,把它的 traceNode 接到 traceNexus 上。再看一下模块 CanHaveTraceIOModuleImp 是怎么实现的:
trait CanHaveTraceIOModuleImp { this: LazyModuleImpLike =>
val outer: CanHaveTraceIO with HasTiles
implicit val p: Parameters
val traceIO = p(TracePortKey) map ( traceParams => {
val extTraceSeqVec = (outer.traceNexus.in.map(_._1)).map(ExtendedTracedInstruction.fromVec(_))
val tio = IO(Output(TraceOutputTop(extTraceSeqVec)))
val tileInsts = ((outer.traceNexus.in) .map { case (tileTrace, _) => DeclockedTracedInstruction.fromVec(tileTrace) }
// Since clock & reset are not included with the traced instruction, plumb that out manually
(tio.traces zip (outer.tile_prci_domains zip tileInsts)).foreach { case (port, (prci, insts)) =>
port.clock := prci.module.clock
port.reset := prci.module.reset.asBool
port.insns := insts
}
tio
})
}
可以看到,它从 traceNexus 上接了若干的 trace 信号,然后通过 IO(TraceOutputTop()) 接到了顶层的输出信号。
再来看看 Rocket 是如何连接的,首先是 traceNode 的定义:
/** Node for the core to drive legacy "raw" instruction trace. */
val traceSourceNode = BundleBridgeSource(() => Vec(traceRetireWidth, new TracedInstruction()))
/** Node for external consumers to source a legacy instruction trace from the core. */
val traceNode: BundleBridgeOutwardNode[Vec[TracedInstruction]] = traceNexus := traceSourceNode
然后 Rocket Tile 实现的时候,把自己的 trace 接到 traceSourceNode 上:
到这里,整个思路已经比较清晰了,我们只需要照猫画虎地做一个就行。比如要把自己的 Custom Debug 接口暴露出去,首先也是在 Tile 里面创建一个 SourceNode:
// expose debug
val customDebugSourceNode =
BundleBridgeSource(() => new CustomDebug())
val customDebugNode: BundleBridgeOutwardNode[CustomDebug] =
customDebugSourceNode
在 BaseTileModuleImp 里,进行信号的连接:
为了暴露到顶层,我们可以类似地做。在 Subsystem 中:
// expose debug
val customDebugNexus = BundleBridgeNexusNode[CustomDebug]()
val tileCustomDebugNodes = tiles
.flatMap { case tile: MeowV64Tile =>
Some(tile)
}
.map { _.customDebugNode }
tileCustomDebugNodes.foreach { customDebugNexus := _ }
最后在 SubsystemModule Imp 中连接到 IO:
// wire custom debug signals
val customDebugIO = outer.customDebugNexus.in.map(_._1)
val customDebug = IO(
Output(
Vec(customDebugIO.length, customDebugIO(0).cloneType)
)
)
for (i <- 0 until customDebug.length) {
customDebug(i) := customDebugIO(i)
}
这样就搞定了。
找到这个实现方法,基本是对着自带的 trace 接口做的,比较重要的是理解 diplomacy 里面的两层,第一层是把不同的模块进行一些连接,然后第二层在 ModuleImp 中处理实际的信号和逻辑。
之前 @松 给我讲过一些内存认证(Memory Authentication)算法的内容,受益匪浅,刚好今天某硬件群里又讨论到了这个话题,于是趁此机会再学习和整理一下相关的知识。
内存认证计算的背景是可信计算,比如要做一些涉及重要数据的处理,从软件上,希望即使系统被攻击非法进入了,也可以保证重要信息不会泄漏;从硬件上,希望即使系统可以被攻击者进行一些物理的操作(比如导出或者修改内存等等),也可以保证攻击者无法读取或者篡改数据。
下面的内容主要参考了 Hardware Mechanisms for Memory Authentication: A Survey of Existing Techniques and Engines 这篇 2009 年的文章。
作为一个防御机制,首先要确定攻击方的能力。一个常见的威胁模型是认为,攻击者具有物理的控制,可以任意操控内存中的数据,但是无法读取或者修改 CPU 内部的数据。也就是说,只有 CPU 芯片内的数据是可信的,离开了芯片都是攻击者掌控的范围。一个简单的想法是让内存中保存的数据是加密的,那么怎样攻击者可以如何攻击加密的数据?下面是几个典型的攻击方法:
为了防御上面几种攻击方法,上面提到的文章里提到了如下的思路:
一是 Hash Function,把内存分为很多个块,每一块计算一个密码学 Hash 保存在片内,那么读取数据的时候,把整块数据读取进来,计算一次 Hash,和片内保存的结果进行比对;写入数据的时候,重新计算一次修改后数据的 Hash,更新到片内的存储。这个方法的缺点是没有加密,攻击者可以看到内容,只不过一修改就会被 CPU 发现(除非 Hash 冲突),并且存储代价很大:比如 512-bit 的块,每一块计算一个 128-bit 的 Hash,那就浪费了 25% 的空间,而片内空间是十分宝贵的。
二是 MAC Function,也就是密码学的消息验证码,它需要一个 Key,保存在片内;由于攻击者不知道密码,根据 MAC 的性质,攻击者无法篡改数据,也无法伪造 MAC,所以可以直接把计算出来的 MAC 也保存到内存里。为了防御重放攻击,需要引入随机的 nonce,并且把 nonce 保存在片内,比如每 512-bit 的数据,保存 64-bit 的 nonce,这样片内需要保存 12.5% 的空间,依然不少。MAC 本身也不加密,所以如果不希望攻击者看到明文,还需要进行加密。
三是 Block-Level AREA,也就是在把明文和随机的 nonce 拼接起来,采用块加密算法,保存在内存中;解密的时候,验证最后的 nonce 和片内保存的一致。这个方法和 MAC 比较类似,同时做了加密的事情,也需要在片内保存每块数据对应的随机 nonce。
但是上面几种方法开销都比较大,比如要保护 1GB 的内存,那么片内就要保存几百 MB 的数据,这对于片内存储来说太大了。这时候,可以采用区块链里常用的 Merkle Tree 或者类似的方法来用时间换空间。
这种方法的主要思路是,首先把内存划分为很多个块,这些块对应一颗树的叶子结点;自底向上构建一颗树,每个结点可以验证它的子结点的完整性,那么经过 log(n) 层的树,最后只会得到一个很小的根结点,只需要把根结点保存在片内。
为了验证某一个块的完整性,就从这一块对应的叶子结点开始,不断计算出一个值,和父亲结点比较;再递归向上,最后计算出根结点的值,和片内保存的值进行对比。这样验证的复杂度是 O(logn),但是片内保存的数据变成了 O(1),所以是以时间换空间。更新数据的时候,也是类似地从叶子结点一步一步计算,最后更新根结点的值。
这个方法浪费的空间,考虑所有非叶子结点保存的数据,如果是二叉树,总的大小就是数据的一半,但是好处是大部分都可以保存在内存里,所以是比较容易实现的。缺点是每次读取和写入都要进行 O(logn) 次的内存访问和计算,开销比较大。
上面提到的父结点的值的计算方法,如果采用密码学 Hash 函数,这棵树就是 Merkle Tree。它的验证过程是只读的,可以并行的,但是更新过程是串行的,因为要从子结点一步一步计算 Hash,父结点依赖子结点的 Hash 结果。
另一种设计是 Parallelizable Authentication Tree(PAT),它采用 MAC 而不是 Hash,每个结点保存了一个随机的 nonce 和计算出来的 MAC 值,最底层的 MAC 输入是实际的数据,其他层的 MAC 输入是子结点的 nonce,最后在片内保存最后一次 MAC 使用的 nonce 值。这样的好处是更新的时候,每一层都可以并行算,因为 MAC 的输入是 nonce 值,不涉及到子结点的 MAC 计算结果。缺点是要保存更多数据,即 MAC 和 nonce。
还有一种设计是 Tamper-Evident Counter Tree(TEC-Tree),计算的方法则是上面提到的 Block-level AREA。类似地,最底层是用数据和随机 nonce 拼起来做加密,而其他层是用子节点的随机 nonce 拼起来,再拼接上这一层的 nonce 做加密。验证的时候,首先对最底层进行解密,然后判断数据是否匹配,然后再解密上一层,判断 nonce 是否匹配,一直递归,最后解密到根的 nonce,和片内保存的进行匹配。更新的时候,也可以类似地一次性生产一系列的 nonce,然后并行地加密每一层的结果。
最后引用文章里的一个对比:

可以看到,后两种算法可以并行地更新树的节点,同时也需要保存更多的数据。
从上面的 Integrity Tree 算法可以发现,每次读取或者写入都要访问内存 O(logn) 次,这个对性能影响是十分巨大的。一个简单的思路是,我把一些经常访问的树结点保存在片内的缓存,这样就可以减少一些内存访问次数;进一步地,如果认为攻击者无法篡改片内的缓存,那就可以直接认为片内的结点都是可信的,在验证和更新的时候,只需要从叶子结点遍历到缓存在片内的结点即可。
为了进一步减少空间的占用,Bonsai Merkle Tree(BMT)的思路是,既然对每个内存块都生成一个比较长的(比如 64 位)的 nonce 比较耗费空间,那是否可以减少一下 nonce 的位数,当 nonce 出现重复的时候,换一个密钥重新加密呢?具体的做法是,每个内存块做一次 MAC 计算,输入是数据,地址和 counter:M=MAC(C, addr, ctr)。此时,地址和 ctr 充当了原来的 nonce 的作用,所以类似地,此时的 Merkle Tree 保护的是这些 counter,由于 counter 位数比较少,就可以进一步地减少空间的开销,而且树的层数也更少了。缺点是既然位数少了,如果 counter 出现了重复,就需要更换密钥,重新进行一次加密,这个比较耗费时间,所以还要尽量减少重新加密的次数。
具体来说,为了避免重放攻击,每次更新数据的时候,就让 counter 加一,这和原来采用一个足够长(比如 64-bit)的随机 nonce 是类似的。重新加密是很耗费时间的,因此为了把重新加密的范围局限到一个小的局部,又设计了一个两级的 counter:7-bit 的 local counter,每次更新数据加一;64-bit 的 global counter,当某一个 local counter 溢出的时候加一。这时候实际传入 MAC 计算的 counter 则是 global counter 拼接上 local counter。这样相当于是做了一个 counter 的共同前缀,在内存访问比较均匀的时候,比如每个 local counter 轮流加一,那么每次 local counter 溢出只需要重新加密一个小范围的内存,减少了开销。
文章后续还提到了一些相关的算法,这里就不继续翻译和总结了。
再来看一下 Scalable Memory Protection in the Penglai Enclave 中提到的 Mountable Merkle Tree 设计。它主要考虑的是动态可变的保护内存区域,比如提到的微服务场景,并且被保护内存区域的访问有时间局部性,因此它的思路是,不去构造一个对应完整内存的 Merkle Tree,而是允许一些子树不存在。具体来说,它设计了一个 Sub-root nodes 的概念,对应了 Merkle Tree 中间的一层。这一层往上是预先分配好的,并且大部分保存在内存中,根结点保存在片内,这一层往下是动态分配的。比如应用创建了一个新的 enclave,需要新的一个被保护的内存区域,再动态分配若干个 Merkle Tree,接到 Sub-root nodes 层,成为新的子树。
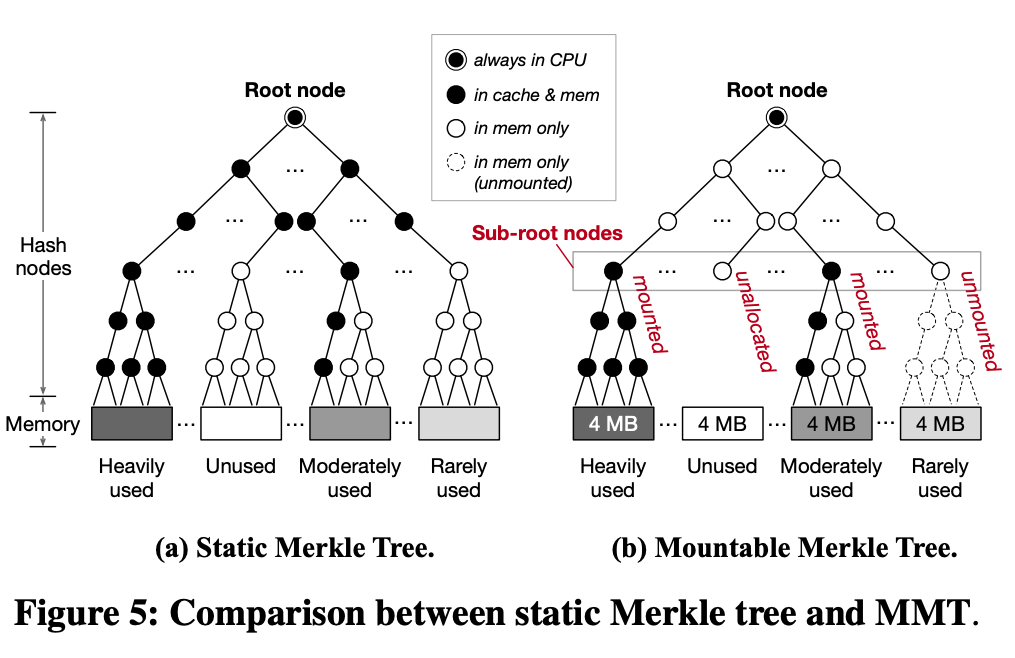
由于片内空间是有限的,所以这里采取了缓存的方式,只把一部分常用的树结点保存在片内;如果某一个子树一直没有被访问,就可以换出到内存里。如果删除了一个已有的 enclave,那么相应的子树就可以删掉,减少内存空间的占用。
本文的内容已经整合到知识库中。
最近在研究一些支持缓存一致性的缓存的实现,比如 rocket-chip 的实现和 sifive 的实现,因此需要研究一些 TileLink 协议。本文讨论的时候默认读者具有一定的 AXI 知识,因此很多内容会直接参考 AXI。
根据 TileLink Spec 1.8.0,TileLink 分为以下三种:
TileLink Uncached(TL-UL 和 TL-UH) 包括了两个 channel:
因此 TileLink 每个周期只能发送读或者写的请求,而 AXI 可以同时在 AR 和 AW channel 上发送请求。
一些请求的例子:
针对 AXI4ToTL 模块的例子,来分析一下如何把一个 AXI4 Master 转换为 TileLink。
首先考虑一下 AXI4 和 TileLink 的区别:一个是读写 channel 合并了,所以这里需要一个 Arbiter;其次 AXI4 中 AW 和 W 是分开的,这里也需要进行合并。这个模块并不考虑 Burst 的情况,而是由 AXI4Fragmenter 来进行拆分,即添加若干个 AW beat,和 W 进行配对。
具体到代码实现上,首先把 AR channel 对应到 到 A channel 上:
val r_out = Wire(out.a)
r_out.valid := in.ar.valid
r_out.bits :<= edgeOut.Get(r_id, r_addr, r_size)._2
然后 AW+W channel 也连接 到 A channel,由于不用考虑 burst 的情况,这里在 aw 和 w 同时 valid 的时候才认为有请求。
val w_out = Wire(out.a)
in.aw.ready := w_out.ready && in.w.valid && in.w.bits.last
in.w.ready := w_out.ready && in.aw.valid
w_out.valid := in.aw.valid && in.w.valid
w_out.bits :<= edgeOut.Put(w_id, w_addr, w_size, in.w.bits.data, in.w.bits.strb)._2
比较有意思的是读写的 id 增加了若干位,最低位 0 表示读,1 表示写,剩下几位是请求编号,这样发出去的是不同 id 的多个请求。
然后,把读和写的 A channel 连接到 Arbiter 上:
其余的部分则是对 D channel 进行判断,有数据的转给 R channel,没有数据的转给 B channel:
out.d.ready := Mux(d_hasData, ok_r.ready, ok_b.ready)
ok_r.valid := out.d.valid && d_hasData
ok_b.valid := out.d.valid && !d_hasData
最后处理了一下 TileLink 和 AXI4 对写请求返回确认的区别:TileLink 中,可以在第一个 burst beat 就返回确认,而 AXI4 需要在最后一个 burst beat 之后返回确认。
再来看一下反过来的转换,从 TileLink Master 到 AXI。由于 TileLink 同时只能进行读或者写,所以它首先做了一个虚构的 arw channel,可以理解为合并了 ar 和 aw channel 的 AXI4,这个设计在 SpinalHDL 的代码中也能看到。然后再根据是否是写入,分别连接到 ar 和 aw channel:
val queue_arw = Queue.irrevocable(out_arw, entries=depth, flow=combinational)
out.ar.bits := queue_arw.bits
out.aw.bits := queue_arw.bits
out.ar.valid := queue_arw.valid && !queue_arw.bits.wen
out.aw.valid := queue_arw.valid && queue_arw.bits.wen
queue_arw.ready := Mux(queue_arw.bits.wen, out.aw.ready, out.ar.ready)
这里处理了 aw 和 w 的 valid 信号:
in.a.ready := !stall && Mux(a_isPut, (doneAW || out_arw.ready) && out_w.ready, out_arw.ready)
out_arw.valid := !stall && in.a.valid && Mux(a_isPut, !doneAW && out_w.ready, Bool(true))
out_w.valid := !stall && in.a.valid && a_isPut && (doneAW || out_arw.ready)
这样做的原因是,在 TileLink 中,每个 burst 都是一个 a channel 上的请求,而 AXI4 中,只有第一个 burst 有 aw 请求,所有 burst 都有 w 请求,因此这里用 doneAW 信号来进行区分。
接着,要把 b 和 r channel 上的结果连接到 d channel,根据上面的经验,这里 又是一个 arbitration:
val r_wins = (out.r.valid && b_delay =/= UInt(7)) || r_holds_d
out.r.ready := in.d.ready && r_wins
out.b.ready := in.d.ready && !r_wins
in.d.valid := Mux(r_wins, out.r.valid, out.b.valid)
最后还处理了一下请求和结果顺序的问题。
上面说的两个模块都是 TileLink Uncached,那么它如何支持缓存一致性呢?首先,它引入了三个 channel:B、C 和 E,支持三种操作:
可以看到,A C E 三个 channel 是 M->S,B D 两个 channel 是 S->M。
假如一个缓存(Master A)要写入一块只读数据,或者读取一块 miss 的缓存行,如果是广播式的缓存一致性协议,那么需要经历如下的过程:
首先 Master A 发出 Acquire 请求,然后 Slave 向其他 Master 广播 Probe,等到其他 Master 返回 ProbeAck 后,再向 Master A 返回 Grant,最后 Master A 发送 GrantAck 给 Slave。这样 Master A 就获得了这个缓存行的一份拷贝,并且让 Master B 的缓存行失效或者状态变成只读。
TileLink 的缓存行有三个状态:None,Branch 和 Trunk(Tip)。基本对应 MSI 模型:None->Invalid,Branch->Shared 和 Trunk->Modified。Rocket Chip 代码中 ClientStates 还定义了 Dirty 状态,大致对应 MESI 模型:None->Invalid,Branch->Shared,Trunk->Exclusive,Dirty->Modified。
此外,标准还说可以在 B 和 C channel 上进行 TL-UH 的操作。标准这么设计的意图是可以让 Slave 转发操作到拥有缓存数据的 Master 上。比如 Master A 在 A channel 上发送 Put 请求,那么 Slave 向 Master B 的 B channel 上发送 Put 请求,Master B 在 C channel 上发送 AccessAck 响应,Slave 再把响应转回 Master A 的 D channel。这就像是一个片上的网络,Slave 负责在 Master 之间路由请求。
接下来看看 Rocket Chip 自带的基于广播的缓存一致性协议实现。核心实现是 TLBroadcast,核心的逻辑就是,如果一个 Master A 发送了 Acquire,那么 TLBroadcast 需要发送 Probe 到其他的 Master,当其他的 Master 都响应了 ProbeAck 后,再返回 Grant 到 Master A。
首先来看 B channel 上的 Probe 逻辑。它记录了一个 todo bitmask,表示哪些 Master 需要发送 Probe,这里采用了 Probe Filter 来减少发送 Probe 的次数,因为只需要向拥有这个缓存行的 Master 发送 Probe:
val probe_todo = RegInit(0.U(max(1, caches.size).W))
val probe_line = Reg(UInt())
val probe_perms = Reg(UInt(2.W))
val probe_next = probe_todo & ~(leftOR(probe_todo) << 1)
val probe_busy = probe_todo.orR()
val probe_target = if (caches.size == 0) 0.U else Mux1H(probe_next, cache_targets)
// Probe whatever the FSM wants to do next
in.b.valid := probe_busy
if (caches.size != 0) {
in.b.bits := edgeIn.Probe(probe_line << lineShift, probe_target, lineShift.U, probe_perms)._2
}
when (in.b.fire()) { probe_todo := probe_todo & ~probe_next }
这里 probe_next 就是被 probe 的那个 Master 对应的 bitmask,probe_target 就是 Master 的 Id。这个 Probe FSM 的输入就是 Probe Filter,它会给出哪些 Cache 拥有当前的缓存行的信息:
val leaveB = !filter.io.response.bits.needT && !filter.io.response.bits.gaveT
val others = filter.io.response.bits.cacheOH & ~filter.io.response.bits.allocOH
val todo = Mux(leaveB, 0.U, others)
filter.io.response.ready := !probe_busy
when (filter.io.response.fire()) {
probe_todo := todo
probe_line := filter.io.response.bits.address >> lineShift
probe_perms := Mux(filter.io.response.bits.needT, TLPermissions.toN, TLPermissions.toB)
}
这里又区分两种情况:如果 Acquire 需要进入 Trunk 状态(比如是个写入操作),意味着其他 Master 需要进入 None 状态,所以这里要发送 toN;如果 Acquire 不需要进入 Trunk 状态(比如是个读取操作),那么只需要其他 Master 进入 Branch 状态,所以这里要发送 toB。
在 B channel 发送 Probe 的同时,也要处理 C channel 上的 ProbeAck 和 ProbeAckData:
// Incoming C can be:
// ProbeAck => decrement tracker, drop
// ProbeAckData => decrement tracker, send out A as PutFull(DROP)
// ReleaseData => send out A as PutFull(TRANSFORM)
// Release => send out D as ReleaseAck
由于这里采用的是 invalidation based,所以如果某个 Master 之前处于 Dirty 状态,那么它会发送 ProbeAckData,此时需要把数据写回,所以需要用 PutFull 把数据写出去。
下面来讨论一下 TileLink 对各组信号的一些要求。
首先是 Flow Control Rules,讨论的是 ready 和 valid 信号的关系,目的是防止死锁。首先是两个比较常规的要求:
第一个说的就是 valid & ready 的时候才认为是一个 beat 处理了,第二个就是如果 valid=LOW,那么信号可能是随机的、不合法的。
这里是为了防止组合逻辑出现环路,如果 valid 依赖 ready,ready 依赖 valid,就会出现问题,所以这里规定,valid 不能依赖 ready,反过来只能 ready 依赖 valid。类似地,其他的数据和控制信号也不可以依赖 ready。简单理解就是 sender 要主动提供数据,而 receiver 决定了是否接受。
这两条的意思是,同一个周期内,我设置发送的请求的 valid,不能依赖于同一个周期内接受到的响应的 valid,比如 A 的 valid 不能组合依赖于 D 的 valid。另一方面,我设置的响应的 ready 不能依赖于同一个周期内的请求,比如 D 的 ready 不能组和依赖于 A 的 ready。
那么,有这么几种用法是可以的:
和 AXI 不同的一点在于,TileLink 不要求 irrevocable,也就是说如果一个周期内 valid=HIGH 但是 ready=LOW,那么下一个周期 Master 可以修改控制和数据信号,也可以让 valid=LOW。
Note that a sender may raise valid and then lower it on the following
cycle, even if the message was not accepted on the previous cycle. For example,
the sender might have some other higher priority task to perform on the
following cycle, instead of trying to send the rejected message again.
Furthermore, the sender may change the contents of the control and data signals
when a message was not accepted.
TileLink 的 burst 请求是通过比 bus 更宽的 size 的多个 beat 组成的。一旦第一个 beat fire 了,后续只能发送同一个 burst 的数据,不可以交错。
这里讨论的是请求和响应的顺序关系。TileLink 规定,响应的第一个 beat 不早于第一个请求的 beat,比如:
那么多规则,一个很重要的目的是要防止死锁。为了防止死锁,有这样三条:
大概意思是,beat 不能无限推迟,无论是发送方还是接受方。对于每个请求,它的响应不能无限推迟。
TileLink 定义了各个 channel 的优先级,从低到高是 A<B<C<D<E。对于同一个 channel,A C E 上是 master/sender 优先级更高,B D 上是 slave/receiver 优先级更高。
TileLink 的设计里保证了,每个请求的响应都比请求优先级更高。比如 A channel 的请求(Get/Put/AcquireBlock)的响应在 D channel(AccessAckData/AccessAck/Grant),B channel 的请求(Probe)的响应在 C channel(ProbeAck),C channel 的请求(Release)的响应在 D channel(ReleaseAck),D channel 的请求(Grant)的响应在 E channel(GrantAck)。
之前有一天看到朋友在捣鼓 CH32V307,因此自己也萌生了试用 CH32V307 评估板的兴趣,于是在沁恒官网申请样品,很快就接到电话了解情况,几天后就顺丰送到了,不过因为疫情原因直到现在才拿到手上,只能说疫情期间说不定货比人还快。
收到的盒子里有一个 CH32V307 评估板,和一个 WCH-Link,相关资料可以在 官网 或者 openwch/ch32v307 下载。在说明书中有如下的图示:

板子自带的跳线帽不是很多,建议自备一些,或者用杜邦线替代。比较重要的是 WCH-Link 子板上 CH549 和 CH2V307 连接的几个信号,和下面 BOOT0/1 的选择。
可以看到评估板自带了一个 WCH-Link,所以不需要附赠的那一个,直接把 11 号 Type-C 连接到电脑上即可。这里还遇到一个小插曲,用 Type-C to Type-C 的线连电脑上不工作,连 PWR LED 都点不亮,换一根 Type-A to Type-C 的就可以,没有继续研究是什么原因。电脑上可以看到 WCH-Link 的设备:VID=1a86, PID=8010。比较有意思的是,在 RISC-V 模式(CON 灯不亮)的时候 PID 是 8010,ARM 模式(CON 灯亮)的时候 PID 是 8011,从 RISC-V 模式切换到 ARM 模式的方法是连接 TX 和 GND 后上电,反过来要用 MounRiver,详见 WCH-Link 使用说明 V1.0 V1.3 和原理图 V1.1。
给沁恒开源 WCH-Link 原理图并开放固件点个赞,在淘宝上也可以看到不少 WCH-Link 的仿真器,挺有意思的。
在 ARM 模式下,它实现了类似 CMSIS-DAP 的协议,可以用 OpenOCD 调试:
source [find interface/cmsis-dap.cfg]
adapter speed 1000
cmsis_dap_vid_pid 0x1a86 0x8011
transport select swd
init
$ openocd -f openocd.cfg
Open On-Chip Debugger 0.11.0
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
Info : CMSIS-DAP: SWD Supported
Info : CMSIS-DAP: FW Version = 2.0.0
Info : CMSIS-DAP: Interface Initialised (SWD)
Info : SWCLK/TCK = 1 SWDIO/TMS = 1 TDI = 0 TDO = 0 nTRST = 0 nRESET = 1
Info : CMSIS-DAP: Interface ready
Info : clock speed 1000 kHz
Warn : gdb services need one or more targets defined
Info : Listening on port 6666 for tcl connections
Info : Listening on port 4444 for telnet connections
不过这里我们要用的是 RISC-V 处理器 CH32V307,上面的就当是 WCH-LINK 使用的小贴士。
给评估板插上 USB Type-C 以后,首先上面的 WCH-Link 部分中红色的 PWR 和绿色的 RUN 亮,CON 不亮,说明 WCH-LINK 的 CH549 已经启动,并且处在 RISC-V 模式(CON 不亮)。CH549 是一个 8051 指令集的处理器,上面的跑的 WCH-LINK 固件在网上可以找到,在下面提到的 MounRiver Studio 目录中也有一份。
目前开源工具上游还不支持 CH32V307 的开发,需要用 MounRiver,支持 Windows 和 Linux,有两部分:
解压缩后,可以看到它的 OpenOCD 配置:
## wch-arm.cfg
adapter driver cmsis-dap
transport select swd
source [find ../share/openocd/scripts/target/ch32f1x.cfg]
## wch-riscv.cfg
#interface wlink
adapter driver wlink
wlink_set
set _CHIPNAME riscv
jtag newtap $_CHIPNAME cpu -irlen 5 -expected-id 0x00001
set _TARGETNAME $_CHIPNAME.cpu
target create $_TARGETNAME.0 riscv -chain-position $_TARGETNAME
$_TARGETNAME.0 configure -work-area-phys 0x80000000 -work-area-size 10000 -work-area-backup 1
set _FLASHNAME $_CHIPNAME.flash
flash bank $_FLASHNAME wch_riscv 0x00000000 0 0 0 $_TARGETNAME.0
echo "Ready for Remote Connections"
其中 ch32f1x.cfg 就是 stm32f1x.cfg 改了一下名字,可以看到 WCH OpenOCD 把它的 RISC-V 调试协议称为 wlink,估计是取 wch-link 的简称吧。除了 wlink 部分,其他就是正常的 RISC-V CPU 调试的 OpenOCD 配置,比较有意思的就是 IDCODE 设为了 0x00001,比较有个性。
在网上一番搜索,找到了 WCH OpenOCD 的源码 Embedded_Projects/riscv-openocd-wch,是网友向沁恒获取的源代码,毕竟 OpenOCD 是 GPL 软件。简单看了一下代码,是直接把 RISC-V Debug 中的 DMI 操作封装了一下,然后通过 USB Bulk 和 WCH-Link 通信。我从 riscv-openocd 找到了一个比较接近的 commit,然后把 WCH 的代码提交上去,得到了 diff,有兴趣的可以看看具体实现,甚至把这个支持提交到上游。
有源码以后,就可以在 macOS 上编译了(需要修复三处 clang 报告的编译错误,最终代码):
$ ./bootstrap
$ ./configure --prefix=/path/to/prefix/openocd --enable-wlink --disable-werror CAPSTONE_CFLAGS=-I/opt/homebrew/opt/capstone/include/
$ make -j4 install
如果遇到 makeinfo 报错,把 homebrew 的 texinfo 加到 PATH 即可。
编译完成后,就可以用前面提到的 wch-riscv.cfg 进行调试了:
$ /path/to/prefix/openocd -f wch-riscv.cfg
Open On-Chip Debugger 0.11.0+dev-01623-gbfa3bc7f9 (2022-04-20-09:55)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
Info : only one transport option; autoselect 'jtag'
Ready for Remote Connections
Info : Listening on port 6666 for tcl connections
Info : Listening on port 4444 for telnet connections
Info : WCH-Link version 2.3
Info : wlink_init ok
Info : This adapter doesn't support configurable speed
Info : JTAG tap: riscv.cpu tap/device found: 0x00000001 (mfg: 0x000 (<invalid>), part: 0x0000, ver: 0x0)
Warn : Bypassing JTAG setup events due to errors
Info : [riscv.cpu.0] datacount=2 progbufsize=8
Info : Examined RISC-V core; found 1 harts
Info : hart 0: XLEN=32, misa=0x40901125
[riscv.cpu.0] Target successfully examined.
Info : starting gdb server for riscv.cpu.0 on 3333
Info : Listening on port 3333 for gdb connections
这也验证了上面的发现:因为绕过了 jtag,直接发送 dmi,所以 idcode 是假的:
if(wchwlink){
buf_set_u32(idcode_buffer, 0, 32, 0x00001); //Default value,for reuse risc-v jtag debug
}
接下来就可以用 GDB 调试了。里面跑了一个样例的程序,就是向串口打印:
之后则是针对各个外设,基于沁恒提供的示例代码进行相应的开发了。
接下来看看沁恒提供的代码是如何配置的。在 EVT/EXAM/SRC/Startup/startup_ch32v30x_D8C.S 可以看到初始化的汇编代码。比较有意思的是,这个核心扩展了 mtvec,支持 ARM 的 vector table 模式,即放一个指针数组,而不是指令:
.section .vector,"ax",@progbits
.align 1
_vector_base:
.option norvc;
.word _start
.word 0
.word NMI_Handler /* NMI */
.word HardFault_Handler /* Hard Fault */
这些名字如此熟悉,只能说这是 ARVM 了(ARM + RV)。后面的部分比较常规,把 data 段复制到 sram,然后清空 bss:
handle_reset:
.option push
.option norelax
la gp, __global_pointer$
.option pop
1:
la sp, _eusrstack
2:
/* Load data section from flash to RAM */
la a0, _data_lma
la a1, _data_vma
la a2, _edata
bgeu a1, a2, 2f
1:
lw t0, (a0)
sw t0, (a1)
addi a0, a0, 4
addi a1, a1, 4
bltu a1, a2, 1b
2:
/* Clear bss section */
la a0, _sbss
la a1, _ebss
bgeu a0, a1, 2f
1:
sw zero, (a0)
addi a0, a0, 4
bltu a0, a1, 1b
2:
最后是进行一些 csr 的配置,然后进入 C 代码:
li t0, 0x1f
csrw 0xbc0, t0
/* Enable nested and hardware stack */
li t0, 0x1f
csrw 0x804, t0
/* Enable floating point and interrupt */
li t0, 0x6088
csrs mstatus, t0
la t0, _vector_base
ori t0, t0, 3
csrw mtvec, t0
lui a0, 0x1ffff
li a1, 0x300
sh a1, 0x1b0(a0)
1: lui s2, 0x40022
lw a0, 0xc(s2)
andi a0, a0, 1
bnez a0, 1b
jal SystemInit
la t0, main
csrw mepc, t0
mret
这里有一些自定义的 csr,比如 corecfgr(0xbc0),intsyscr(0x804,设置了 HWSTKEN=1, INESTEN=1, PMTCFG=0b11, HWSTKOVEN=1),具体参考 QingKeV4_Processor_Manual。接着代码往 0x1ffff1b0 写入 0x300,然后不断读取 FLASH Interface (0x40022000) 的 STATR 字段,没有找到代码中相关的定义,简单猜测与 Flash 的零等待/非零等待区有关,因为后续代码要提高频率,因此 Flash 控制器需要增加 wait state。
可以用 MounRiver 编译,也可以用 SiFive 的 riscv64-unknown-elf 工具链进行编译,参考 Embedded_Projects/CH32V307_Template 项目中的编译方式,修改 riscv64-elf.cmake 为:
set(CMAKE_SYSTEM_NAME Generic)
set(CMAKE_C_COMPILER riscv64-unknown-elf-gcc)
set(CMAKE_CXX_COMPILER riscv64-unknown-elf-g++)
# Make CMake happy about those compilers
set(CMAKE_TRY_COMPILE_TARGET_TYPE "STATIC_LIBRARY")
然后交叉编译就可以了。需要注意的是对 libnosys 的处理,如果没有正确链接,就会出现 syscall,然后在 ecall handler 里面死循环。
如果不想用 CMake,也可以用下面的精简版 Makefile:
USER := User/main.c User/ch32v30x_it.c User/system_ch32v30x.c
LIBRARY := ../../SRC/Peripheral/src/ch32v30x_misc.c \
../../SRC/Peripheral/src/ch32v30x_usart.c \
../../SRC/Peripheral/src/ch32v30x_gpio.c \
../../SRC/Peripheral/src/ch32v30x_rcc.c \
../../SRC/Debug/debug.c \
../../SRC/Startup/startup_ch32v30x_D8C.S
LDSCRIPT = ../../SRC/Ld/Link.ld
# disable libc first
CFLAGS := -march=rv32imafc -mabi=ilp32f \
-flto -ffunction-sections -fdata-sections \
-nostartfiles -nostdlib \
-T $(LDSCRIPT) \
-I../../SRC/Debug \
-I../../SRC/Core \
-I../../SRC/Peripheral/inc \
-I./User \
-O2 \
-Wl,--print-memory-usage
# link libc & libnosys in the end
CFLAGS_END := \
-lc -lgcc -lnosys
PREFIX := riscv64-unknown-elf-
all: obj/build.bin
obj/build.bin: obj/build.elf
$(PREFIX)objcopy -O binary $^ $@
obj/build.elf: $(USER) $(LIBRARY)
$(PREFIX)gcc $(CFLAGS) $^ $(CFLAGS_END) -o $@
clean:
rm -rf obj/*
编译好以后,根据 WCH OpenOCD 的文档,可以用下面的配置来进行烧写:
#interface wlink
adapter driver wlink
wlink_set
set _CHIPNAME riscv
jtag newtap $_CHIPNAME cpu -irlen 5 -expected-id 0x00001
set _TARGETNAME $_CHIPNAME.cpu
target create $_TARGETNAME.0 riscv -chain-position $_TARGETNAME
$_TARGETNAME.0 configure -work-area-phys 0x80000000 -work-area-size 10000 -work-area-backup 1
set _FLASHNAME $_CHIPNAME.flash
flash bank $_FLASHNAME wch_riscv 0x00000000 0 0 0 $_TARGETNAME.0
init
halt
flash erase_sector wch_riscv 0 last
program /path/to/firmware
verify_image /path/to/firmware
wlink_reset_resume
exit
输出:
$ openocd -f program.cfg
Open On-Chip Debugger 0.11.0+dev-01623-gbfa3bc7f9 (2022-04-20-09:55)
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
Info : only one transport option; autoselect 'jtag'
Ready for Remote Connections
Info : WCH-Link version 2.3
Info : wlink_init ok
Info : This adapter doesn't support configurable speed
Info : JTAG tap: riscv.cpu tap/device found: 0x00000001 (mfg: 0x000 (<invalid>), part: 0x0000, ver: 0x0)
Warn : Bypassing JTAG setup events due to errors
Info : [riscv.cpu.0] datacount=2 progbufsize=8
Info : Examined RISC-V core; found 1 harts
Info : hart 0: XLEN=32, misa=0x40901125
[riscv.cpu.0] Target successfully examined.
Info : starting gdb server for riscv.cpu.0 on 3333
Info : Listening on port 3333 for gdb connections
Info : device id = REDACTED
Info : flash size = 256kbytes
Info : JTAG tap: riscv.cpu tap/device found: 0x00000001 (mfg: 0x000 (<invalid>), part: 0x0000, ver: 0x0)
Warn : Bypassing JTAG setup events due to errors
** Programming Started **
** Programming Finished **
Info : Verify Success
访问串口 screen /dev/tty.usbmodem* 115200,可以看到正确地输出了内容。
本文已授权转发到以下的地址:
最近在研究如何实现一个远程 JTAG 的功能,目前实现在 jiegec/jtag-remote-server,实现了简单的 XVC 协议,底层用的是 libftdi 的 MPSSE 协议来操作 JTAG。但是,在用 Vivado 尝试的时候,SysMon 可以正常使用,但是下载 Bitstream 会失败,所以要研究一下 Vivado 都做了什么(目前已经修好,是最后一个字节的部分位读取的处理问题)。
SVF 格式其实是一系列的 JTAG 上的操作。想到这个,也是因为在网上搜到了一个 dcfeb_v45.svf,里面描述的就是一段 JTAG 操作:
// Created using Xilinx Cse Software [ISE - 12.4]
// Date: Mon May 09 11:00:32 2011
TRST OFF;
ENDIR IDLE;
ENDDR IDLE;
STATE RESET;
STATE IDLE;
FREQUENCY 1E6 HZ;
//Operation: Program -p 0 -dataWidth 16 -rs1 NONE -rs0 NONE -bpionly -e -loadfpga
TIR 0 ;
HIR 0 ;
TDR 0 ;
HDR 0 ;
TIR 0 ;
HIR 0 ;
HDR 0 ;
TDR 0 ;
//Loading device with 'idcode' instruction.
SIR 10 TDI (03c9) SMASK (03ff) ;
SDR 32 TDI (00000000) SMASK (ffffffff) TDO (f424a093) MASK (0fffffff) ;
//Boundary Scan Chain Contents
//Position 1: xc6vlx130t
TIR 0 ;
HIR 0 ;
TDR 0 ;
HDR 0 ;
TIR 0 ;
HIR 0 ;
TDR 0 ;
HDR 0 ;
TIR 0 ;
HIR 0 ;
HDR 0 ;
TDR 0 ;
//Loading device with 'idcode' instruction.
SIR 10 TDI (03c9) ;
SDR 32 TDI (00000000) TDO (f424a093) ;
//Loading device with 'bypass' instruction.
SIR 10 TDI (03ff) ;
//Loading device with 'idcode' instruction.
SIR 10 TDI (03c9) ;
SDR 32 TDI (00000000) TDO (f424a093) ;
// Loading device with a `jprogram` instruction.
SIR 10 TDI (03cb) ;
// Loading device with a `isc_noop` instruction.
SIR 10 TDI (03d4) ;
RUNTEST 100000 TCK;
// Check init_complete in ircapture.
//IR Capture using specified instruction.
SIR 10 TDI (03d4) TDO (0010) MASK (0010) ;
// Loading device with a `isc_enable` instruction.
SIR 10 TDI (03d0) ;
SDR 5 TDI (00) SMASK (1f) ;
RUNTEST 100 TCK;
// Loading device with a `isc_program` instruction.
SIR 10 TDI (03d1) ;
SDR 32 TDI (ffffffff) SMASK (ffffffff) ;
SDR 32 TDI (ffffffff) ;
SDR 32 TDI (ffffffff) ;
它的语法比较简单,大概就是 SIR 就是向 IR 输入,SDR 就是向 DR 输入,后面跟着的 TDO 和 MASK 表示对输出数据进行判断。比较核心的是下面这几步:
SIR JPROGRAM
SIR ISC_NOOP
RUNTEST 10000 TCK
SIR ISC_NOOP UNTIL ISC_DONE
SIR ISC_ENABLE
SIR ISC_PROGRAM
之后就是 bitstream 的内容了。
有了 SVF 以后,就可以用其他的一些支持 SVF 语法的工具来烧写 FPGA,而不需要 Vivado。比如采用如下的 OpenOCD 配置:
# openocd config
# use ftdi channel 0
adapter speed 100000
adapter driver ftdi
transport select jtag
ftdi_vid_pid 0x0403 0x6011
ftdi_layout_init 0x0008 0x000b
ftdi_tdo_sample_edge falling
ftdi_channel 0
reset_config none
jtag newtap xcvu37p tap -irlen 18 -expected-id 0x14b79093
init
svf -tap xcvu37p.tap /path/to/program.svf progress
exit
从文件头可以推测,这个功能是 Xilinx 官方提供的,一番搜索,果然找到了命令:Creating SVF files using Xilinx Vivado
添加一个 -svf_file 参数后,就会生成一个 svf 文件。下面摘录一段:
// config/idcode
SIR 18 TDI (009249) ;
SDR 32 TDI (00000000) TDO (04b79093) MASK (0fffffff) ;
// config/jprog
STATE RESET;
STATE IDLE;
SIR 18 TDI (00b2cb) ;
SIR 18 TDI (014514) ;
// Modify the below delay for config_init operation (0.100000 sec typical, 0.100000 sec maximum)
RUNTEST 0.100000 SEC;
// config/jprog/poll
RUNTEST 15000 TCK;
SIR 18 TDI (014514) TDO (011000) MASK (031000) ;
// config/slr
SIR 18 TDI (005924) ;
SDR 226633216 TDI (0000000400000004e00000008001000c00000004d00000008001000c0000000466aa99550000000400000004000000040000000400000004000000040000
结合 Xilinx 官网可以下载的 BSDL 文件,可以找到每个 IR 对应的是什么:
// config/idcode
SIR 18 TDI (009249) ;
SDR 32 TDI (00000000) TDO (04b79093) MASK (0fffffff) ;
// BSDL:
"IDCODE (001001001001001001)," & -- DEVICE_ID reg
attribute IDCODE_REGISTER of XCVU37P_FSVH2892 : entity is
"XXXX" & -- version
"0100101" & -- family
"101111001" & -- array size
"00001001001" & -- manufacturer
"1"; -- required by 1149.1
这一段是检查 IDCODE 是否是目标 FPGA 型号。
// config/jprog
STATE RESET;
STATE IDLE;
SIR 18 TDI (00b2cb) ;
SIR 18 TDI (014514) ;
// BSDL
"JPROGRAM (001011001011001011)," & -- PRIVATE
"ISC_NOOP (010100010100010100)," & -- PRIVATE, ISC_DEFAULT
// Modify the below delay for config_init operation (0.100000 sec typical, 0.100000 sec maximum)
RUNTEST 0.100000 SEC;
这一段发送了 JPROGRAM 和 ISC_NOOP 的 IR,然后进入 RUNTEST 状态一段时间。
// config/jprog/poll
RUNTEST 15000 TCK;
SIR 18 TDI (014514) TDO (011000) MASK (031000) ;
// BSDL
"ISC_NOOP (010100010100010100)," & -- PRIVATE, ISC_DEFAULT
// config/slr
SIR 18 TDI (005924) ;
SDR 226633216 TDI (0000000400000004e00000008001000c00000004d00000008001000c0000000466aa99550000000400000004000000040000000400000004000000040000
// BSDL
"CFG_IN_SLR0 (000101100100100100)," & -- PRIVATE
从这里就是开始往里面写入 bitstream,可以看到熟悉的 66aa9955 的同步字符,对比 Bitstream 文件内容:
000000c0: ffff ffff ffff ffff aa99 5566 2000 0000 ..........Uf ...
000000d0: 2000 0000 3002 2001 0000 0000 3002 0001 ...0. .....0...
000000e0: 0000 0000 3000 8001 0000 0000 2000 0000 ....0....... ...
000000f0: 3000 8001 0000 0007 2000 0000 2000 0000 0....... ... ...
00000100: 3000 2001 0000 0000 3002 6001 0000 0000 0. .....0.`.....
可以发现是每 32 字节按位颠倒:aa995566(10101010 10011001 01010101 01100110) -> 66aa9955(01100110 10101010 10011001 01010101),后面的 20000000 -> 00000004 也是类似的。
Xilinx UG570 的 Table 6-5 也印证了上面的过程:
完成 CFG_IN 之后,再进行 JSTART:
// config/start
STATE IDLE;
RUNTEST 100000 TCK;
SIR 18 TDI (00c30c) ;
HIR 0 ;
TIR 0 ;
HDR 0 ;
TDR 0 ;
STATE IDLE;
RUNTEST 2000 TCK;
SIR 18 TDI (009249) TDO (031000) MASK (011000) ;
HIR 0 ;
TIR 0 ;
HDR 0 ;
TDR 0 ;
// BSDL
"JSTART (001100001100001100)," & -- PRIVATE
"IDCODE (001001001001001001)," & -- DEVICE_ID reg
然后再次进行 CFG_IN_SLR0, CFG_OUT_SLR0,验证是否真的写进去了:
// config/status
STATE RESET;
RUNTEST 5 TCK;
SIR 18 TDI (005924) ;
SDR 160 TDI (0000000400000004800700140000000466aa9955) ;
SIR 18 TDI (004924) ;
SDR 32 TDI (00000000) TDO (3f5e0d40) MASK (08000000) ;
STATE RESET;
RUNTEST 5 TCK;
// BSDL
"CFG_IN_SLR0 (000101100100100100)," & -- PRIVATE
"CFG_OUT_SLR0 (000100100100100100)," & -- PRIVATE
// config/status
STATE RESET;
RUNTEST 5 TCK;
SIR 18 TDI (005924) ;
SDR 160 TDI (0000000400000004800700140000000466aa9955) ;
SIR 18 TDI (004924) ;
SDR 32 TDI (00000000) TDO (3f5e0d40) MASK (08000000) ;
STATE RESET;
RUNTEST 5 TCK;
这段操作是进行 Status Register Readback,见 UG570 的 Table 10-4。MASK 设为 08000000 应该是判断它的第 4 位:END_OF_STARTUP_STATUS(Table 9-25)。
如果是 Quartus 用户,也可以 生成 SVF,具体操作是:在 Programmer 中,点击 File->Create JAM, JBC, SVF or ISC file,然后在弹出的窗口中选择 svf 格式,导出即可。得到的 svf 文件一样可以用 openocd 来下载。
也可以用 quartus_cpf 在命令行中进行转换:
本文的内容已经整合到知识库中。
之前写过一个浅谈乱序执行 CPU,随着学习的深入,内容越来越多,页面太长,因此把后面的一部分内容独立出来,变成了这篇博客文章。
本文主要讨论访存的部分。
本系列的所有文章:
FPnew 是一个比较好用的浮点计算单元,但它是 SystemVerilog 编写的,并且用了很多高级特性,虽然闭源软件是支持的,但是开源拖拉机经常会遇到这样那样的问题。所以一直想用 sv2v 把它翻译成 Verilog,但此时的 Verilog 还有很多复杂的结构,再用 yosys 转换为一个通用可综合的网表。
经过一系列踩坑,一个很重要的点是要用最新的 sv2v(v0.0.9-24-gf868f06) 和 yosys(0.15+70)。Debian 打包的 yosys 版本比较老,不能满足需求。
首先,用 verilator 进行预处理,把一堆 sv 文件合成一个:
注意这里用 sed 去掉了无用的行号信息。然后,用 sv2v 进行转换:
这里又用 sed 把不支持的 $fatal 去掉。最后,用 yosys 进行处理:
$ yosys -p 'read_verilog -defer merge.v' -p 'hierarchy -p fpnew_top' -p 'proc' -p 'opt' -p 'write_verilog -noattr output.v'
注意这里要用 read_verilog -defer,否则 yosys 会遇到 TAG_WIDTH=0 默认参数就直接例化,然后就出现 [0:-1] 这样的下标。read_verilog 的文档告诉了我们可以分两步做:
-defer
only read the abstract syntax tree and defer actual compilation
to a later 'hierarchy' command. Useful in cases where the default
parameters of modules yield invalid or not synthesizable code.
这样就得到了简化后的 verilog 代码:
module \$paramod$011e4d7ee08c34f246a38322dc9967d23ecc8081\fpnew_opgroup_block_A94B6_B7406 (clk_i, rst_ni, operands_i, is_boxed_i, rnd_mode_i, op_i, op_mod_i, src_fmt_i, dst_fmt_i, int_fmt_i, vectorial_op_i, tag_i, in_valid_i, in_ready_o, flush_i, result_o, status_o, extension_bit_o, tag_o, out_valid_o, out_ready_i
, busy_o);
wire _0_;
wire _1_;
wire [71:0] arbiter_output;
output busy_o;
wire busy_o;
input clk_i;
wire clk_i;
input [2:0] dst_fmt_i;
wire [2:0] dst_fmt_i;
output extension_bit_o;
wire extension_bit_o;
input flush_i;
// ...
endmodule
这样虽然比较丑陋,但是解决了 SystemVerilog 的问题。诚然,这样也失去了修改参数的能力,因为参数已经在 yosys 综合途中确定下来了。
综合很重要的一步是把 HDL 的逻辑变成一个个单元,这些单元加上连接方式就成为了网表。那么,基本单元有哪些,怎么决定用哪些基本单元?
这个就需要工艺库了,工艺库定义了一个个单元,单元的引脚、功能,还有各种参数,这样 Design Compiler 就可以按照这些信息去找到一个优化的网表。
网上可以找到一些 Liberty 格式的工艺库,比如 Nangate45,它的设定是 25 摄氏度,1.10 伏,属于 TT(Typical/Typical)的 Process Corner。
在里面可以看到一些基本单元的定理,比如 AND2_X1,就是一个 drive strength 是 1 的二输入与门:
cell (AND2_X1) {
drive_strength : 1;
pin (A1) {
direction : input;
}
pin (A2) {
direction : input;
}
pin (ZN) {
direction : output;
function : "(A1 & A2)";
}
/* ... */
}
这样就定义了两个输入 pin,一个输出 pin,还有它实现的功能。还有很重要的一点是保存了时序信息,比如:
lu_table_template (Timing_7_7) {
variable_1 : input_net_transition;
variable_2 : total_output_net_capacitance;
index_1 ("0.0010,0.0020,0.0030,0.0040,0.0050,0.0060,0.0070");
index_2 ("0.0010,0.0020,0.0030,0.0040,0.0050,0.0060,0.0070");
}
cell (AND2_X1) {
pin (ZN) {
timing () {
related_pin : "A1";
timing_sense : positive_unate;
cell_fall(Timing_7_7) {
index_1 ("0.00117378,0.00472397,0.0171859,0.0409838,0.0780596,0.130081,0.198535");
index_2 ("0.365616,1.893040,3.786090,7.572170,15.144300,30.288700,60.577400");
values ("0.0217822,0.0253224,0.0288237,0.0346827,0.0448323,0.0636086,0.100366", \
"0.0233179,0.0268545,0.0303556,0.0362159,0.0463659,0.0651426,0.101902", \
"0.0296429,0.0331470,0.0366371,0.0425000,0.0526603,0.0714467,0.108208", \
"0.0402311,0.0440292,0.0477457,0.0538394,0.0641187,0.0829203,0.119654", \
"0.0511250,0.0554077,0.0595859,0.0662932,0.0771901,0.0963434,0.133061", \
"0.0625876,0.0673198,0.0719785,0.0794046,0.0910973,0.110757,0.147656", \
"0.0748282,0.0800098,0.0851434,0.0933663,0.106111,0.126669,0.163872");
}
}
}
首先要看 cell_fall 后面的 template 是 Timing_7_7,可以看到 variable_1 和 variable_2 对应的是 input_net_transition 和 total_output_net_capacitance。这里 cell_fall 指的是输出 pin ZN 从 1 变成 0 的时候,这个变化从 A1 的变化传播到 ZN 的时间,这个时间和输入的 transition 时间(大概是从 0 到 1、从 1 到 0 的时间,具体从多少百分比到多少百分比见设置)和输出的 capacitance 有关,所以是一个查找表,查找的时候找最近的点进行插值。输出的 capacitance 取决于 wire load 和连接了这个输出的其他单元的输入。
除了 cell_fall/cell_rise 两种类型,还有 fall_transition 和 rise_transition,这就是输出引脚的变化时间,又作为后继单元的输入 transition 时间。
接下来,还能看到功耗的数据:
power_lut_template (Power_7_7) {
variable_1 : input_transition_time;
variable_2 : total_output_net_capacitance;
index_1 ("0.0010,0.0020,0.0030,0.0040,0.0050,0.0060,0.0070");
index_2 ("0.0010,0.0020,0.0030,0.0040,0.0050,0.0060,0.0070");
}
internal_power () {
related_pin : "A1";
fall_power(Power_7_7) {
index_1 ("0.00117378,0.00472397,0.0171859,0.0409838,0.0780596,0.130081,0.198535");
index_2 ("0.365616,1.893040,3.786090,7.572170,15.144300,30.288700,60.577400");
values ("2.707163,2.939134,3.111270,3.271119,3.366153,3.407657,3.420511", \
"2.676697,2.905713,3.073189,3.236823,3.334156,3.373344,3.387400", \
"2.680855,2.891263,3.047784,3.212948,3.315296,3.360694,3.377614", \
"2.821141,3.032707,3.182020,3.338567,3.444608,3.488752,3.508229", \
"3.129641,3.235525,3.357993,3.567372,3.743682,3.792092,3.808289", \
"3.724304,3.738737,3.808381,3.980825,4.147999,4.278043,4.311323", \
"4.526175,4.492292,4.510220,4.634217,4.814899,4.934862,5.047389");
}
rise_power(Power_7_7) {
index_1 ("0.00117378,0.00472397,0.0171859,0.0409838,0.0780596,0.130081,0.198535");
index_2 ("0.365616,1.893040,3.786090,7.572170,15.144300,30.288700,60.577400");
values ("1.823439,1.926997,1.963153,2.028865,1.957837,2.123314,2.075262", \
"1.796317,1.896145,1.960625,2.014112,2.050786,2.046472,1.972327", \
"1.811604,1.886741,1.955658,1.978263,1.965671,1.963736,2.071227", \
"1.997387,2.045930,2.092357,2.063643,2.099127,1.932089,2.131341", \
"2.367285,2.439718,2.440043,2.403446,2.305848,2.351146,2.195145", \
"2.916140,2.994325,3.044451,2.962881,2.836259,2.781564,2.633645", \
"3.687718,3.756085,3.789394,3.792984,3.773583,3.593022,3.405552");
}
}
可以看到,这也是一个查找表,也是按照输出的 rise/fall 有不同的功耗。巧合的是,功耗的查找表的 index_1/index_2 和上面的时序查找表是一样的。除了 internal power,还有 leakage power,定义如下:
leakage_power_unit : "1nW";
/* ... */
cell_leakage_power : 50.353160;
leakage_power () {
when : "!A1 & !A2";
value : 40.690980;
}
leakage_power () {
when : "!A1 & A2";
value : 62.007550;
}
leakage_power () {
when : "A1 & !A2";
value : 41.294331;
}
leakage_power () {
when : "A1 & A2";
value : 57.419780;
}
可以看到,它的 leakage power 取决于输入的状态,单位是 1nW。
再来看 Flip Flop 的定义:
cell (DFFRS_X1) {
ff ("IQ" , "IQN") {
next_state : "D";
clocked_on : "CK";
preset : "!SN";
clear : "!RN";
clear_preset_var1 : L;
clear_preset_var2 : L;
}
pin (D) {
direction : input;
capacitance : 1.148034;
fall_capacitance : 1.081549;
rise_capacitance : 1.148034;
timing () {
related_pin : "CK";
timing_type : hold_rising;
when : "RN & SN";
sdf_cond : "RN_AND_SN === 1'b1";
fall_constraint(Hold_3_3) {
index_1 ("0.00117378,0.0449324,0.198535");
index_2 ("0.00117378,0.0449324,0.198535");
values ("0.002921,0.012421,0.011913", \
"0.002707,0.008886,0.005388", \
"0.139993,0.148595,0.137370");
}
rise_constraint(Hold_3_3) {
index_1 ("0.00117378,0.0449324,0.198535");
index_2 ("0.00117378,0.0449324,0.198535");
values ("0.004193,0.015978,0.019836", \
"0.020266,0.031864,0.035343", \
"0.099118,0.113075,0.120979");
}
}
}
}
可以看到,这里的属性变成了 setup/hold 时间。
SRAM 也有类似的定义,通常是写在单独的 lib 文件中,根据 width 和 depth 生成,比如 fakeram45_32x64.lib:
cell(fakeram45_32x64) {
area : 1754.536;
interface_timing : true;
memory() {
type : ram;
address_width : 5;
word_width : 64;
}
pin(clk) {
direction : input;
min_period : 0.174 ;
internal_power(){
rise_power(scalar) {
values ("1498.650")
}
fall_power(scalar) {
values ("1498.650")
}
}
}
bus(wd_in) {
bus_type : fakeram45_32x64_DATA;
direction : input;
timing() {
related_pin : clk;
timing_type : setup_rising ;
rise_constraint(scalar) {
values ("0.050");
}
fall_constraint(scalar) {
values ("0.050");
}
}
internal_power(){
when : "(we_in)";
rise_power(scalar) {
values ("14.987");
}
fall_power(scalar) {
values ("14.987");
}
}
}
}
也可以类似地看到,它的输入 setup/hold,功耗,面积等等信息。
在给 Design Compiler 配置工艺库前,需要用 Library Compiler 先把 lib 格式转换为更紧凑的二进制 db 格式:
实测部分 Liberty 文件会报错,不知道有没有修复的办法。另外,不同版本的 Library Compiler 生成的格式也不大一样,但都是兼容的。
在 Design Compiler 中,设置当前工艺库命令:
set_app_var target_library xxx.db
set_link_var target_library xxx.db
# or
set_app_var target_library {xxx.db yyy.db}
set_link_var target_library {xxx.db yyy.db}
准备好工艺库以后,就可以开始编写综合脚本了,通常有这么些步骤:
# step 1: read source code & set top level module name
read_file -format verilog xxx.v
read_file -format vhdl yyy.vhdl
current_design xxx
# step 2: setup timing constraints
create_clock clock -period 1.0000 # 1GHz for example
# other timing constraints:
# e.g. set_input_delay/set_output_delay
# step 3: synthesis
link
uniquify
# use this if you want to ungroup all hierarchy
# ungroup -flatten -all
# use this to retime design
# set_optimize_registers
compile_ultra
# step 4: check & report
check_timing
check_design
report_design
report_area -hierarchy
report_power -hierarchy
report_cell
report_timing -delay_type max
report_timing -delay_type min
report_constraint -all_violators
report_qor
# step 5: export
write -format ddc -hierarchy -output xxx.ddc
write_sdc -version 1.0 xxx.sdf
write -format verilog -hierarchy -output xxx.syn.v
write_sdc xxx.sdc
根据需求,进行自定义的修改。综合完成后,可以看到生成的 xxx.syn.v 文件里都是一个个的 cell,比如:
AND2X2 U3912 ( .A(n4416), .B(n2168), .Y(n3469) );
OAI21X1 U3913 ( .A(n2872), .B(n4589), .C(n2461), .Y(n3471) );
DFFPOSX1 clock_r_REG147_S1 ( .D(n7634), .CLK(clock), .Q(n7773) );
还有一些比较特殊的 cell,比如 TIEHI/TIELO 就是恒定输出 1/0,用于门控时钟的 CLKGATE/ICG 等,还有一些综合阶段不会出现的 cell,在后续阶段会使用。
最近在尝试接触一些芯片前后端的知识。正好有现成的开源工具链 OpenROAD 来做这个事情,借此机会来学习一下整个流程。
首先 clone 仓库 OpenROAD-flow-scripts,然后运行:./build_openroad.sh,脚本会克隆一些仓库,自动进行编译。
编译中会找不到一些库,比如可能需要安装这些依赖:liblemon-dev libeigen3-dev libreadline-dev swig,此外运行的时候还需要 klayout 依赖。
如果遇到解决 cmake 找不到 LEMON 的问题,这是一个 BUG,可以运行下面的命令解决:
编译后整个目录大概有 4.8G,输出的二进制目录是 133M。
如果要跑一下样例里的 nangate45 工艺的 gcd 例子,运行:
这个测例的代码提供了这样一个接口:
module gcd
(
input wire clk,
input wire [ 31:0] req_msg,
output wire req_rdy,
input wire req_val,
input wire reset,
output wire [ 15:0] resp_msg,
input wire resp_rdy,
output wire resp_val
);
endmodule
从名字可以推断出,外部通过 req 发送请求到 GCD 模块,然后模块计算出 GCD 后再返回结果。
根据日志可以看到,从 verilog 到最终的 gds 文件,经过了这些步骤:
NAND2_X1 DFF_X1 等这样由工艺库定义的一些单元。这些步骤可以在仓库的 flow/Makefile 里面看得比较清晰,英文版摘抄如下:
最后生成的 gds,用 KLayout 打开,可以看到这个样子:
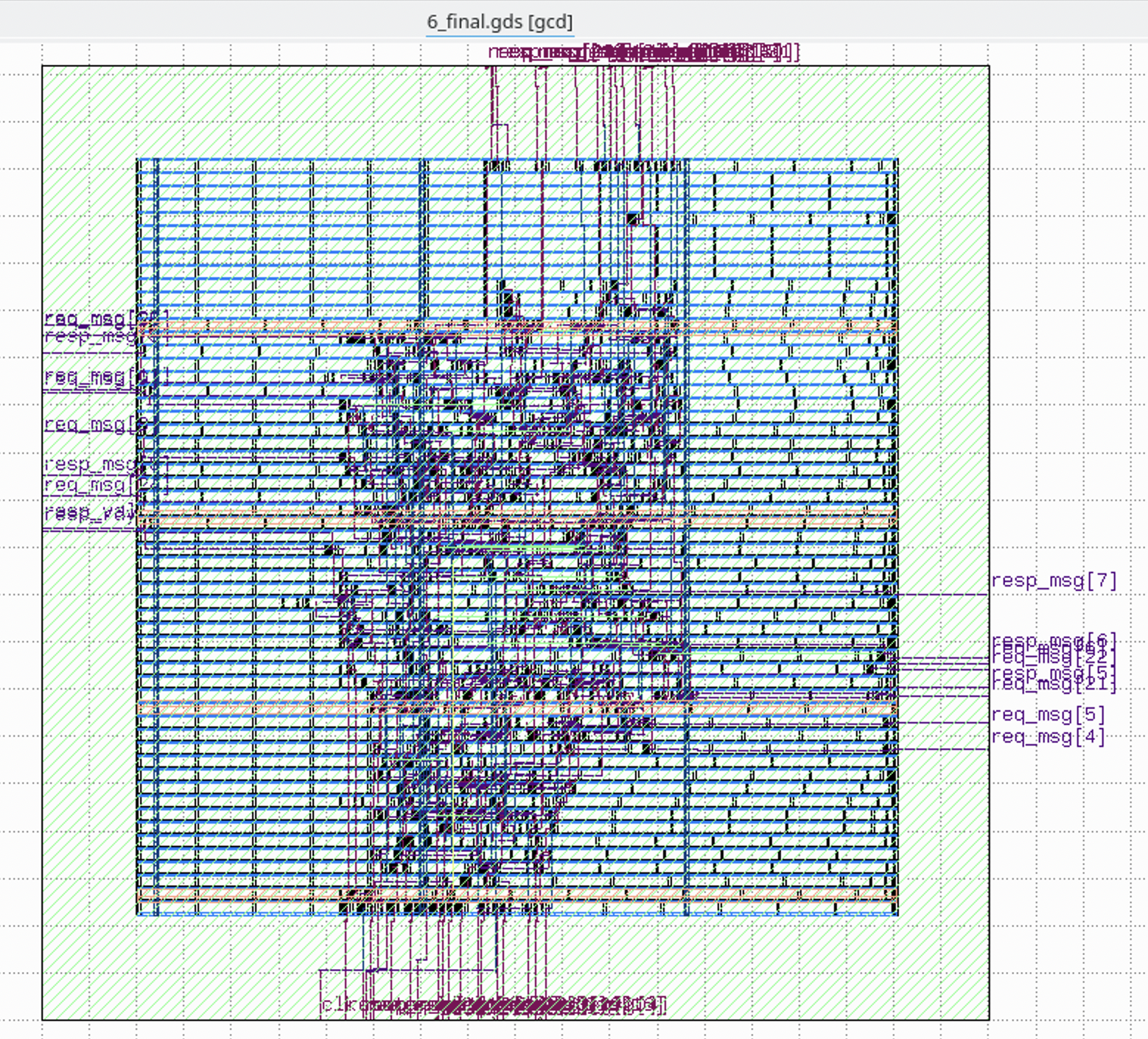
日志里可以看到,预测的总功耗是 1.71 mW,面积占用是 703 um^2。
还跑了一下其他样例设计的 gds,比如 ibex:

日志里可以看到,预测的总功耗是 10.1 mW,面积占用是 32176 um^2。
还有 tiny rocket:
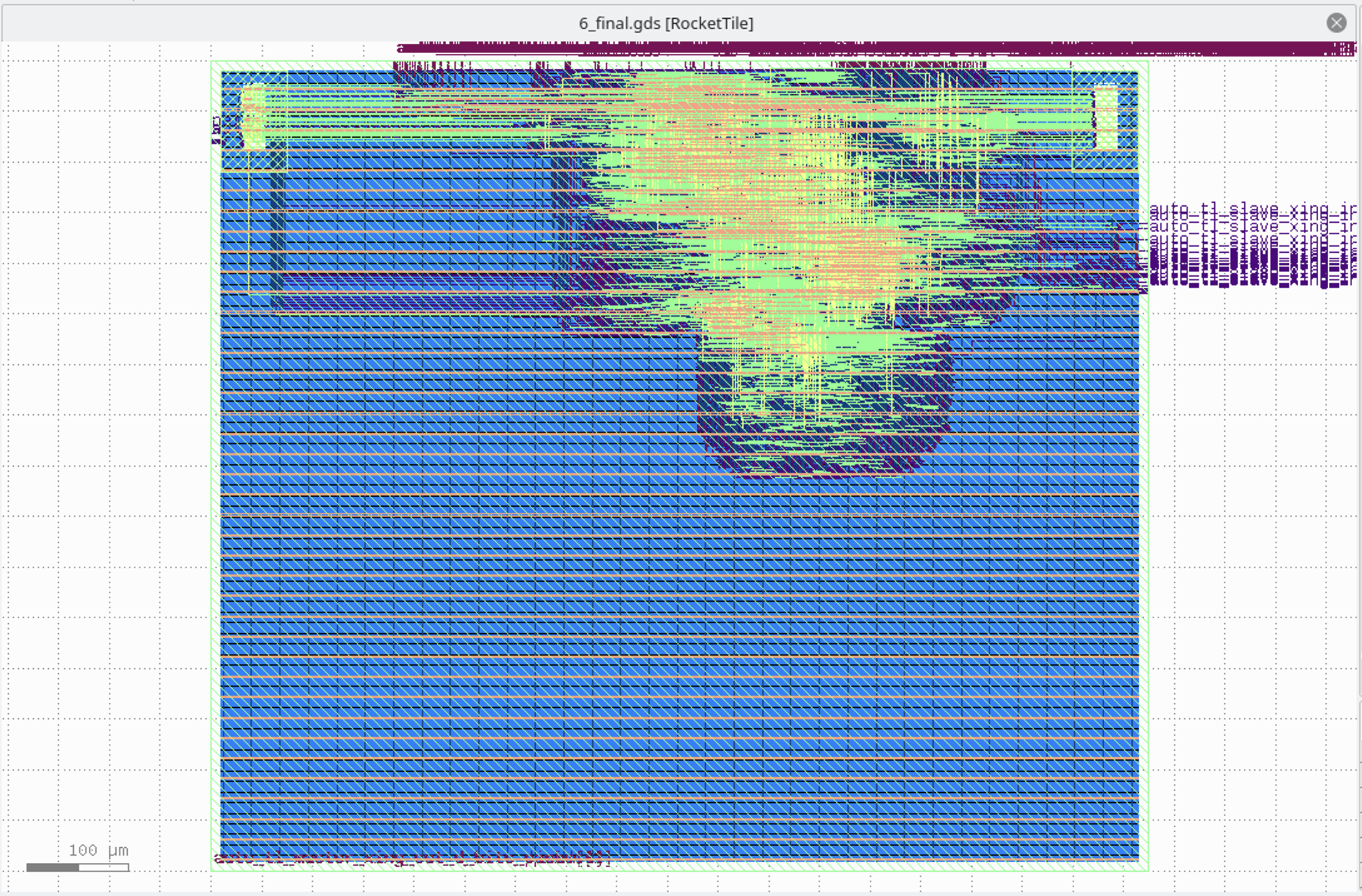
日志里可以看到,预测的总功耗是 36.8 mW,面积占用是 52786 um^2。
ARM 的文档 Choosing the physical IP libraries 描述了 Channel length, Track height, Voltage threshold 等不同的选择。
综合来说,如果要更低的延迟,选择低 vt,小 c 和大 track,反之如果要更低的能耗,选择高 vt,大 c 和 小 track。
由于物理的特性比较复杂,工艺库里描述的也只是一个大致的模型,刻画了这些 cell 的特性,那么自然可以选取不同的模型。NLDM(上面举的例子就是 NLDM),CCS 就是常见的两个模型,相比之下,CCS 更精确,同时参数更多。更精确的还有直接用 SPICE 描述的电路。详细的对比可以看下面的参考文档。
两年前,我尝试过用 BSCAN JTAG 来配置 Rocket Chip 的调试,但是这个方法不是很好用,具体来说,如果有独立的一组 JTAG 信号,配置起来会更方便,而且不用和 Vivado 去抢,OpenOCD 可以和 Vivado hw_server 同时运行和工作。但是,苦于 VCU128 上没有 PMOD 接口,之前一直没考虑过在 VCU128 上配置独立的 JTAG。然后最近研究了一下,终于解决了这个问题。
前几天在研究别的问题的时候,看到 VCU128 文档中的这段话:
The FT4232HL U8 multi-function USB-UART on the VCU128 board provides three level-shifted
UART connections through the single micro-AB USB connector J2.
• Channel A is configured in JTAG mode to support the JTAG chain
• Channel B implements 4-wire UART0 (level-shifted) FPGA U1 bank 67 connections
• Channel C implements 4-wire UART1 (level-shifted) FPGA U1 bank 67 connections
• Channel D implements 2-wire (level-shifted) SYSCTLR U42 bank 501 connections
其中 Channel A 是到 FPGA 本身的 JTAG 接口,是给 Vivado 用的,如果是通过 BSCAN 的方式,也是在这个 Channel 上,但是需要经过 FPGA 自己的 TAP 再隧道到 BSCAN 上,比较麻烦。Channel B 和 C 是串口,Channel D 是连接 VCU128 上的 System Controller 的。之前的时候,都是直接用 Channel B 做串口,然后突发奇想:注意到这里是 4-wire UART,说明连接到 FPGA 是四条线,那是不是也可以拿来当 JTAG 用?
查询了一下 FT4232H 的文档,发现它的 Channel A 和 Channel B 是支持 MPSSE 模式的,在 MPSSE 模式下,可以当成 JTAG 使用:
| Signal | Channel A | Channel B |
|---|---|---|
| TCK | 12 | 22 |
| TDI | 13 | 23 |
| TDO | 14 | 24 |
| TMS | 15 | 25 |
对照 VCU128 的 Schematic 看,虽然引脚的编号不大一样,可以发现,Channel A 和 B 分别对应了 ADBUS0-4 和 BDBUS 0-4,对应到 schematic 上的名字是:
这一组是直接连到 FPGA 上专用的 JTAG 引脚,其中 TDO 是连接了额外的逻辑,可以把 FMC 接口上的 JTAG 连接成 daisy chain。
这里的 RXD/TXD 名字交换也是很容易看错,要小心,只要记住 FT4232H 要求的顺序一定是 TCK-TDI-TDO-TMS 即可。对应到 vivado 内的 xdc 就是这么写:
set_property -dict {PACKAGE_PIN BP26 IOSTANDARD LVCMOS18} [get_ports jtag_TCK]
set_property -dict {PACKAGE_PIN BN26 IOSTANDARD LVCMOS18} [get_ports jtag_TDI]
set_property -dict {PACKAGE_PIN BP22 IOSTANDARD LVCMOS18} [get_ports jtag_TDO]
set_property -dict {PACKAGE_PIN BP23 IOSTANDARD LVCMOS18} [get_ports jtag_TMS]
接下来,我们要把 Rocket Chip 的 JTAG 信号接出来。
配置 Rocket Chip 的 JTAG,大概需要如下几步:
最后一步的相关代码,首先,按照 spec 要求,把 DM 输出的 ndreset 信号连到整个 Rocket 的 reset 上:
// ndreset can reset all harts
val childReset = reset.asBool | target.debug.map(_.ndreset).getOrElse(false.B)
target.reset := childReset
接着,把 JTAG 的信号连到顶层:
val systemJtag = target.debug.get.systemjtag.get
systemJtag.jtag.TCK := io.jtag.TCK
systemJtag.jtag.TMS := io.jtag.TMS
systemJtag.jtag.TDI := io.jtag.TDI
io.jtag.TDO := systemJtag.jtag.TDO
除了 JTAG 信号以外,还需要配置 IDCODE 相关的变量:
systemJtag.mfr_id := p(JtagDTMKey).idcodeManufId.U(11.W)
systemJtag.part_number := p(JtagDTMKey).idcodePartNum.U(16.W)
systemJtag.version := p(JtagDTMKey).idcodeVersion.U(4.W)
最后这一部分比较关键:首先,JTAG 部分的 reset 是独立于其余部分的,这里简单期间就连到了外部的 reset,其实可以改成 FPGA program 的时候进行 reset,然后等时钟来了就释放,实现方法可以参考文末的链接。resetctrl 是给 DM 知道哪些核心被 reset 了,最后是调用 rocket chip 自带的函数。这里踩的一个坑是,传给 systemJtag.reset 一定得是异步的,因为这个时钟域的时钟都是 jtag 的 TCK 信号,所以很可能错过一开始的 reset 信号,所以这里要用异步的 reset。
// MUST use async reset here
// otherwise the internal logic(e.g. TLXbar) might not function
// if reset deasserted before TCK rises
systemJtag.reset := reset.asAsyncReset
target.resetctrl.foreach { rc =>
rc.hartIsInReset.foreach { _ := childReset }
}
Debug.connectDebugClockAndReset(target.debug, clock)
这部分是参考了 pulp 的 VCU118 中 jtag 信号的约束文件。照着抄就行:
create_clock -period 100.000 -name jtag_TCK [get_ports jtag_TCK]
set_input_jitter jtag_TCK 1.000
set_property CLOCK_DEDICATED_ROUTE FALSE [get_nets jtag_TCK_IBUF_inst/O]
set_input_delay -clock jtag_TCK -clock_fall 5.000 [get_ports jtag_TDI]
set_input_delay -clock jtag_TCK -clock_fall 5.000 [get_ports jtag_TMS]
set_output_delay -clock jtag_TCK 5.000 [get_ports jtag_TDO]
set_max_delay -to [get_ports jtag_TDO] 20.000
set_max_delay -from [get_ports jtag_TMS] 20.000
set_max_delay -from [get_ports jtag_TDI] 20.000
set_clock_groups -asynchronous -group [get_clocks jtag_TCK] -group [get_clocks -of_objects [get_pins system_i/clk_wiz_0/inst/mmcme4_adv_inst/CLKOUT1]]
set_property ASYNC_REG TRUE [get_cells -hier -regexp "system_i/rocketchip_wrapper_0/.*/cdc_reg_reg.*"]
和原版本稍微改了一下,一个区别是 set_clock_groups 的时候,第二个时钟参数用的是 Clocking Wizard 的输出,同时也是 Rocket Chip 自己的时钟输入;另一个区别是用的 ASYNC_REG 查询语句不大一样。我没有具体分析过这些约束为什么这么写,不确定这些约束是否都合理,是否都是需要的,没有测试过不带这些约束会不会出问题。
最后,采用如下的 OpenOCD 配置来连接:
# openocd config
# use ftdi channel 1
# vcu128 uart0 as jtag
adapter speed 10000
adapter driver ftdi
ftdi_vid_pid 0x0403 0x6011 # FT4232H
ftdi_layout_init 0x0008 0x000b # Output: TCK TDI TMS
ftdi_tdo_sample_edge falling
ftdi_channel 1 # channel B
reset_config none
set _CHIPNAME riscv
jtag newtap $_CHIPNAME cpu -irlen 5
set _TARGETNAME $_CHIPNAME.cpu
target create $_TARGETNAME.0 riscv -chain-position $_TARGETNAME
$_TARGETNAME.0 configure -work-area-phys 0x80000000 -work-area-size 10000 -work-area-backup 1
然后就可以连接到 Rocket Chip 上:
> openocd -f openocd.cfg
Open On-Chip Debugger 0.11.0-rc2
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
Info : auto-selecting first available session transport "jtag". To override use 'transport select <transport>'.
Info : Listening on port 6666 for tcl connections
Info : Listening on port 4444 for telnet connections
Info : clock speed 10000 kHz
Info : JTAG tap: riscv.cpu tap/device found: 0x10000913 (mfg: 0x489 (SiFive Inc), part: 0x0000, ver: 0x1)
Info : datacount=2 progbufsize=16
Info : Disabling abstract command reads from CSRs.
Info : Examined RISC-V core; found 1 harts
Info : hart 0: XLEN=64, misa=0x800000000094112d
Info : starting gdb server for riscv.cpu.0 on 3333
Info : Listening on port 3333 for gdb connections
> riscv64-unknown-elf-gdb
(gdb) target remote localhost:3333
Remote debugging using localhost:3333
0x00000000800001a4 in ?? ()
可以看到调试功能都正常了。
调试这个功能大概花了一天的时间,主要遇到了下面这些问题:
在使用 Rocket Chip 的时候,难免要和 Diplomacy 打交道,那么它比较特别的语法和使用方式会带来一些学习上的困难,并且文档也比较少。本人在学习 Diplomacy 源码的时候,记录了这个笔记,希望对读者有所启发。
尽量选择较新版本的 Chisel。Chisel v3.5 完善了编译器插件,使得生成的代码中会包括更多变量名信息。
版本:FIRRTL >= 1.5.0-RC2
代码:
new ChiselStage().execute(
Array("-X", "verilog", "-o", s"${name}.v"),
Seq(
ChiselGeneratorAnnotation(genModule),
CustomDefaultRegisterEmission(
useInitAsPreset = false,
disableRandomization = true
)
)
)
设置 disableRandomization=true 即可。useInitAsPreset 不建议开启。
设置 Chisel 生成 MinimumVerilog:
new ChiselStage().execute(
Array("-X", "mverilog", "-o", s"${name}.v"),
Seq(
ChiselGeneratorAnnotation(genModule)
)
)
此时代码中会保留更多原始 Chisel 代码的元素。
Rocket Chip 中 AXI4Bundle 直接生成的名字和标准写法不同,可以利用 Chisel3 3.5.0 的 DataView 功能进行重命名:
// https://www.chisel-lang.org/chisel3/docs/explanations/dataview.html
// use standard names
class StandardAXI4BundleBundle(val addrBits: Int, val dataBits: Int, val idBits: Int)
extends Bundle {
val AWREADY = Input(Bool())
val AWVALID = Output(Bool())
val AWID = Output(UInt(idBits.W))
val AWADDR = Output(UInt(addrBits.W))
val AWLEN = Output(UInt(8.W))
val AWSIZE = Output(UInt(3.W))
val AWBURST = Output(UInt(2.W))
val AWLOCK = Output(UInt(1.W))
val AWCACHE = Output(UInt(4.W))
val AWPROT = Output(UInt(3.W))
val AWQOS = Output(UInt(4.W))
val WREADY = Input(Bool())
val WVALID = Output(Bool())
val WDATA = Output(UInt(dataBits.W))
val WSTRB = Output(UInt((dataBits / 8).W))
val WLAST = Output(Bool())
val BREADY = Output(Bool())
val BVALID = Input(Bool())
val BID = Input(UInt(idBits.W))
val BRESP = Input(UInt(2.W))
val ARREADY = Input(Bool())
val ARVALID = Output(Bool())
val ARID = Output(UInt(idBits.W))
val ARADDR = Output(UInt(addrBits.W))
val ARLEN = Output(UInt(8.W))
val ARSIZE = Output(UInt(3.W))
val ARBURST = Output(UInt(2.W))
val ARLOCK = Output(UInt(1.W))
val ARCACHE = Output(UInt(4.W))
val ARPROT = Output(UInt(3.W))
val ARQOS = Output(UInt(4.W))
val RREADY = Output(Bool())
val RVALID = Input(Bool())
val RID = Input(UInt(idBits.W))
val RDATA = Input(UInt(dataBits.W))
val RRESP = Input(UInt(2.W))
val RLAST = Input(Bool())
}
object StandardAXI4BundleBundle {
implicit val axiView = DataView[StandardAXI4BundleBundle, AXI4Bundle](
vab =>
new AXI4Bundle(
AXI4BundleParameters(vab.addrBits, vab.dataBits, vab.idBits)
),
// AW
_.AWREADY -> _.aw.ready,
_.AWVALID -> _.aw.valid,
_.AWID -> _.aw.bits.id,
_.AWADDR -> _.aw.bits.addr,
_.AWLEN -> _.aw.bits.len,
_.AWSIZE -> _.aw.bits.size,
_.AWBURST -> _.aw.bits.burst,
_.AWLOCK -> _.aw.bits.lock,
_.AWCACHE -> _.aw.bits.cache,
_.AWPROT -> _.aw.bits.prot,
_.AWQOS -> _.aw.bits.qos,
// W
_.WREADY -> _.w.ready,
_.WVALID -> _.w.valid,
_.WDATA -> _.w.bits.data,
_.WSTRB -> _.w.bits.strb,
_.WLAST -> _.w.bits.last,
// B
_.BREADY -> _.b.ready,
_.BVALID -> _.b.valid,
_.BID -> _.b.bits.id,
_.BRESP -> _.b.bits.resp,
// AR
_.ARREADY -> _.ar.ready,
_.ARVALID -> _.ar.valid,
_.ARID -> _.ar.bits.id,
_.ARADDR -> _.ar.bits.addr,
_.ARLEN -> _.ar.bits.len,
_.ARSIZE -> _.ar.bits.size,
_.ARBURST -> _.ar.bits.burst,
_.ARLOCK -> _.ar.bits.lock,
_.ARCACHE -> _.ar.bits.cache,
_.ARPROT -> _.ar.bits.prot,
_.ARQOS -> _.ar.bits.qos,
// R
_.RREADY -> _.r.ready,
_.RVALID -> _.r.valid,
_.RID -> _.r.bits.id,
_.RDATA -> _.r.bits.data,
_.RRESP -> _.r.bits.resp,
_.RLAST -> _.r.bits.last
)
implicit val axiView2 = StandardAXI4BundleBundle.axiView.invert(ab =>
new StandardAXI4BundleBundle(
ab.params.addrBits,
ab.params.dataBits,
ab.params.idBits
)
)
}
// usage
val MEM = IO(new StandardAXI4BundleBundle(32, 64, 4))
MEM <> target.mem_axi4.head.viewAs[StandardAXI4BundleBundle]
有些时候,我们希望给所有模块添加一个名称前缀,防止可能出现的冲突。
在 Chisel 3 中,可以使用自定义 FIRRTL Transform 来实现这个功能。这一部分的实现参考了 chisel issue #1059:
import firrtl._
import firrtl.annotations.NoTargetAnnotation
import firrtl.options.Dependency
import firrtl.passes.PassException
import firrtl.transforms.DedupModules
// adapted from https://github.com/chipsalliance/chisel3/issues/1059#issuecomment-814353578
/** Specifies a global prefix for all module names. */
case class ModulePrefix(prefix: String) extends NoTargetAnnotation
/** FIRRTL pass to add prefix to module names
*/
object PrefixModulesPass extends Transform with DependencyAPIMigration {
// we run after deduplication to save some work
override def prerequisites = Seq(Dependency[DedupModules])
// we do not invalidate the results of any prior passes
override def invalidates(a: Transform) = false
override protected def execute(state: CircuitState): CircuitState = {
val prefixes = state.annotations.collect { case a: ModulePrefix =>
a.prefix
}.distinct
prefixes match {
case Seq() =>
logger.info("[PrefixModulesPass] No ModulePrefix annotation found.")
state
case Seq("") => state
case Seq(prefix) =>
val c = state.circuit.mapModule(onModule(_, prefix))
state.copy(circuit = c.copy(main = prefix + c.main))
case other =>
throw new PassException(
s"[PrefixModulesPass] found more than one prefix annotation: $other"
)
}
}
private def onModule(m: ir.DefModule, prefix: String): ir.DefModule =
m match {
case e: ir.ExtModule => e.copy(name = prefix + e.name)
case mod: ir.Module =>
val name = prefix + mod.name
val body = onStmt(mod.body, prefix)
mod.copy(name = name, body = body)
}
private def onStmt(s: ir.Statement, prefix: String): ir.Statement = s match {
case i: ir.DefInstance => i.copy(module = prefix + i.module)
case other => other.mapStmt(onStmt(_, prefix))
}
}
实现思路就是遍历 IR,找到所有的 Module 并改名,再把所有模块例化也做一次替换。最后在生成 Verilog 的时候添加 Annotation 即可:
new ChiselStage().execute(
Array("-o", s"${name}.v"),
Seq(
ChiselGeneratorAnnotation(genModule),
RunFirrtlTransformAnnotation(Dependency(PrefixModulesPass)),
ModulePrefix(prefix)
)
如果使用新的 MLIR FIRRTL Compiler,则可以利用 sifive.enterprise.firrtl.NestedPrefixModulesAnnotation annotation,让 firtool 来进行 prefix 操作:
package sifive {
package enterprise {
package firrtl {
import _root_.firrtl.annotations._
case class NestedPrefixModulesAnnotation(
val target: Target,
prefix: String,
inclusive: Boolean
) extends SingleTargetAnnotation[Target] {
def duplicate(n: Target): Annotation =
NestedPrefixModulesAnnotation(target, prefix, inclusive)
}
}
}
}
object AddPrefix {
def apply(module: Module, prefix: String, inclusive: Boolean = true) = {
annotate(new ChiselAnnotation {
def toFirrtl =
new NestedPrefixModulesAnnotation(module.toTarget, prefix, inclusive)
})
}
}
这个方法的灵感来自 @sequencer。唯一的缺点就是比较 Hack,建议 SiFive 把相关的类也开源出来用。
到了 Chisel 7.0,模块名称前缀的功能已经内置:Module Prefixing。
Chisel3 生成 Verilog/System Verilog 的时候会进行一些优化。如果想要关闭这些优化,可以使用:
--preserve-values=[none/named/all],见 FIRRTL Dialect Rationale本文的内容已经整合到知识库中。
最近在《高等计算机系统结构》课程中学习缓存一致性协议算法,这里用自己的语言来组织一下相关知识的讲解。
最基础的缓存一致性思想有两种:
Write-once 协议定义了四个状态:
可见,当一个缓存状态在 R 或者 D,其他缓存只能是 I;而缓存状态是 V 的时候,可以有多个缓存在 V 状态。
Write-once 协议的特点是,第一次写的时候,会写入到内存(类似 Write-through),连续写入则只写到缓存中,类似 Write-back。
当 Read hit 的时候,状态不变。
Read hit: The information is supplied by the current cache. No state change.
当 Read miss 的时候,会查看所有缓存,如果有其他缓存处于 Valid/Reserved/Dirty 状态,就从其他缓存处读取数据,然后设为 Valid,其他缓存也设为 Valid。如果其他缓存处于 Dirty 状态,还要把数据写入内存。
Read miss: The data is read from main memory. The read is snooped by other caches; if any of them have the line in the Dirty state, the read is interrupted long enough to write the data back to memory before it is allowed to continue. Any copies in the Dirty or Reserved states are set to the Valid state.
当 Write hit 的时候,如果是 Valid 状态,首先写入内存,把其他 Cache 都设为 Invalid,进入 Reserved 状态,这意味着第一次写是 Write-through。如果是 Reserved/Dirty 状态,则不修改内存,进入 Dirty 状态,这表示后续的写入都是 Write-back。
Write hit: If the information in the cache is in Dirty or Reserved state, the cache line is updated in place and its state is set to Dirty without updating memory. If the information is in Valid state, a write-through operation is executed updating the block and the memory and the block state is changed to Reserved. Other caches snoop the write and set their copies to Invalid.
当 Write miss 的时候,这个行为 Wikipedia 上和上课讲的不一样。按照 Wikipedia 的说法,首先按照 Read miss 处理,再按照 Write hit 处理,类似于 Write Allocate 的思路。如果是这样的话,那么首先从其他缓存或者内存读取数据,然后把其他缓存都设为 Invalid,把更新后的数据写入内存,进入 Reserved 状态。相当于 Write miss 的时候,也是按照 Write-through 实现。
Write miss: A partial cache line write is handled as a read miss (if necessary to fetch the unwritten portion of the cache line) followed by a write hit. This leaves all other caches in the Invalid state, and the current cache in the Reserved state.
教材上则是 Write miss 的时候按照 Write-back 处理。如果其他缓存都是 Invalid 时,从内存里读取数据,然后写入到缓存中,进入 Dirty 状态。如果其他缓存是 Valid/Reserved/Dirty 状态,就从其他缓存里读取数据,让其他缓存都进入 Invalid 状态,然后更新自己的数据,进入 Dirty 状态。
MSI 协议比较简单,它定义了三个状态:
当 Read hit 的时候,状态不变。
当 Read miss 的时候,检查其他缓存的状态,如果都是 Invalid,就从内存里读取,然后进入 Shared 状态。如果有 Shared,就从其他缓存处读取。如果有 Dirty,那就要把其他缓存的数据写入内存和本地缓存,然后进入 Shared 状态。
当 Write hit 的时候,如果现在是 Shared 状态,则要让其他的 Shared 缓存进入 Invalid 状态,然后更新数据,进入 Modified 状态。如果是 Modified 状态,那就修改数据,状态保持不变。
当 Write miss 的时候,如果有其他缓存处于 Modified/Shared 状态,那就从其他缓存处读取数据,并让其他缓存进入 Invalid 状态,然后修改本地数据,进入 Modified 状态。如果所有缓存都是 Invalid 状态,那就从内存读入,然后修改缓存数据,进入 Modified 状态。
MESI 协议定义了四种状态:
当 Read hit 的时候,状态不变。
当 Read miss 的时候,首先会检查其他缓存的状态,如果有数据,就从其他缓存读取数据,并且都进入 Shared 状态,如果其他缓存处于 Modified 状态,还需要把数据写入内存;如果其他缓存都没有数据,就从内存里读取,然后进入 Exclusive 状态。
当 Write hit 的时候,进入 Modified 状态,同时让其他缓存进入 Invalid 状态。
当 Write miss 的时候,检查其他缓存的状态,如果有数据,就从其他缓存读取,否则从内存读取。然后,其他缓存都进入 Invalid 状态,本地缓存更新数据,进入 Modified 状态。
值得一提的是,Shared 状态不一定表示只有一个缓存有数据:比如本来有两个缓存都是 Shared 状态,然后其中一个因为缓存替换变成了 Invalid,那么另一个是不会受到通知变成 Exclusive 的。Exclusive 的设置是为了减少一些总线请求,比如当数据只有一个核心访问的时候,只有第一次 Read miss 会发送总线请求,之后一直在 Exclusive/Modified 状态中,不需要发送总线请求。
MOESI 定义了五个状态:
状态中,M 和 E 是独占的,所有缓存里只能有一个。此外,可以同时有多个 S,或者多个 S 加一个 O,但是不能同时有多个 O。
它的状态转移与 MESI 类似,区别在于:当核心写入 Owned 状态的缓存时,有两种方式:1)通知其他 Shared 的缓存更新数据;2)把其他 Shared 缓存设为 Invalid,然后本地缓存进入 Modified 状态。在 Read miss 的时候,则可以从 Owned 缓存读取数据,进入 Shared 状态,而不用写入内存。它相比 MESI 的好处是,减少了写回内存的次数。
AMD64 文档里采用的就是 MOESI 协议。AMBA ACE 协议其实也是 MOESI 协议,只不过换了一些名称,表示可以兼容 MEI/MESI/MOESI 中的一个协议。ACE 对应关系如下:
需要注意的是,SharedClean 并不代表它的数据和内存一致,比如说和 SharedDirty 缓存一致,它只是说缓存替换的时候,不需要写回内存。
Dragon 协议是一个基于更新的协议,意味着写入缓存的时候,会把更新的数据同步到拥有这个缓存行的其他核心。它定义了四个状态:
可以看到,E 和 M 都是独占的,如果出现了多个缓存有同一个缓存行,那就是若干个 Sc 和一个 Sm。
当 Read miss 的时候,在总线上检查是否有缓存已经有这个缓存行的数据,如果没有,则从内存读取并转到 Exclusive clean 状态;如果已经在其他缓存中,则从其他缓存读取,将其他缓存转移到 Shared clean/Shared modified 状态,然后该缓存转移到 Shared clean 状态。
当 Write miss 的时候,同样检查其他缓存的状态,如果是第一个访问的,就从内存读取,更新数据,然后转到 Modify 状态;如果不是第一个访问的,就进入 Shared modified 状态,并且让原来 Shared modified 的缓存进入 Shared clean 状态。
当 Write hit 的时候,如果状态是 Shared modified,这时候需要通知其他缓存更新数据;如果状态是 Shared clean,则要通知其他缓存更新数据的同时,让原来 Shared modified 的缓存进入 Shared clean 状态;如果状态是 Exclusive clean,则进入 Modify 状态。
在这里,Shared modified 的缓存负责在换出的时候,写入数据到内存中。
ACE 协议在 AXI 的基础上,添加了三个 channel:
此外,已有的 Channel 也添加了信号:
ACE-lite 只在已有 Channel 上添加了新信号,没有添加新的 Channel。因此它内部不能有 Cache,但是可以访问一致的缓存内容。
当 Read miss 的时候,首先 AXI master 发送 read transaction 给 Interconnect,Interconnect 向保存了这个缓存行的缓存发送 AC 请求,如果有其他 master 提供了数据,就向请求的 master 返回数据;如果没有其他 master 提供数据,则向内存发起读请求,并把结果返回给 master,最后 master 提供 RACK 信号。
当 Write miss 的时候,也是类似地,AXI master 发送 MakeUnique 请求给 Interconnect,Interconnect 向保存了该缓存行的缓存发送请求,要求其他 master 状态改为 Invalid;当所有 master 都已经 invalidate 成功,就向原 AXI master 返回结果。
上面的缓存一致性协议中,经常有这么一个操作:向所有有这个缓存行的缓存发送/接受消息。简单的方法是直接广播,然后接受端自己判断是否处理。但是这个方法在核心很多的时候会导致广播流量太大,因此需要先保存下来哪些缓存会有这个缓存的信息,然后对这些缓存点对点地发送。这样就可以节省一些网络流量。
那么,怎么记录这个信息呢?一个简单的办法(Full bit vector format)是,有一个全局的表,对每个缓存行,都记录一个大小为 N(N 为核心数)的位向量,1 表示对应的核心中有这个缓存行。但这个方法保存数据量太大:缓存行数正比于 N,还要再乘以一次 N,总容量是 O(N^2) 的。
一个稍微好一些的方法(Coarse bit vector format)是,我把核心分组,比如按照 NUMA 节点进行划分,此时每个缓存行都保存一个大小为 M(M 为 NUMA 数量)的位向量,只要这个 NUMA 节点里有这个缓存行,对应位就取 1。这样相当于是以牺牲一部分流量为代价(NUMA 节点内部广播),来节省一些目录的存储空间。
但实际上,通常情况下,一个缓存行通常只会在很少的核心中保存,所以这里有很大的优化空间。比如说,可以设置一个缓存行同时出现的缓存数量上限 (Limited pointer format),然后保存核心的下标而不是位向量,这样的存储空间就是 O(Nlog2N)。但是呢,这样限制了缓存行同时出现的次数,如果超过了上限,需要替换掉已有的缓存,可能在一些场景下性能会降低。
还有一种方式,就是链表 (Chained directory format)。目录中保存最后一次访问的核心编号,然后每个核心的缓存里,保存了下一个保存了这个缓存行的核心编号,或者表示链表终止。这样存储空间也是 O(Nlog2N),不过发送消息的延迟更长,因为要串行遍历一遍,而不能同时发送。类似地,可以用二叉树 (Number-balanced binary tree format) 来组织:每个缓存保存两个指针,指向左子树和右子树,然后分别遍历,目的还是加快遍历的速度,可以同时发送消息给多个核心。
最近我们设计的 Kintex 7 FPGA 开发板在测试 DDR SDRAM 的时候遇到了一个问题,因为采用了 Internel VREF,MIG 在配置的时候限制了频率只能是 400 MHz,对应 800 MT/s,这样无法达到 DDR 的最好性能。
首先,VREF 在 DDR 中是用来区分低电平和高电平的。在 JESD79-4B 标准中,可以看到,对于直流信号,电压不小于 VREF+0.075V 时表示高电平,而电压不高于 VREF-0.075V 时表示低电平。VREF 本身应该介于 VDD 的 0.49 倍到 0.51 倍之间。
在连接 FPGA 的时候,有两种选择:
对于 7 Series 的 FPGA,Xilinx 要求如下:
For DDR3 SDRAM interfaces running at or below 800 Mb/s (400 MHz),
users have the option of selecting Internal VREF to save two I/O
pins or using external VREF. VREF is required for banks containing
DDR3 interface input pins (DQ/DQS).
进一步,Xilinx 在 UltraScale 文档下解释了背后的原因:
The UltraScale internal VREF circuit includes enhancements compared
to the 7 Series internal VREF circuit. Whereas 7 Series MIG had datarate
limitations on internal VREF usage (see (Xilinx Answer 42036)), internal
VREF is recommended in UltraScale. The VREF for 7 Series had coarse steps
of VREF value that were based on VCCAUX. This saved pins but limited the
performance because VCCAUX did not track with VCCO as voltage went up and
down. Not being able to track with VCCO enforced the performance
limitations of internal VREF in MIG 7 Series. UltraScale includes several
changes to internal VREF including a much finer resolution of VREF for DDR4
read VREF training. Additionally, internal VREF is based on the VCCO supply
enabling it to track with VCCO. Internal VREF is not subject to PCB and
Package inductance and capacitance. These changes in design now give internal
VREF the highest performance.
用中文简单来说:
以 MA703FA-35T 开发板为例,它使用的 FPGA 是 Artix7 35T,内存是 DDR3,采用的是 External VREF。它采用了 TPS51200 Sink and Source DDR Termination Regulator 芯片,将芯片的 REFOUT 芯片接到 DRAM 的 VREFDQ 和 VREFCA 引脚上。
本文的内容已经整合到知识库中。
DRAM 分成很多层次:Bank Group,Bank,Row,Column,从大到小,容量也是各级别的乘积。
举例子:
那么总大小就是 4*4*32768*1024*4=2 Gb。
DRAM 的访问模式决定了访问内存的实际带宽。对于每次访问,需要这样的操作:
可以看到,如果访问连续的地址,就可以省下 ACT 命令的时间,可以连续的进行 RD/WR 命令操作。
除了显式 PRE 以外,还可以在某次读写之后自动进行 PRE:WRA(Write with Auto-Precharge) 和 RDA(Read with Auto-Precharge)。
总结一下上面提到的六种命令:
除此之外,还有一些常用命令:
DRAM 有很多参数,以服务器上的内存 MTA36ASF2G72PZ-2G3A3 为例子:
容量:每个 DRAM 颗粒 64K*1K*4*4*4=4Gb,不考虑 ECC,一共有 16*2=32 个这样的颗粒,实际容量是 16 GB。32 个颗粒分为两组,每组 16 个颗粒,两组之间通过 CS_n 片选信号区分。每组 16 个颗粒,每个颗粒 4 位 DQ 数据信号,合并起来就是 64 位,如果考虑 ECC 就是 72 位。
再举一个 FPGA 开发板上内存的例子:MT40A512M16LY-075E,参数如下:
13.50ns(=18*0.750)13.50ns(=18*0.750)13.50ns(=18*0.750)总大小:2*4*64K*1K*16=1GB。这个开发板用了 5 个 DRAM 芯片,只采用了其中的 4.5 个芯片:最后一个芯片只用了 8 位数据,这样就是 4.5*16=72 位的数据线,对应 64 位+ECC。
可以看到,上面的 DRAM Datasheet 里提到了三个时序参数:
如果第一次访问一个 Row 中的数据,并且之前没有已经打开的 Row,那么要执行 ACT 和 RD 命令,需要的周期数是 RCD+CL;如果之前已经有打开了的 Row,那么要执行 PRE,ACT 和 RD 命令,需要的周期数是 RP+RCD+CL。但如果是连续访问,虽然还需要 CL 的延迟,但是可以流水线起来,充分利用 DDR 的带宽。
如果把这个换算到 CPU 角度的内存访问延迟的话,如果每次访问都是最坏情况,那么需要 17+17+17=51 个 DRAM 时钟周期,考虑 DRAM 时钟是 1200MHz,那就是 42.5ns,这个相当于是 DRAM 内部的延迟,实际上测得的是 100ns 左右。
更严格来说,读延迟 READ Latency = AL + CL + PL,其中 AL 和 PL 是可以配置的,CL 是固有的,所以简单可以认为 READ Latency = CL。同理 WRITE Latency = AL + CWL + PL,可以简单认为 WRITE Latency = CWL。CWL 也是可以配置的,不同的 DDR 速率对应不同的 CWL,范围从 1600 MT/s 的 CWL=9 到 3200 MT/s 的 CWL=20,具体见 JESD79-4B 标准的 Table 7 CWL (CAS Write Latency)。
用 Micron 提供的 Verilog Model 进行仿真,可以看到如下的波形图:
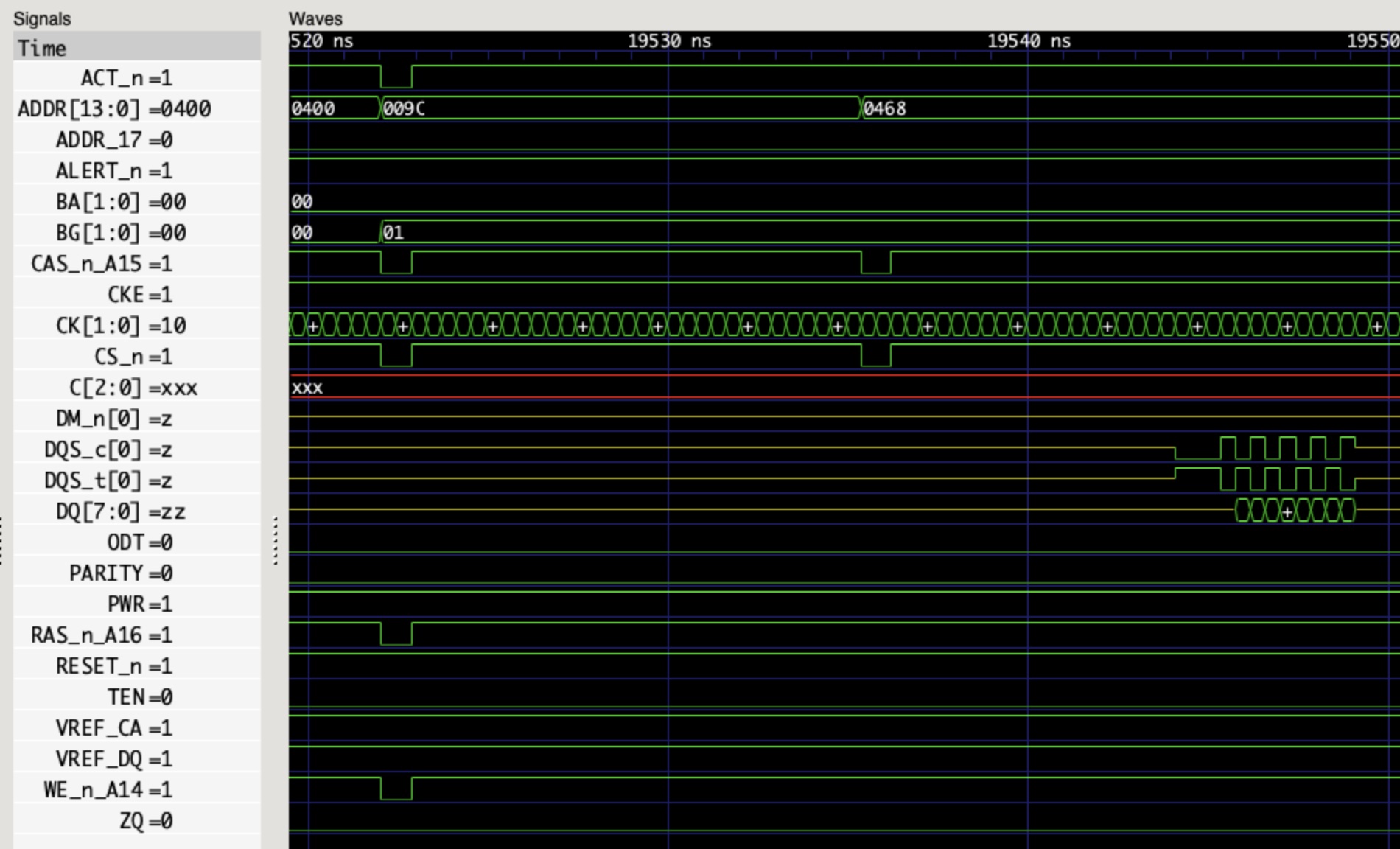
首先看第一个命令,ACT_n=0, ADDR=0x009C, CAS_n_A15=0, CKE=1->1, CS_n=0, RAS_n_A16=0, WE_n_A14=1,查阅标准可知这是 ACT(Bank Activate) 命令。接着第二个命令,ACT_n=1, ADDR=0x0400, CAS_n_A15=0, CKE=1->1, CS_n=0, RAS_n_A16=1, WE_n_A14=1, A10=1, 这是 RDA(Read with Auto Precharge) 命令。若干个周期后,读取的数据从 DQ 上输出,一共 8 个字节的数据。
DRAM 的一个特点是需要定期刷新。有一个参数 tREFI,表示刷新的时间周期,这个值通常是 7.8us,在温度大于 85 摄氏度时是 3.9 us(见 JESD79-4B Table 131)。在刷新之前,所有的 bank 都需要 Precharge 完成并等待 RP 的时间,这时候所有的 Bank 都是空闲的,再执行 REF(Refresh) 命令。等待 tRFC(Refresh Cycle) 时间后,可以继续正常使用。
为了更好的性能,DDR4 标准允许推迟一定次数的刷新,但是要在之后补充,保证平均下来依然满足每过 tREFI 时间至少一次刷新。
如果研究 DRAM 内存控制器,比如 FPGA 上的 MIG,可以发现它可以配置不同的地址映射方式,例如:
就是将地址的不同部分映射到 DRAM 的几个地址:Row,Column,Bank。可以想象,不同的地址映射方式针对不同的访存模式会有不同的性能。对于连续的内存访问,ROW_COLUMN_BANK 方式是比较适合的,因为连续的访问会分布到不同的 Bank 上,这样性能就会更好。
此外,如果访问会连续命中同一个 Page,那么直接读写即可;反之如果每次读写几乎都不会命中同一个 Page,那么可以设置 Auto Precharge,即读写以后自动 Precharge,减少了下一次访问前因为 Row 不同导致的 PRE 命令。一个思路是在对每个 Page 的最后一次访问采用 Auto Precharge。
DDR SDRAM 的传输速率计算方式如下:
Memory Speed (MT/s) * 64 (bits/transfer)
例如一个 DDR4-3200 的内存,带宽就是 3200 * 64 = 204.8 Gb/s = 25.6 GB/s。但前面已经看到,除了传输数据,还需要进行很多命令,实际上很难达到 100% 的带宽。然后 CPU 可以连接多个 channel 的 DRAM,再考虑多个 CPU Socket,系统的总带宽就是
Memory Speed (MT/s) * 64 (bits/transfer) * Channels * Sockets
使用 MLC 等工具进行测试,计算实际与理论的比值,我测试得到的大概在 70%-90% 之间。
HBM 相比前面的 DDR SDRAM,它堆叠了多个 DRAM,提供多个 channel 并且提高了位宽。例如 Micron HBM with ECC,堆叠了 4/8 层 DRAM,提供 8 个 channel,每个 channel 的数据宽度是 128 位,以 3200 MT/s 计算,一个 HBM 芯片的传输速率最大是:
3200 (MT/s) * 128 (bits/transfer) * 8 (Channels) = 3276.8 Gb/s = 409.6 GB/s
所以一片 HBM 的传输速率就相当于 16 个传统的 DDR SDRAM:8 个 Channel 加双倍的位宽。128 位实际上就是把两片 64-bit DDR SDRAM 并起来了,可以当成一个 128 位的用,也可以在 Pseudo Channel 模式下,当成共享地址和命令信号的两个 DDR SDRAM 用。
Xilinx 的 Virtex Ultrascale Plus HBM FPGA 提供了 1800 (MT/s) * 128 (bits/transfer) * 8 (Channels) = 230.4 GB/s 的带宽,如果用了两片 HBM 就是 460.8 GB/s。暴露给 FPGA 逻辑的是 16 个 256 位的 AXI3 端口,AXI 频率 450 MHz,内存频率 900 MHz。可以看到,每个 AXI3 就对应了一个 HBM 的 pseudo channel。每个 pseudo channel 是 64 位,但是 AXI 端口是 256 位:在速率不变的情况下,从 450MHz 到 900MHz,再加上 DDR,相当于频率翻了四倍,所以位宽要从 64 位翻四倍到 256 位。
当然了,HBM 的高带宽的代价就是引脚数量很多。根据 HBM3 JESD238A,每个 Channel 要 120 个 pin,一共 16 个 channel(HBM2 是 8 channel,每个 channel 128 位;HBM3 是 16 channel,每个 channel 64 位),然后还有其他的 52 个 pin,这些加起来就 1972 个 pin 了。所以一般在 Silicon Interposer 上连接,而不是传统的在 PCB 上走线(图源 A 1.2V 20nm 307GB/s HBM DRAM with At-Speed Wafer-Level I/O Test Scheme and Adaptive Refresh Considering Temperature Distribution):
所以在 HBM3 标准里,用 Microbump 来描述 HBM 的 pin。
可以理解为把原来插在主板上的内存条,通过堆叠,变成一个 HBM Die,然后紧密地连接到 CPU 中。但是另一方面,密度上去了,价格也更贵了。
A100 显卡 40GB PCIe 版本提供了 1555 GB/s 的内存带宽。根据倍数关系,可以猜测是 5 个 8GB 的 HBM,每个提供 1555 / 5 = 311 GB/s 的带宽,那么时钟频率就是 311 (GB/s) * 8 (bits/byte) / 128 (bits/transfer) / 8 (channels) / 2 (DDR) = 1215 MHz,这与 nvidia-smi -q 看到的结果是一致的。
进一步,A100 80GB PCIe 版本提供了 1935 GB/s 的带宽,按照同样的方法计算,可得时钟频率是 1935 (GB/s) / 5 * 8 (bits/byte) / 128 (bits/transfer) / 8 (channels) / 2(DDR) = 1512 MHz,与 Product Brief 一致。频率的提高是因为从 HBM2 升级到了 HBM2e。
A100 文档中的 Memory bus width 5120 的计算方式也就清楚了:128 (bits/transfer) * 8 (channels) * 5 (stacks) = 5120 (bits)。
H100 SXM5 升级到了 HBM3,内存容量依然是 80GB,但是时钟频率提高,内存带宽是 2619 (MHz) * 2 (DDR) * 128 (bits/transfer) * 8 (channels) * 5 (stacks) / 8 (bits/byte) = 3352 GB/s。