SDRAM (Synchronous Dynamic Random Access Memory)
Features
SDRAM features:
- low cost, each 1 bit cell requires only one CMOS transistor
- complex interface, you need to activate a row before accessing data, and then read the data in the row
- the controller is also complex and requires periodic memory refreshing
- large capacity, because the row and column multiplexed address lines, a single memory module can achieve GB level capacity
Standards
SDRAM-related standards are developed by JEDEC:
- JESD79F: DDR SDRAM
- JESD79-2F: DDR2 SDRAM
- JESD79-3F: DDR3 SDRAM
- JESD79-4D: DDR4 SDRAM
- JESD79-5B: DDR5 SDRAM
In addition to the DDR series, there is also a low-power LPDDR series:
- JESD209B: LPDDR SDRAM
- JESD209-2F: LPDDR2 SDRAM
- JESD209-3C: LPDDR3 SDRAM
- JESD209-4D: LPDDR4 SDRAM
- JESD209-5B: LPDDR5 SDRAM
High-performance HBM is also based on SDRAM technology:
GDDR SGRAM series:
- SDRAM3.11.5.8 R16.01: GDDR4 SGRAM
- JESD212C.01: GDDR5 SGRAM
- JESD232A.01: GDDR5X SGRAM
- JESD250D: GDDR6 SGRAM
The following is an introduction to DDR series SDRAM.
Concepts
DDR SDRAM is often given a number to represent its performance, such as 2133 for DDR4-2133, and sometimes you will see the term 2400 MT/s. Both refer to the maximum number of data transfers per second that SDRAM can perform in millions of transfers per second. Since SDRAM uses DDR to transfer two copies of data per clock cycle, the actual clock frequency is divided by two, so 2133 MT/s corresponds to a clock frequency of 1066 MHz.
Sometimes you will also see PC4-21333 written to describe memory sticks, where \(21333 = 8*2666\), which is 2666 MT/s, multiplied by 8 because the data bit width of a DDR memory module is 64 bits, so the theoretical memory bandwidth of a 2666 MT/s memory stick is \(2666 \mathrm{(MT/s)} * 64 \mathrm{(bits)} / 8 \mathrm{(bits/byte)} = 21333 \mathrm{(MB/s)}\). But there are times when PC4 is followed by MT/s.
Different generations of memory modules have different locations for the notches on the bottom pins, so it is impossible to insert them in the wrong place.
Structure
Taking DDR4 SDRAM as an example, the following is the structure of the MT40A1G8 chip:
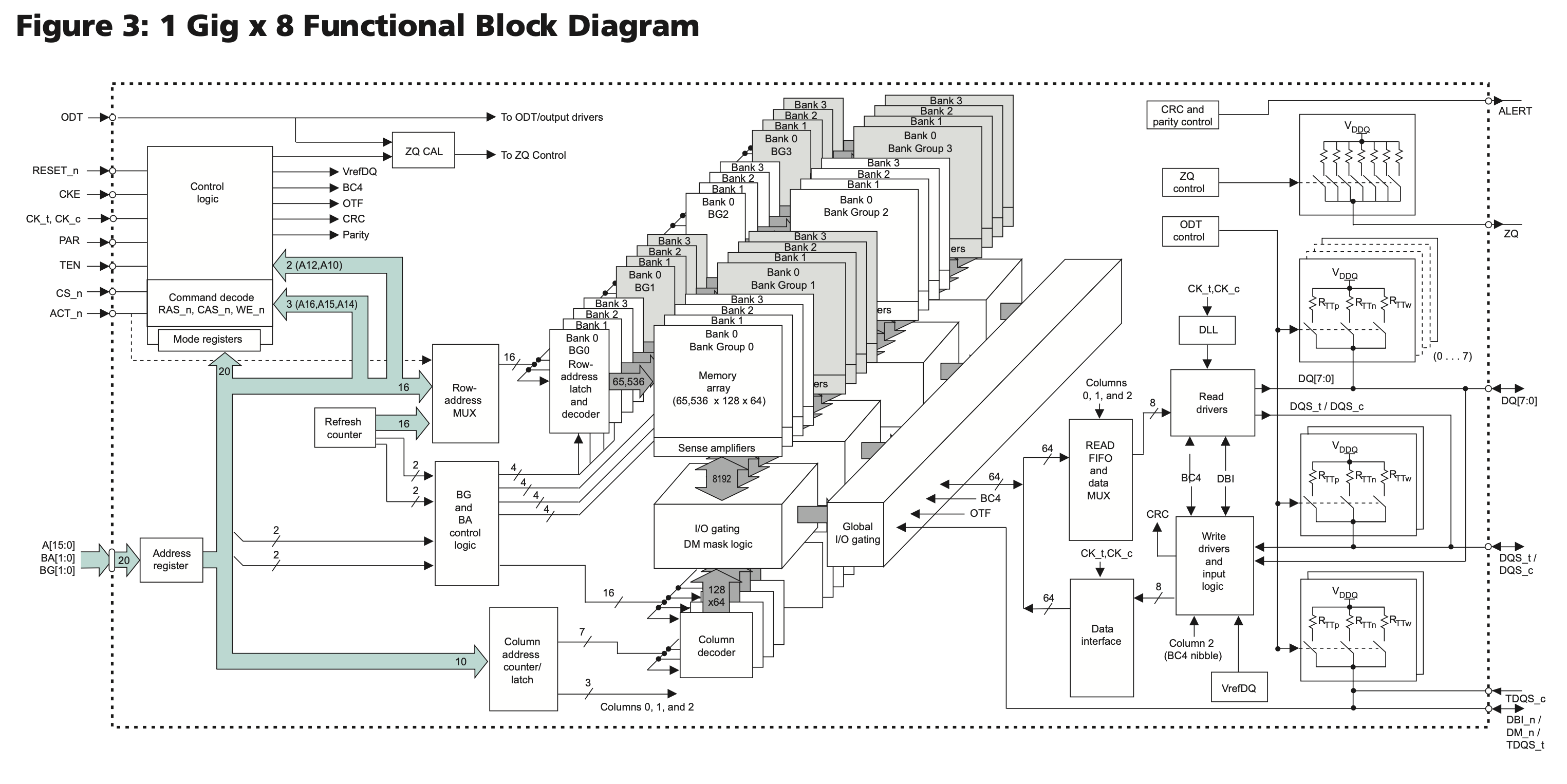
Each memory array is 65536 x 128 x 64, called a Bank; four Banks form a Bank Group, and there are 4 Bank Groups, so the total capacity is \(65536 * 128 * 64 * 4 * 4 = 8 \mathrm{Gb}\).
Specifically, in the 65536 x 128 x 64 specification of each memory array, 65536 represents the number of rows, each row holds \(128 * 64 = 8192\) bits of data, and is also the bit width of the transfer between Sense amplifier and I/O gating, DM mask logic in Figure 1. Each row has 1024 columns, and each column holds 8 bits of data (corresponding to the 8 in 1 Gig x 8). Since the DDR4 prefetch width is 8n, an access takes out 8 columns of data, or 64 bits. So each row has 128 of 64 bits, which is the source of the 128 x 64 in the 65536 x 128 x 64 above.
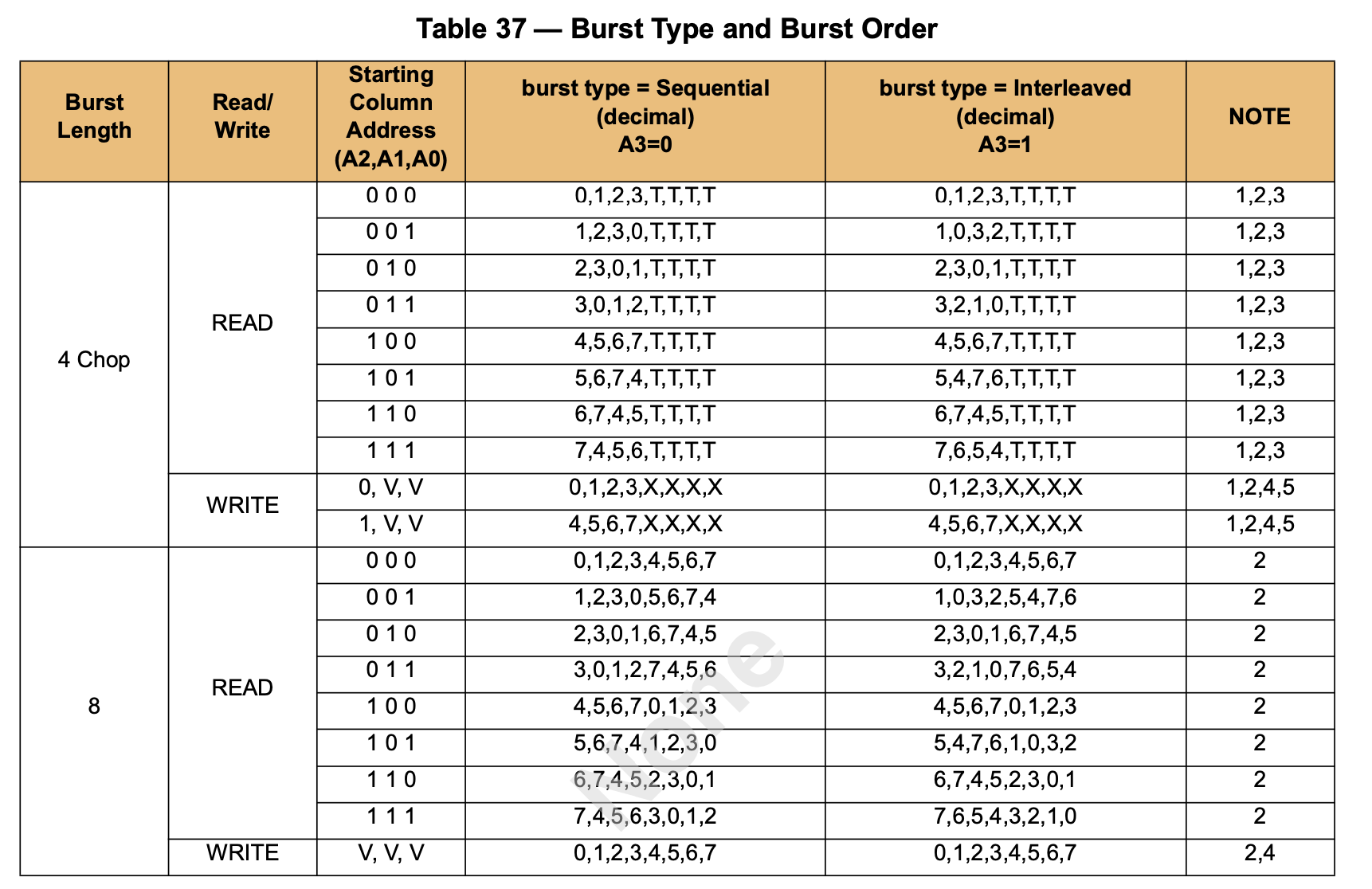
Each row contains 1024 columns, so the column address requires 10 bits. However, since the Burst Length is 8, the upper 7 bits (corresponding to 128 x 64 for 128) are used to select 8 columns, while the lower 3 bits determine the transmission order of these columns. This optimization is designed to facilitate cache refill by pre-fetching the required data:
Prefetch
SDRAM has the concept of prefetch, which is how many times the bit width of the data is fetched out in one read. For example, the 1 Gig x 8 SDRAM above has an I/O data bit width of 8 bits (see the DQ signal on the right). This is because the IO frequency of DDR4 SDRAM is very high, e.g. 3200 MT/s corresponds to an I/O clock frequency of 1600 MHz, while the actual memory array frequency is not as high. The actual memory array frequency is that high, but operates at 400 MHz, so to make up for the difference in frequency, the data is read 8 times the bit width at a time. This is reflected in the I/O, which is a single read operation to get 8 copies of data, i.e. burst length of 8, which is transferred in four clock cycles via DDR.
Interestingly, DDR4 memory modules are 64 bits wide, so a single read operation yields \(64 * 8 / 8 = 64B\) of data, which is exactly the size of the CPU cache lines.
DDR5 increases the prefetch to 16n, which is why you see much larger data rate numbers for DDR5: DDR4 prefetch is 8n, DDR5 prefetch is 16n at the same memory array frequency, so the I/O frequency is doubled and the data rate is doubled. At the same time, in order to maintain the burst size of 64 bytes, the bit width of each channel in DDR5 module is 32 bits, each memory module provides two channels.
Access Patterns
SDRAM has a special access pattern in that its memory array can only be accessed in complete rows at a time. In the previous example, a row has 8192 bits of data, but a read or write operation involves only 64 bits of data, so a read operation requires:
- the first step is to retrieve the entire row where the data is located
- in the second step, read the desired data in the row
But each bank can only take out one row at a time, so if the two reads involve different rows, then you need to:
- the first step is to take out the whole row where the data of the first read is located
- in the second step, read the desired data in the row
- step 3, put the first read row back
- step 4, take out the whole row where the data of the second read is located
- step 5, read the desired data in the row
In SDRAM terms, the first and fourth steps are called Activate, the second and fifth steps are called Read, and the third step is called Precharge.
SDRAM defines the following timing parameters that describe the timing requirements between these three operations:
- CL (CAS Latency): the time between sending a read request and outputting the first data
- RCD (ACT to internal read or write delay time): the time from Activate to the next read or write request
- RP (RRE command period): the time between sending a Precharge command and the next command
- RAS (ACT to PRE command period): the time between Activate and Precharge
- RC (ACT to ACT or REF command period): the time between Activate and the next Activate or Refresh
- RTP (Internal READ Command to PRECHARGE command delay): the time between Read and Precharge
So the above process requires the following time requirements:
- the first step, Activate, take out the first row
- the second step, Read, the time between the first and second steps should be separated by RCD, and the time to wait for CL from Read to send address to get data
- step 3, Precharge, the time between step 1 and step 3 should be separated by RAS, and the time between step 2 and step 3 should be separated by RTP
- step 4, Activate, take out the second row, the time between step 1 and step 4 should be separated by RC, and the time between step 3 and step 4 should be separated by RP
- step 5, Read, the time between step 4 and step 5 should be separated by RCD, the time to wait for CL from Read to send address to get data
Based on this process, the following conclusions can be drawn:
- accessing data with locality will have better performance, requiring only continuous Read, reducing the number of activates and precharges
- constantly accessing data from different rows will lead to a back and forth Activate, Read, Precharge cycle
- accessing the row and accessing the data in the row are divided into two phases, and both phases can use the same address signals, making the total memory capacity large
- if the access always hits the same row, the transfer rate can be close to the theoretical one, as shown in Figure 2
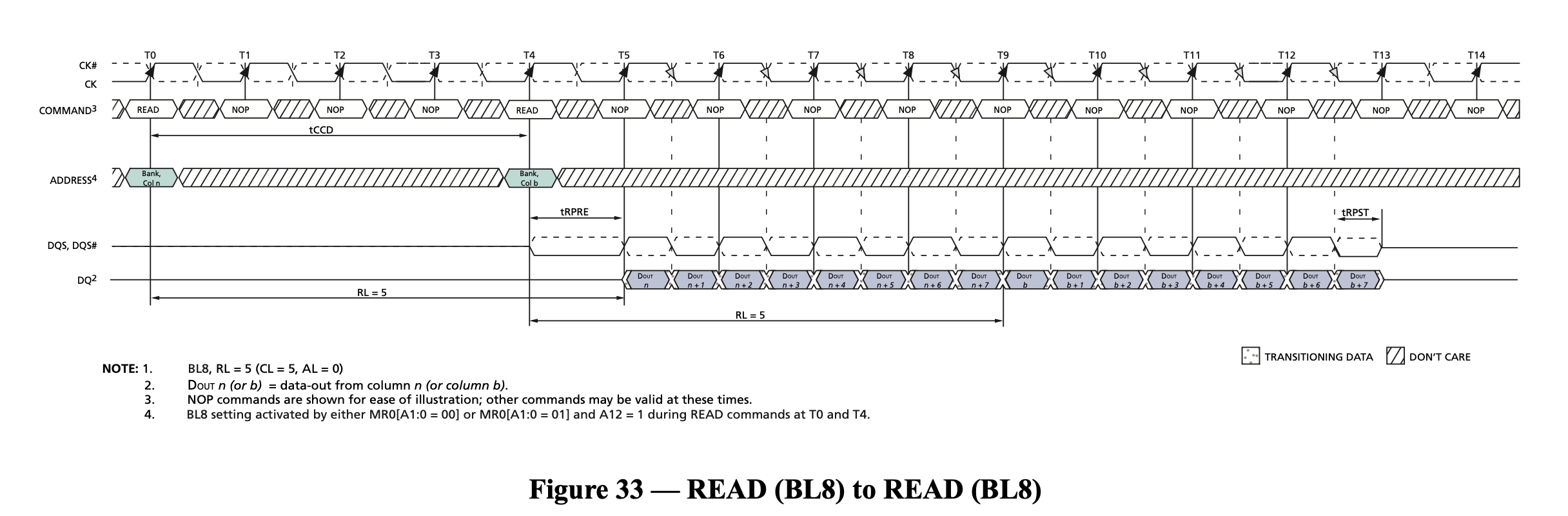
To alleviate the performance loss caused by the second point, the concept of Bank is introduced: each Bank can take out a row, so if you want to access the data in different Banks, while the first Bank is doing Activate/Precharge, the other Banks can do other operations, thus covering the performance loss caused by row misses.
Bank Group
DDR4 introduces the concept of Bank Group compared to DDR3. Quoting Is the time of page hit in the same bank group tccd_S or tccd_L?, memory array frequency is increased compared to DDR3, so a perfect sequential read cannot be achieved within the same row, i.e. two adjacent read operations need to be separated by 5 cycles, while each read transfers 4 cycles of data with a maximum utilization of 80%, see the following figure:
In order to solve this bottleneck, the difference of DDR4 in the core part is that there is an additional Global I/O gating, and each Bank Group has its own I/O gating, DM mask logic, the following draws the storage part of DDR3 and DDR4 respectively, for comparison:
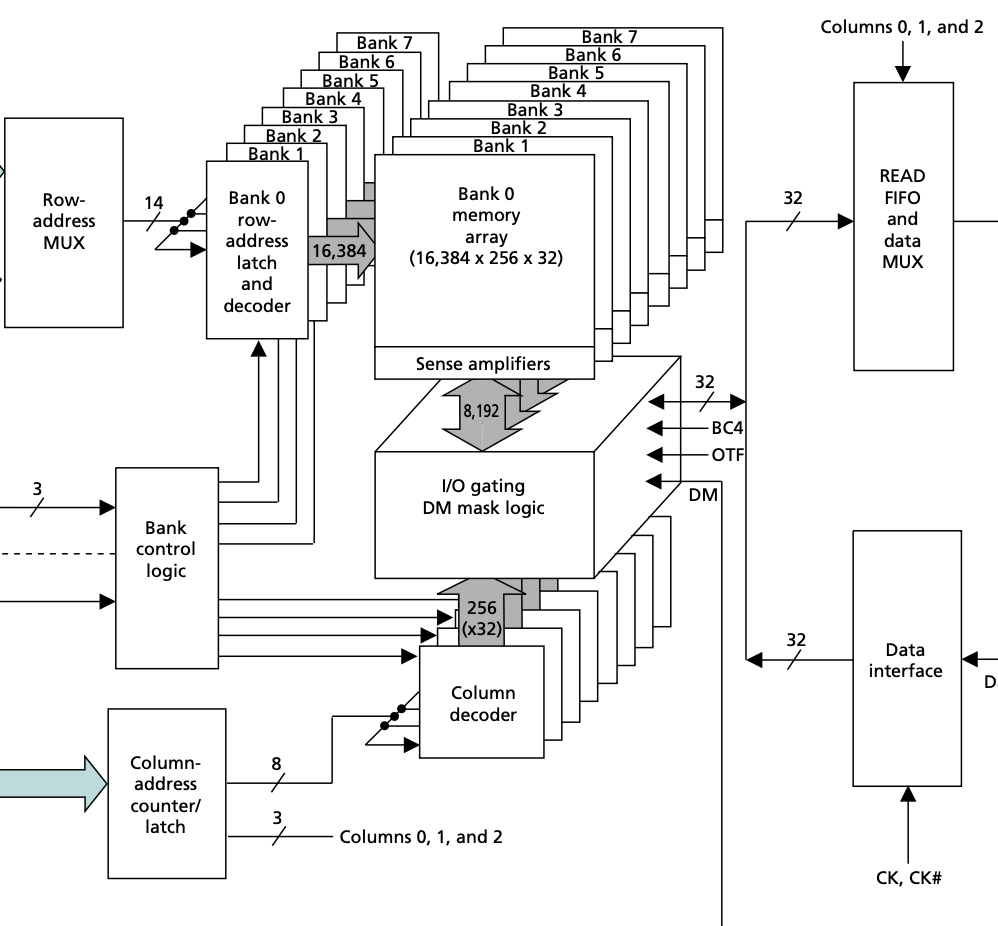
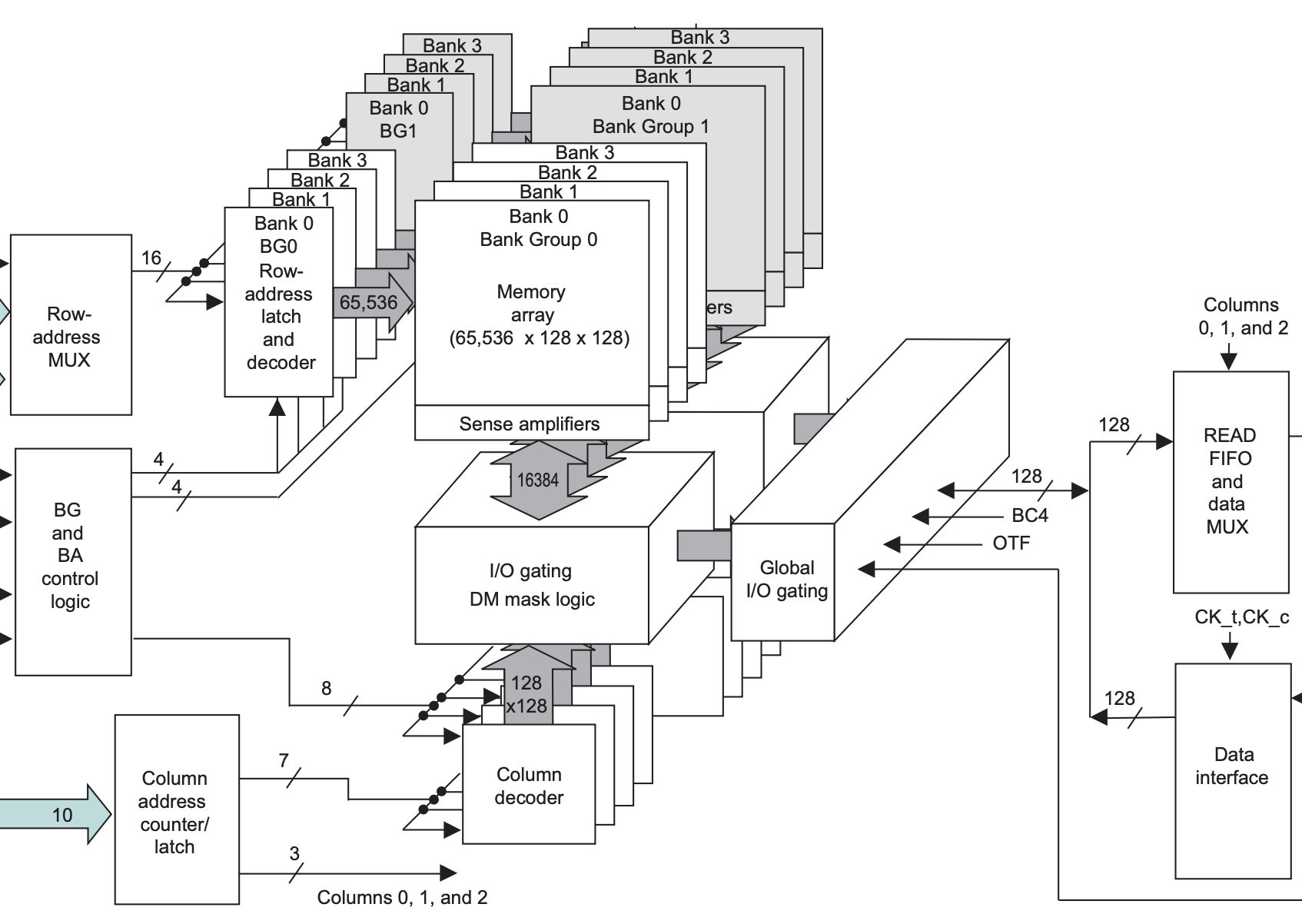
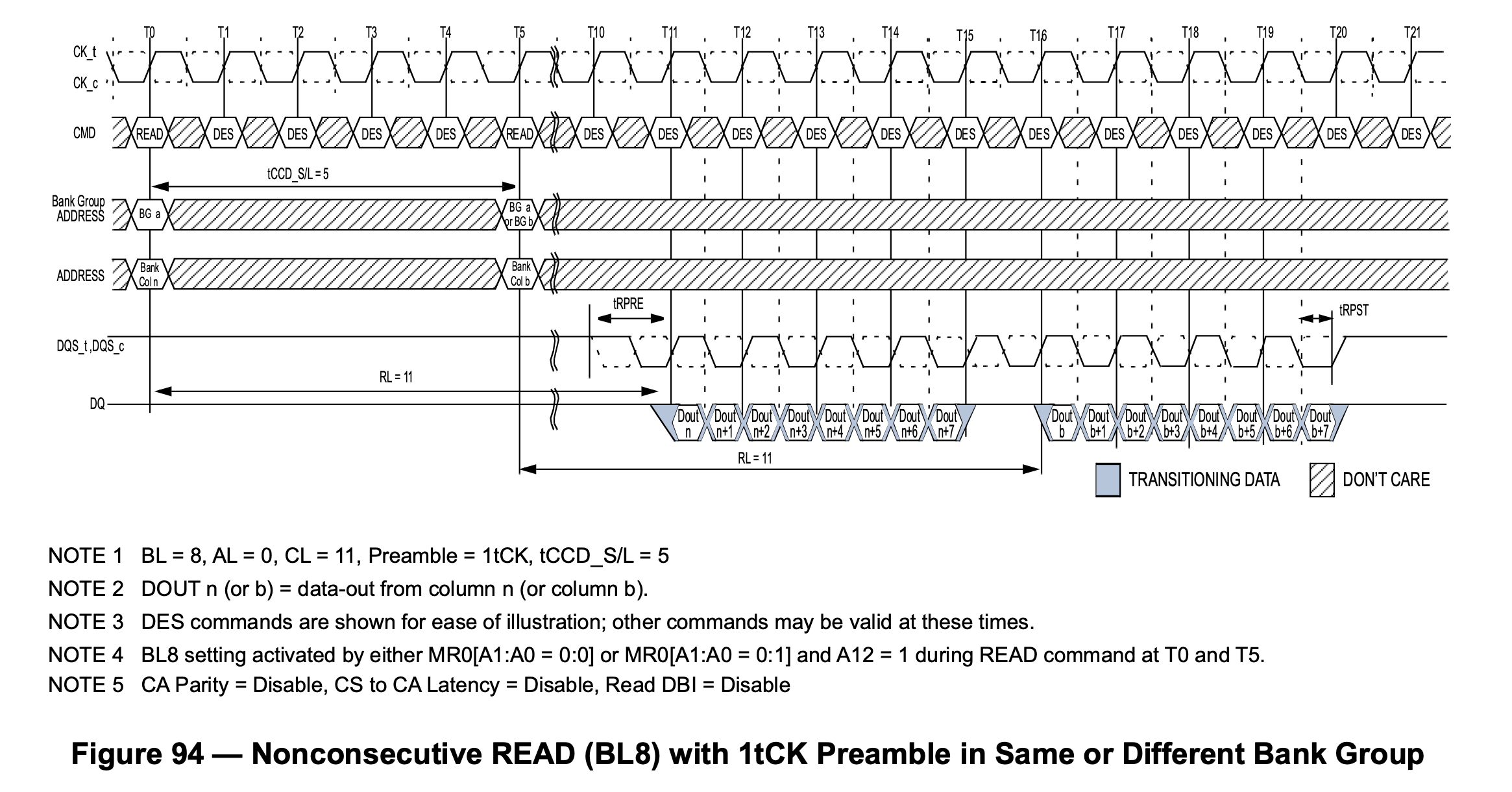
This means that DDR4 can have multiple Bank Groups reading at the same time and pipelining the output. For example, if the first Bank Group reads the data and finishes transferring it in four cycles on the I/O, immediately the second Bank Group read picks up and transfers another four cycles of data, with the following waveform:
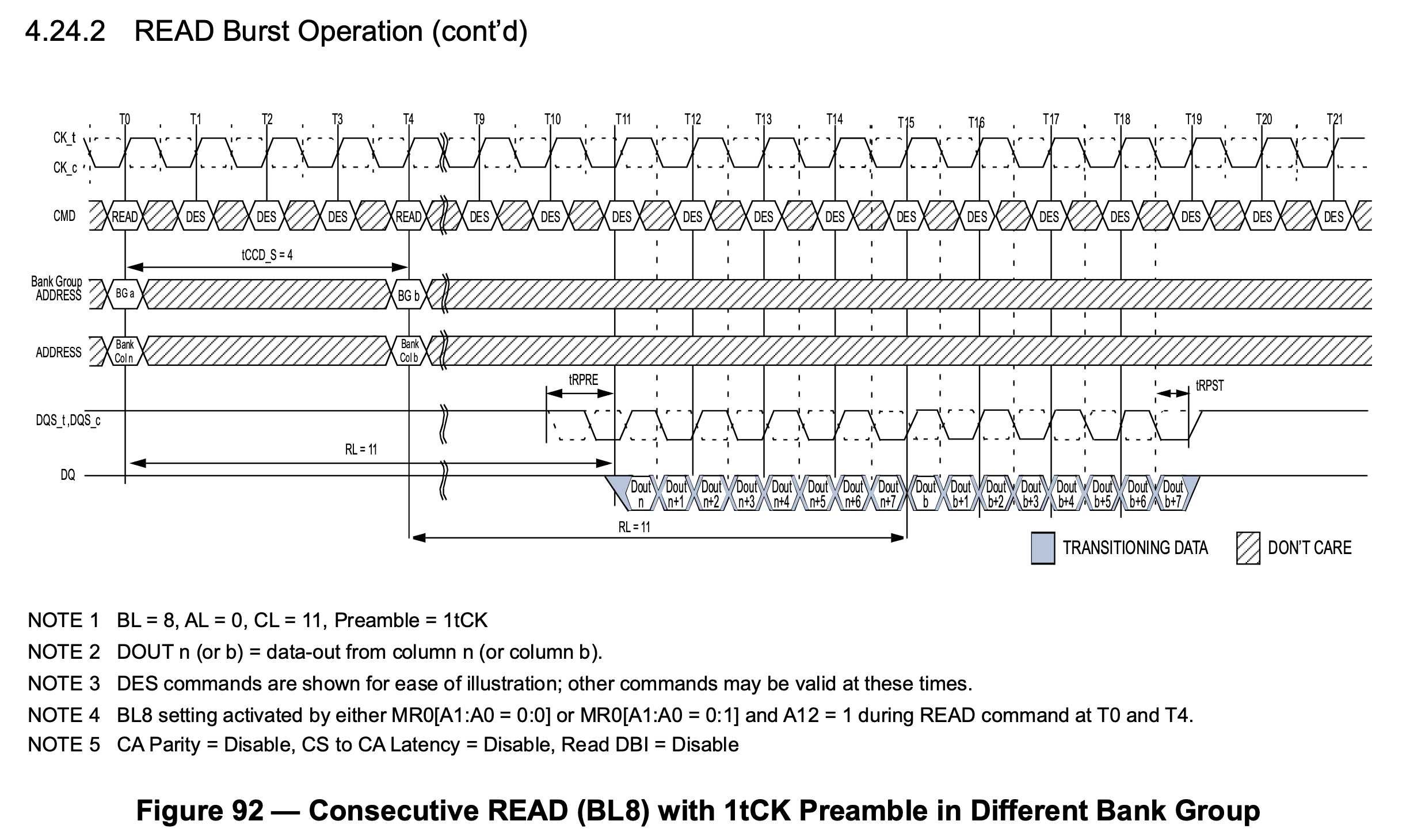
In the above figure, the first read request is initiated at time T0, the second request is initiated at time T4, T11-T15 get the data of the first request, followed by T15-T19 get the data of the second request. This solves the problem caused by the increased frequency.
Storage Hierarchy
As mentioned above, the hierarchy within DDR SDRAM, from largest to smallest, is as follows
- Bank Group: introduced in DDR4
- Bank: Each Bank has only one Row activated at the same time
- Row: Activate/Precharge unit
- Column: each Column holds n cells, n is the bit width of SDRAM
- Cell: each cell holds 1 bit of data
In fact, there are several layers outside the SDRAM:
- Channel: the number of channels of the processor's memory controller
- Module: there can be multiple memory sticks connected to the same Channel
- Rank: multiple DDR SDRAM chips are stitched together in width, one to four Ranks can be put down on a Module. these Ranks share the bus, each Rank has its own chip select signal CS_n, which is actually stitching SDRAM chips in depth
- Chip: A DDR SDRAM chip; such as a 64-bit wide Rank, is made by using 8 x8 chips stitched together across the width
As you can see, adjacent memory levels differ by a power of two, so the mapping from the memory address to these levels is an interception of different intervals in the address, each corresponding to a subscript of the level. This is why the MB and GB units of memory size are 1024-based.
If you study SDRAM memory controllers, such as MIG on Xilinx FPGA, one can find that it can be configured with different address mapping methods, e.g:
- ROW_COLUMN_BANK
- ROW_BANK_COLUMN
- BANK_ROW_COLUMN
- ROW_COLUMN_LRANK_BANK
- ROW_LRANK_COLUMN_BANK
- ROW_COLUMN_BANK_INTLV
As you can imagine, different address mapping methods will have different performance for different access modes. For sequential memory accesses, the ROW_COLUMN_BANK method is more suitable, because sequential accesses are distributed to different banks, so the performance will be better.
Take DRAMSim3 as an example: it uses a syntax similar to rochrababgco to represent the mapping from an address to various levels of DRAM addresses, from the most significant bit to the least significant bit. Using its DDR4_8Gb_x8_3200.ini configuration as an example:
ro=addr[33:18]: Row address, total of 65,536 rowsch=0: Channel address, total of 1 channelra=addr[17:17]: Rank address, total of 2 ranksba=addr[16:15]: Bank address, 4 banks per bank groupbg=addr[14:13]: Bank group address, total of 4 bank groupsco=addr[12:6]: Column address, total of 1,024 columns, with every 8 columns forming one burst
Timing Parameters
Below are the main timing parameters for DDR4:
- tCCD_S: CAS to CAS delay short, the delay between CAS commands to different Bank Groups, e.g., 4 cycles.
- tCCD_L: CAS to CAS delay long, the delay between CAS commands to the same Bank Group, e.g., 6 cycles.
- tRRD_S: ACT to ACT delay short, the delay between ACTIVATE commands to different Bank Groups, e.g., 4 cycles.
- tRRD_L: ACT to ACT delay long, the delay between ACTIVATE commands to the same Bank Group, e.g., 6 cycles.
- tWTR_S: Write to Read short, the delay from the completion of a WRITE (last data written) to a READ command to a different Bank Group.
- tWTR_L: Write to Read long, the delay from the completion of a WRITE (last data written) to a READ command to the same Bank Group.
- tREFI: Refresh Interval, the interval at which the memory controller needs to send REFRESH commands.
- tRFC: Refresh Cycle, the minimum interval between a REFRESH and REFRESH/ACTIVATE commands.
- tFAW: Four Activate Window, the maximum number of ACTIVATE commands that can be sent within a continuous tFAW period. In other words, the i-th ACTIVATE and the (i+4)-th ACTIVATE must be at least tFAW apart.
- tRP: Precharge, the delay from sending a PRECHARGE command to the next command to the same Bank.
- tRTP: Read to Precharge, the minimum interval between a READ and a PRECHARGE command to the same Bank.
- tRAS: RAS active time, the minimum interval between an ACTIVATE and a PRECHARGE command to the same Bank.
- tRCD: Activate to Read/Write delay, the minimum interval between an ACTIVATE and a READ/WRITE command to the same Bank.
- tRC: Activate to Activate/Precharge delay, the minimum interval between an ACTIVATE and the next ACTIVATE/PRECHARGE command to the same Bank.
- CL: CAS Latency, used to calculate Read Latency.
- CWL: CAS Write Latency, used to calculate Write Latency.
- AL: Additive Latency, used to calculate Read Latency.
- RL: Read Latency.
- WL: Write Latency.
Additive Latency may seem like an artificial increase in command delay, but in reality, the memory controller also sends commands AL cycles in advance. For example, after setting AL, ACT and READ commands can be sent consecutively, with the READ command delayed by AL to meet the tRCD timing requirement, while freeing up the command bus.
Interface
The following pins are drawn for DDR3 and DDR4:
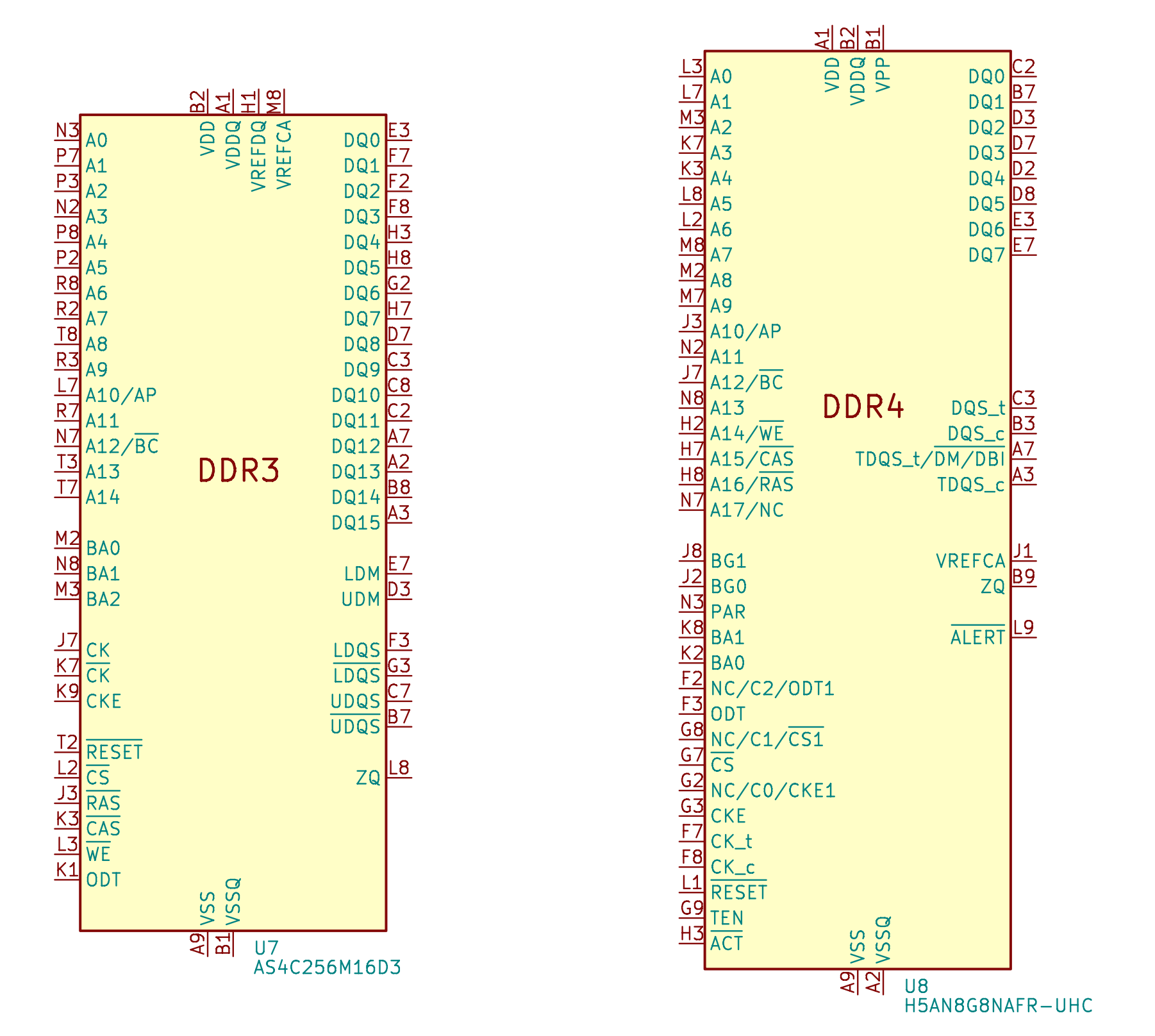
The differences between DDR3 and DDR4:
- address signal: DDR3 has A0-A14, DDR4 has A0-A17, where A14-A16 are multiplexed pins
- DDR4 introduces Bank Group, so there are extra pins BA0-BA1.
- RAS_n, CAS_n and WE_n in DDR3 are reused as A14-A16 in DDR4
- DDR4 adds an additional ACT_n control signal
Topology
In order to obtain a larger bit width, many SDRAM chips can be seen on the memory modules, which are stitched together by width to form a 64-bit data width. At this point, from the PCB alignment point of view, the data lines are directly connected to each SDRAM chip and can be connected relatively easily; however, other signals, such as address and control signals, need to be connected to all SDRAM chips, and it is difficult to ensure equal distances to each SDRAM chip while ensuring signal integrity in the confined space.
Fly-by topology
Therefore, the address and control signals are actually connected in series (Fly-by-topology), which is the connection on the right in the following figure:
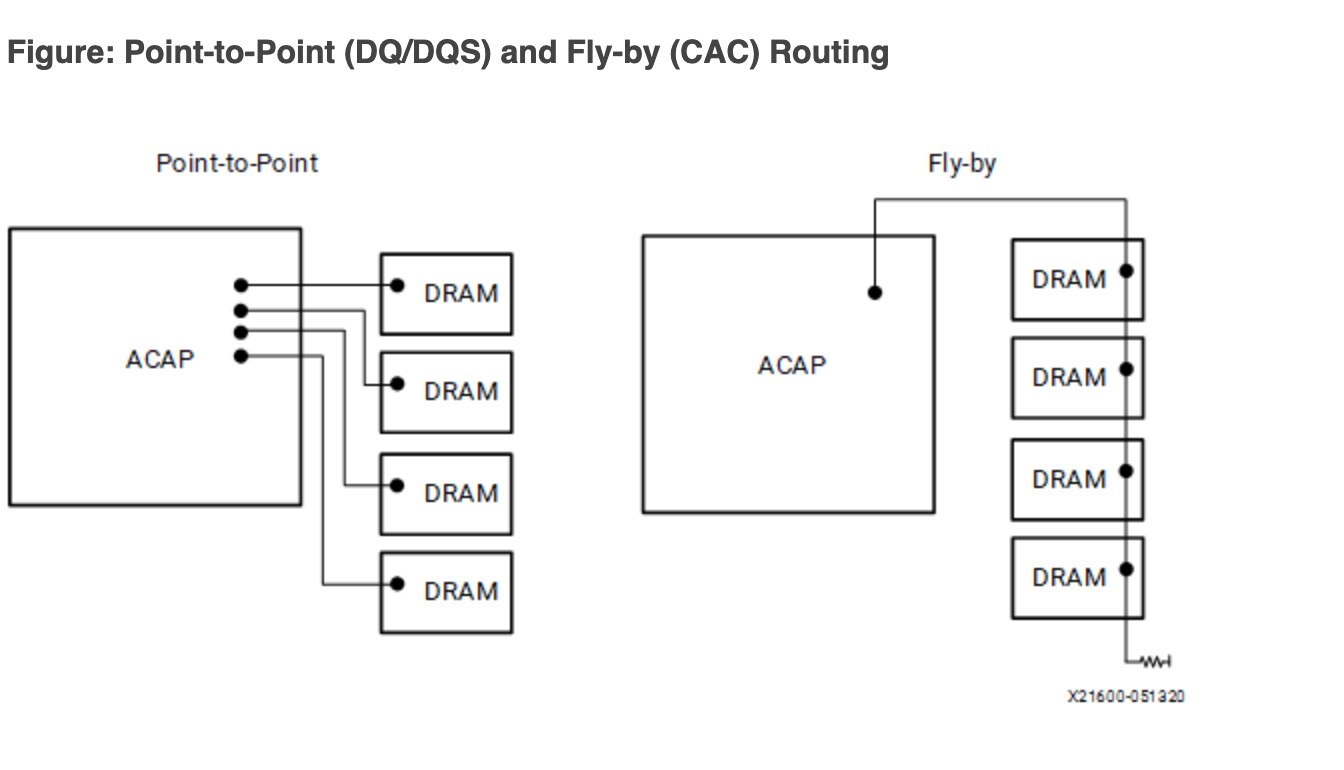
But the data signals (DQ, DQS and DM) are still connected point-to-point to the SDRAM in parallel (left side of the figure above). This presents a problem: with different SDRAM chips, the data and clock deviations are different, and the data may arrive at about the same time, but the clock has an increasing delay:
In order for SDRAMs at different locations to see the same waveform, a variable delay needs to be added to the data signal on the memory controller side, and this delay needs to be calibrated to know what it is.
Clam-shell topology
In addition to Fly-by topology, Clam-shell topology may be used in some scenarios to save PCB area. Clam-shell is actually a visual representation of having SDRAM chips on both the front and back sides of the PCB:
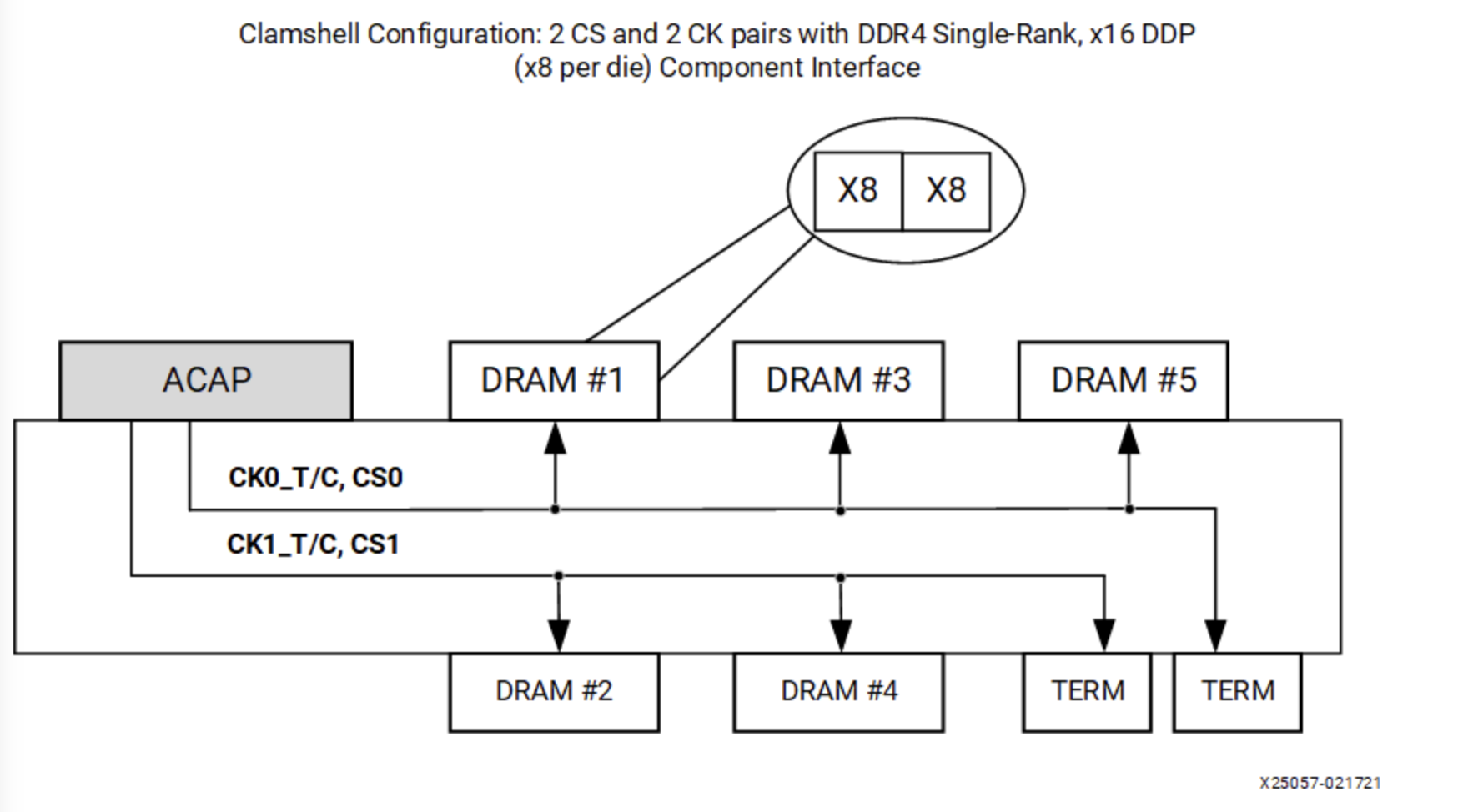
This design makes use of the space on the back of the PCB, but it also brings new problems: intuitively, if both chips are placed on the front of the PCB, it is easier to connect them if the pin order is close to the same, and there will not be many crossings. However, if one is on the front and the other on the back, the pin order is reversed and it is more difficult to connect.
The solution is to modify the order of the pins and swap the functions of some pins to make the alignment simpler:
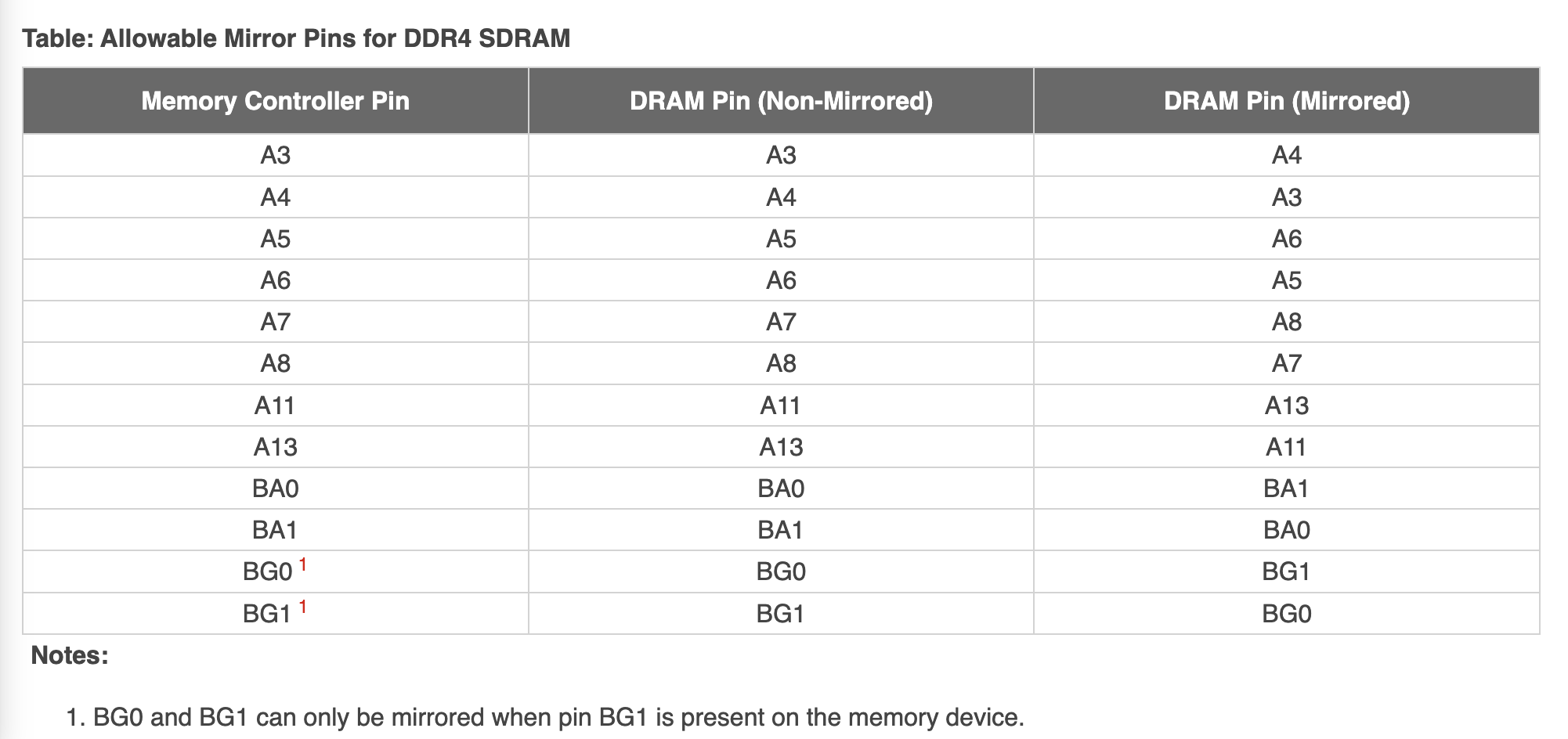
The table deliberately selects pins to swap that do not affect special functions, making most functions, even with swapped pins, work properly. For example, if the Row address is swapped by a few bits, it does not affect reading or writing data, although the physical storage place is changed. However, for Mode Register Set operations, the memory controller must swap the order of the bits itself and swap them back when connecting on the PCB to ensure the correct result on the SDRAM side.
In addition, Clam-shell Topology has one cs_n chip select signal on the front and one on the back, but this is different from Dual Rank: Dual Rank has the same number of DRAM chips on both front and back, sharing the address, data and control signals, and only one side of the DRAM chips on the bus is in use at the same time, which has the advantage of doubling the memory capacity. The advantage is that the memory capacity is doubled and the two ranks can mask each other's latency; while the two cs_n of Clam Shell Topology are designed to assign either front or back side to Mode Register Set operations, while most of the rest of the operations can work on both front and back sides at the same time because their data signals are not shared.
Calibration
SDRAM calibration, or SDRAM training, mainly consists of the following steps:
- Write Leveling
- Read Leveling
Write Leveling
Write Leveling addresses the problem of inconsistent latency caused by Fly-by-Topology, which causes SDRAM to see the wrong signal. Specifically, the purpose of Write Leveling is to synchronize the DQS signal received by the SDRAM chip with the CK signal:
To achieve this, the idea is to continuously adjust the delay of the DQS output, observe the behavior at different delays, and find a delay value that synchronizes the DQS with the CK. In order to do Write Leveling with the memory controller, the SDRAM can enter a Write Leveling Mode, where the SDRAM samples the CK on the rising edge of the DQS and then outputs the result to the DQ. In this case, different DQS delays will result in different results:
In the above figure, for both delay0 and delay1, DQS samples the negative half-cycle of CK, while for delay2 and delay3, DQS samples the positive half-cycle of CK, so if you want to synchronize DQS with CK, you should set the DQS delay between delay1 and delay2.
To summarize the Write Leveling algorithm:
- Set the SDRAM to Write Leveling mode, where the SDRAM will use DQS for CK and output the result to DQ
- The controller enumerates the latency of DQS, reads out the DQ results for each DQS latency, and gets a 0-1 string, for example:
00111111111111111111110000, that is, as the latency increases, it samples to 0, then to 1, and finally to 0 again - find a DQS delay that causes the DQ to change from 0 to 1, then the DQS will be synchronized with the CK according to this delayed output
- Set the SDRAM to end Write Leveling mode
This process is performed separately for each DQS signal. The following is an example of litex's SDRAM calibration code to implement a simplified process in C code:
Read Leveling
In the Write Leveling stage, the synchronization of signals at SDRAM is solved. However, for read operations, data is sent from SDRAM to the controller, and the time of arrival of different data to the controller may be different, so it is also necessary to calibrate the read operation.
To determine if the read data is correct, the practice is to first write known data and then read it out. If the read data is exactly the same as the written data, then the read operation can be performed correctly.
The implementation is similar to Write Leveling in that it enumerates the delays, performs some operations, and observes the output at each delay:
- write data (or use SDRAM's function of generating a fixed pattern output)
- set the latency to loop from 0
- at each latency setting, read out the data and compare the read results with the previously written data
- count which delay conditions, the read data is accurate. accurate is recorded as 1, inaccurate is recorded as 0
- find the accurate range of 1, and take the midpoint as the final calibration result
Note that here is no longer to find the place of 0-1 change. Write Leveling to find 0-1 change is to synchronize, synchronization is exactly the place of 0-1 change; while the purpose of Read Leveling is to read out the correct data. It is known that there is a continuous delay interval, where it can read out the correct data. Even if the interval is shifted due to changes in temperature and other conditions, it will still work because enough margin is retained by taking the midpoint of the interval. The step of taking the midpoint is also called Read Centering.
HBM
HBM is short for High Bandwidth Memory, and its technology is also based on SDRAM, so it is placed here for comparison with DDR SDRAM.
HBM stacks multiple SDRAMs, provides multiple channels and increases the bit width compared to the pDDR SDRAM. For example Micron HBM with ECC, stacks 4/8 layers of DRAM, provides 8 channels, each with a 128-bit data width. At 3200 MT/s, the maximum data transfer rate of an HBM chip is:
So a single HBM has the transfer rate of 16 traditional DDR SDRAMs, thanks to 8 channels and double the bit width. Each channel has a bit width of 128 bits, so it can be thought of as two 64-bit SDRAMs in parallel, either as one 128-bit SDRAM or, in Pseudo Channel mode, as two SDRAMs that share address and command signals.
Of course, the high bandwidth of HBM comes at the cost of a large number of pins. According to the HBM3 JESD238A standard, each channel requires 120 pins, for a total of 16 channels (HBM2 has 8 channels, 128 bits per channel; HBM3 has 16 channels, 64 bits per channel), plus the remaining 52 pins, which adds up to 1972 pins. So the connection to the processor is generally made on the Silicon Interposer, rather than the traditional PCB routing:
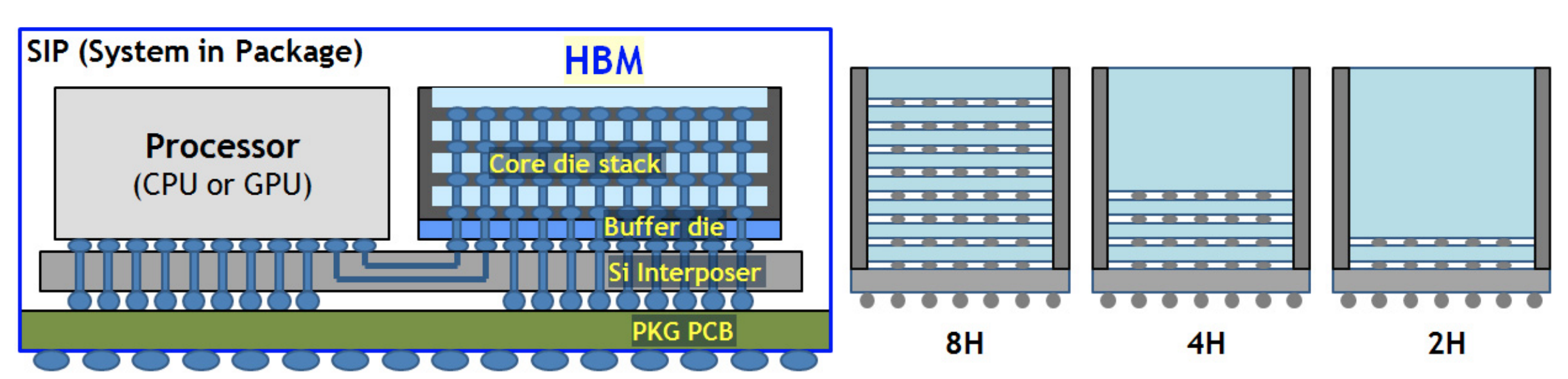
So in the HBM3 standard, the pin is described as a microbump. HBM can be understood figuratively as taking the memory modules that were originally inserted into the motherboard and disassembling them, keeping only the chips, stacking them vertically and turning them into an HBM Die, which is then tightly connected to the CPU. But on the other hand, the density goes up, and the price gets more expensive. The scalability also went down, as you couldn't place as many HBM dies on the motherboard as you could with DDR SDRAM.
The following is an analysis of the memory bandwidth of some typical systems with HBM:
Xilinx's Virtex Ultrascale Plus HBM FPGA provides a bandwidth of \(1800 \mathrm{(MT/s)} * 128 \mathrm{(bits/transfer)} * 8 \mathrm{(Channels)} = 230.4 \mathrm{(GB/s)}\). If two HBMs are used, that's 460.8 GB/s. Exposed to the FPGA logic are 16 256-bit AXI3 ports with an AXI frequency of 450 MHz and a memory frequency of 900 MHz. As you can see, each AXI3 corresponds to a pseudo channel of HBM. Each pseudo channel is 64 bits, but the AXI port is 256 bits. This is because going from 450MHz to 900MHz at the same rate, plus DDR, equates to a quadrupling of the frequency, so the bit width has to be quadrupled from 64 bits to 256 bits accordingly.
The 40GB PCIe version of the A100 graphics card uses five 8 GBs of HBM memory running at 1215 MHz, so the memory bandwidth is \(1215 \mathrm{(MHz)} * 2 \mathrm{(DDR)} * 8 \mathrm{(channels)} * 128 \mathrm{(bits/ transfer)} / 8 \mathrm{(bits/byte)} * 5 \mathrm{(HBM)} = 1555 \mathrm{(GB/s)}\), which matches the Datasheet. The Memory bus width in the A100 Datasheet is actually calculated by adding up all the channel bit widths: \(128 \mathrm{(bits/transfer)} * 8 \mathrm{(channels)} * 5 \mathrm{(stacks)} = 5120 \mathrm{(bits)}\).
The 80GB PCIe version of the A100 graphics card upgrades HBM2 to HBM2e, and the memory clock frequency is upgraded to 1512 MHz, so the memory bandwidth is \(1512 \mathrm{(MHz)} * 2 \mathrm{(DDR)} * 8 \mathrm{(channels)} * 128 \mathrm{( bits/transfer)} / 8 \mathrm{(bits/byte)} * 5 \mathrm{(HBM)} = 1935 \mathrm{(GB/s)}\), which coincides with Datasheet.
The 80GB SXM5 version of the H100 graphics card upgrades HBM to HBM3, and the memory capacity remains the same at 80GB, but the clock frequency is increased to 2619 MHz, at which point the memory bandwidth is \(2619 \mathrm{(MHz)} * 2 \mathrm{(DDR)} * 8 \mathrm{(channels)} * 128 \ mathrm{(bits/transfer)} / 8 \mathrm{(bits/byte)} * 5 \mathrm{(HBM)} = 3352 \mathrm{(GB/s)}\).
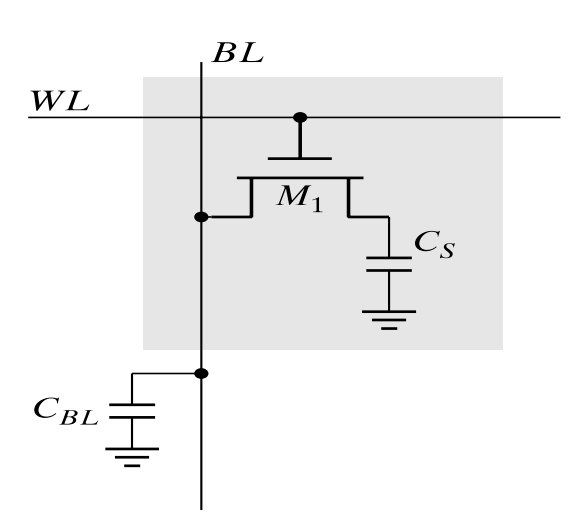
DRAM Cell
Data in DRAM is stored in capacitors. The internal structure of a typical 1T DRAM Cell is as follows:
Comparison of DDR variants
A comparison of DDR, LPDDR, GDDR and HBM is given below:
| DDR4 | DDR5 | LPDDR4 | LPDDR5 | GDDR5 | GDDR6 | HBM2 | |
|---|---|---|---|---|---|---|---|
| Channels | 1 | 2 | 2 | 2 | 2 | 2 | 8 |
| Bits per Channel | 64 | 32 | 16 | 16/32 | 16 | 16 | 128 |
| Data rate (MT/s) | 3200 | 5600 | 4266 | 6400 | 9000 | 24000 | 2400 |
| Bandwidth (GB/s) | 25.6 GB/s | 44.8 GB/s | 17.1 GB/s | 25.6 GB/s | 36 GB/s | 96 GB/s | 307 GB/s |
Data rates are based on the highest performance available:
- DDR4: Micron 3200 MT/s
- DDR5: Micron 5600 MT/s
- LPDDR4: Samsung 4266 MT/s
- LPDDR5: Samsung 6400 MT/s
- GDDR5: Samsung 9000 MT/s
- GDDR6: Samsung 24000 MT/s
- HBM2: Samsung 2400 MT/s
- HBM2E: Micron 3200 MT/s
UDIMM/RDIMM/LRDIMM
Specifically for DIMMs, there are different types:
- UDIMM (Unbuffered DIMM): No additional register buffering
- RDIMM (Registered DIMM): Register buffering for address, command, and clock signals, but not for data signals
- LRDIMM (Load Reduced DIMM): Based on RDIMM, it also adds register buffering for data signals
- CUDIMM (Clock Unbuffered DIMM): Adds a clock driver (CKD) on the DIMM, targeting higher frequencies
- SODIMM (Small Outline DIMM): Commonly used in laptops, smaller footprint
- CSODIMM (Clocked Small Outline DIMM): Adds a clock driver (CKD) on SODIMM, for higher frequencies
As the number of registers increases, latency also increases, but it allows for higher frequencies and greater capacity. To achieve even higher frequencies, a CKD must be introduced to ensure the quality of the clock signal at high frequencies.
DDR5 DFE
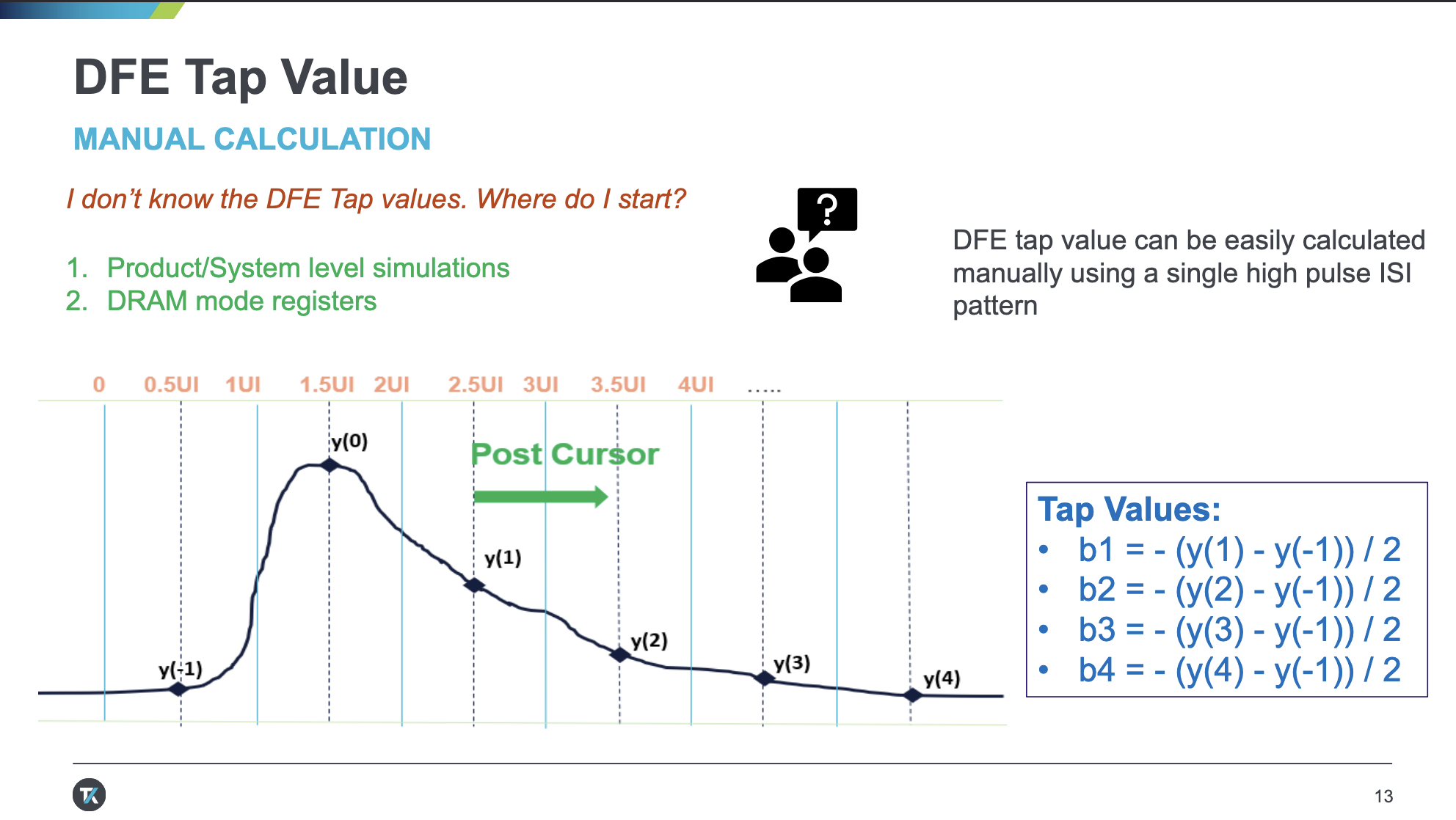
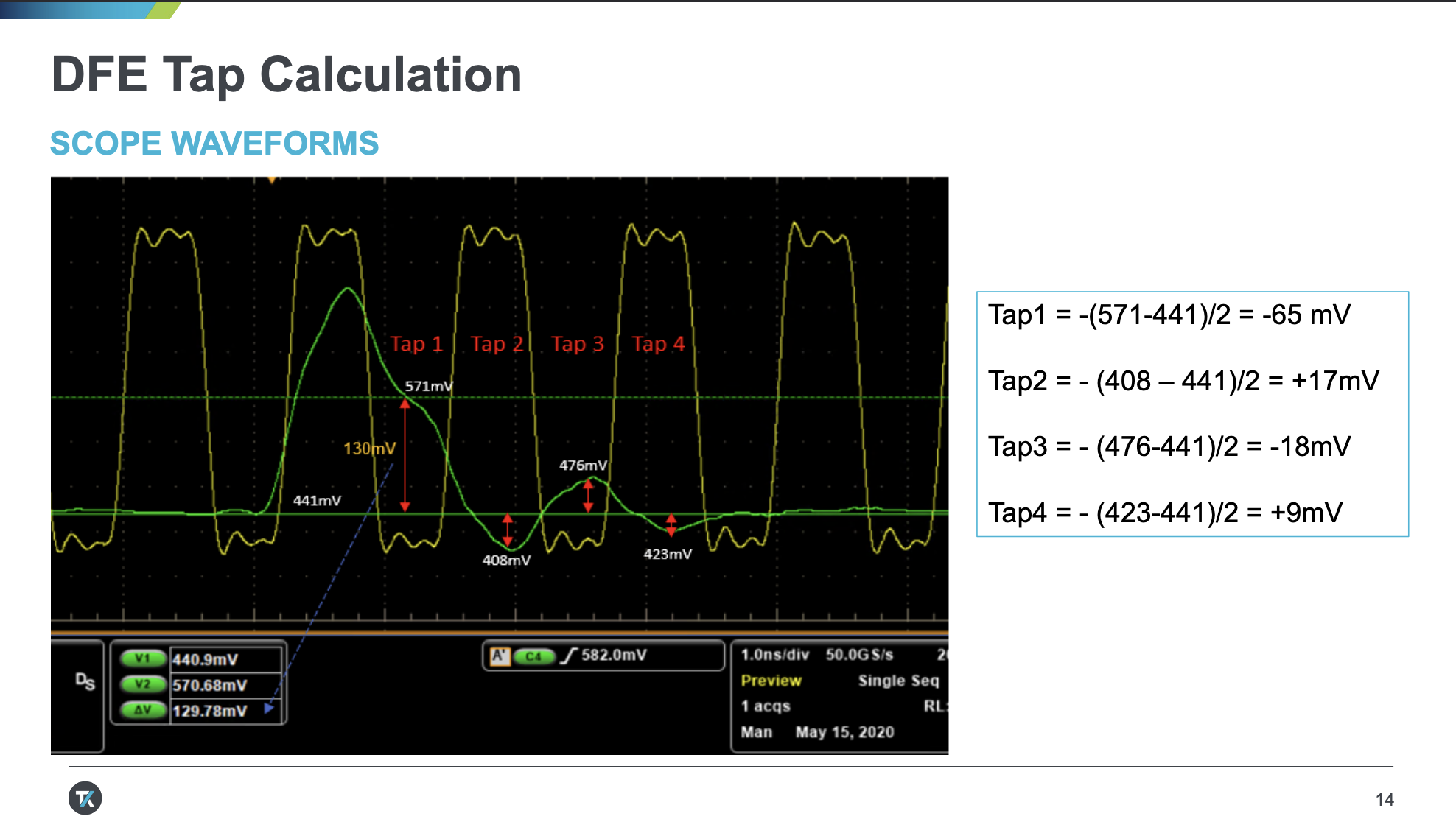
DDR5 introduces DFE (Decision Feedback Equalization) to enhance signal integrity. For details about DFE, refer to the introduction in Signal Processing.
DDR5 supports a 4-Tap DFE, meaning it accounts for interference caused by the four most recent symbols on the current symbol, corresponding to four coefficients. To measure these four coefficients, during training, a pulse is first transmitted, and its response is observed. By continuously adjusting the coefficients, the interference imposed on subsequent symbols is mitigated.
Related Reading
- DDR4 Bank Groups in Embedded Applications
- DDR4 Tutorial - Understanding the Basics
- DDR5/4/3/2: How Memory Density and Speed Increased with each Generation of DDR
- DDR5 vs DDR4 DRAM – All the Advantages & Design Challenges
- Understanding DDR3 Write Leveling and Read Leveling
- Will HBM replace DDR and become Computer Memory?
Acknowledgement
The English version is kindly translated with the help of DeepL Translator and DeepSeek.